





This blog was written by our friends at STATWORX, a consulting and development company for data science, machine learning, and AI based in Frankfurt and Zurich. They support their customers from data strategy to the development and implementation of data projects to the upskilling of their employees through a wide range of training courses.
"Data science is just about building models." This is a statement that we hear a lot. Well, this is absolutely not the case in data science nowadays. Besides model training, data scientists need to solve more tasks — from data loading to model training and ending with model monitoring and logging — which leads to many new challenges. In many of these steps, other teams are involved besides just data science. The illustration below gives an overview of the main challenges of managing a successful data science project.
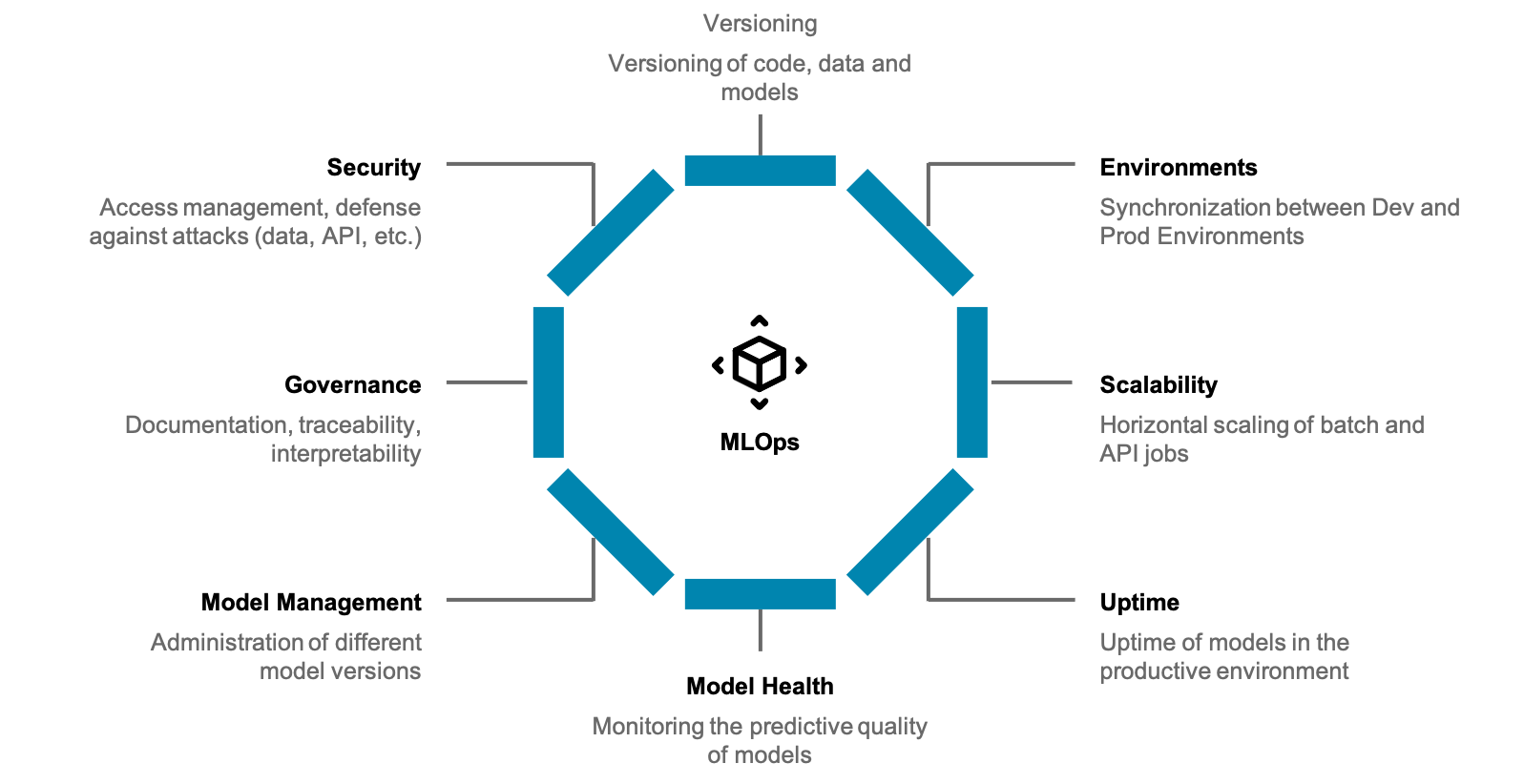
What Is MLOps?
