





The Rugby World Cup is starting! As a big fan of the French rugby team I can’t help but wonder if France is finally going to win the World Cup. As a data scientist, I also wondered if it was possible for me to use data science and machine learning techniques to predict the winner of the World Cup.

Update: This blog post was originally published on September 18th, just before the beginning of the Rugby World Cup 2015. It’s now up to date with semi-final and final World Cup predictions. You can find the newest additions to this study at the end of this blog post
Léo Dreyfus-Schmidt, another data scientist at Dataiku, already wrote a blog post about sports analytics and used the studio to play around with the data from the Tour de France. Today I want to focus on using the Studio’s predictive modeling features to satisfy my love for sports and data!
Of course, there are a lot of predictions made in the sports world. So what I was focusing on while building my predictive model was: can I beat the bookmakers? Is my model good enough to allow me to leave my job and spend the rest of my life betting on sports results? Let’s find out!
Data collection
The first step of any Data Science project is to collect data to base the model on. Thanks to open source datasets, it was pretty straightforward to collect data from past games and teams' general statistics. With Dataiku DSS it was very easy to check the consistency of the data, especially by playing around with processors such as the filters:
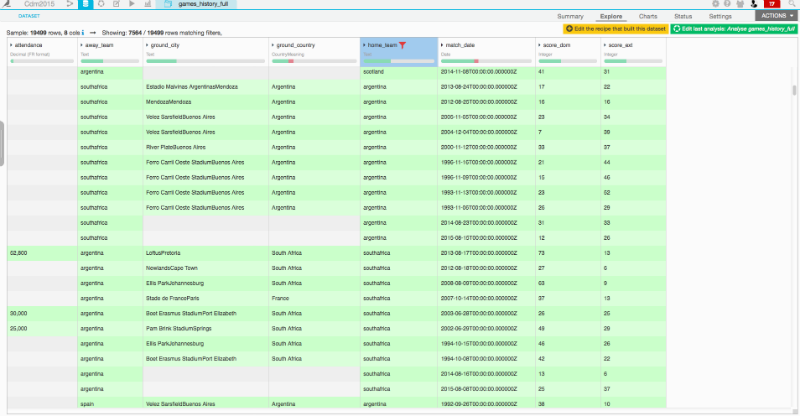 Our main dataset
Our main dataset
After a bit of data cleaning, I ended up with the following datasets:
- The history of the games (7564 games),
- individual stats for each team (number of games, longest winning streak, etc.)
- and, of course, a smaller dataset containing the calendar of the world cup.
At that point, it was very easy to perform preprocessing on it using Dataiku DSS’s visual and code recipes. These allow us to stack, join and transform datasets, and work seamlessly across different technologies.
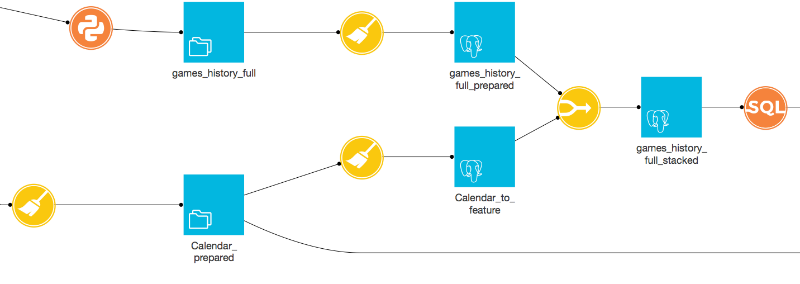 Mixing technologies using DSS
Mixing technologies using DSS
Once the data was finally cleaned, I could start the fun part of any data science project: The feature engineering part!
I predicted the result of a game as a two-class classification problem. Indeed, the outcome of a game can be seen as a target value: 0 if Team 1 loses or 1 if it wins. For analytical purposes I decided to focus on the output probability of each class for each World Cup game.
Developing the bookmaker
I mostly used Python scripts to compute the different features. The tricky part of this job is to be very careful not to add bias in the training dataset. For example you don’t want to take into account the number of games won since the creation of rugby... So I decided to only keep games after 1980 so that my games dataset contains about 5000 games.
Most of my features consist of historical scored points, as well as weighted version, a series of wins or losses, information about whether the team was playing at home or not… For this first approach I only considered team features and not the players that composed the team.
Once my features were built, I used Dataiku DSS to create a machine learning model to predict the winner of each game. In Dataiku DSS, developing a learning algorithm is easy as 1-2-3. You select the features you want to keep just by ticking a box and then you only have to choose the algorithm that's best suited.
Results
I chose to go with a random forest (of course!). After deploying my model on my World Cup dataset, I got the following results for each groups' games:
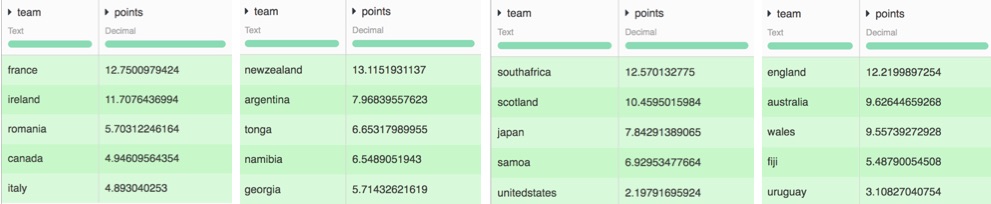
We can then look at the results for each team individually. For instance, let’s focus on the first game of France, England and New-Zealand's first games. I looked at the probability of a win for each game and compared it to prediction made by famous bookmakers.
And this is what I found:
- Probability of France winning against Italy : 88,1% (vs bookmaker: 90,9%)
- Probability of England winning against Fiji : 88,0% (vs bookmaker: 93,3%)
- New-Zealand winning against Argentina : 94,3% (vs bookmaker: 98%)
One important thing to keep in mind is that most of my model's features directly depend on a team’s recent performances. That’s why, in order to get the ranking of the groups, I had to assume that all games take place at the same time.
O and, one last cool thing to do with Dataiku DSS
To get more accurate results I be re-running my flow after each day of the cup. This is really easy to do with Dataiku DSS’s task scheduler:
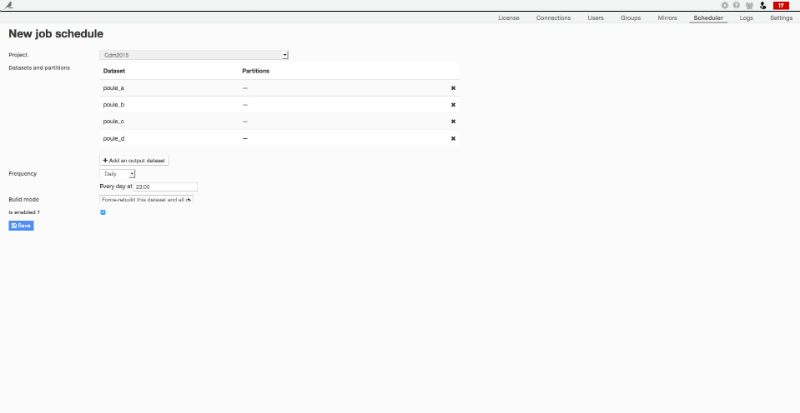
Thanks to this feature, I will have updated predictions updated every morning, without having to do anything!
Let’s hope France will do better than my predictions expect them to do :) If you want to be updated with my new predictions you can email me.
Update: Who will win the semi-finals and final game?
After having some fun trying to predict the results of the groups for the world cup we are going to see who is the most likely to win the World Cup using the same model as before. Of course the data of each of our semi-finalist was updated given their previous results (group and quarter final).
-
The first semi-final is between New-Zealand and South-Africa. Given their amazing performance against France, New Zealand seems to be the favorite of this game. My model cannot agree more with this giving New Zealand a probability to win of 63%.
-
Concerning the other game between Australia and Argentina, Australia can be considered as the logical winner of the game despite the recent results of Argentina. For this semi-final, my model predicts Australia to win with a probability of 68%.
If these two predictions happen to be right, we will have a classic final between New Zealand and Australia. Then my model is (probably too) sure that New Zealand will win with a probability of 76% and keep the trophy!