As you can see, the path from "just building a model" to successfully building a data science product is difficult, but MLOps is here to help you. Roughly said, MLOps covers techniques and tools to manage and streamline these processes. Some are already well known from other IT projects such as code versioning and CI/CD, but others like data and model versioning are data science-specific issues that need to be solved.
The following graph shows some of the central aspects of MLOps.
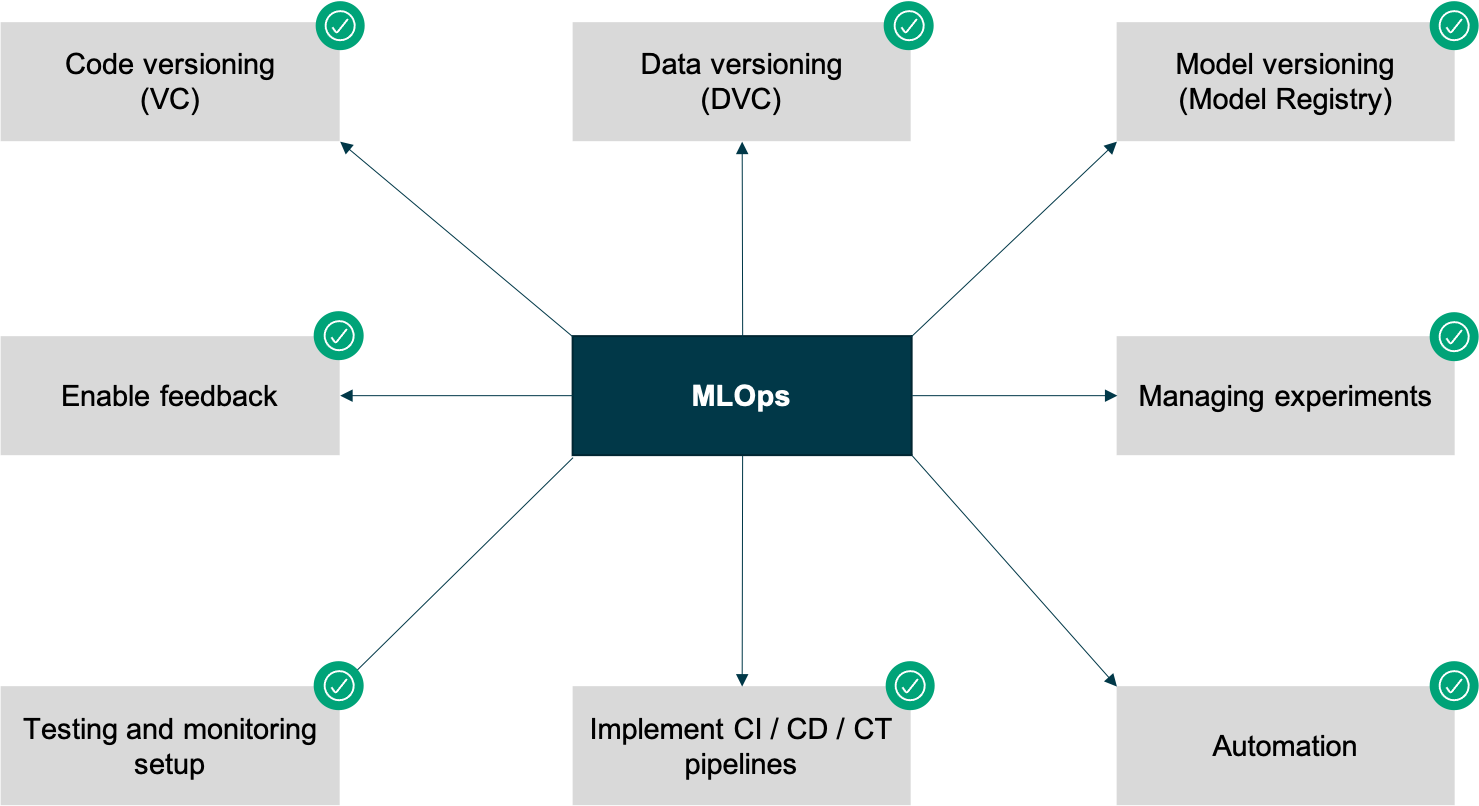
What Are the Benefits of Using MLOps?
That looks like a lot of work, right? Well, that's not really the case. The following section shows five reasons why you should use MLOps for your projects and data science applications and why you will also save time in the long run. Using MLOps:
1. Leads to shorter release cycles.
Since it is strongly related to DevOps, MLOps utilizes concepts such as implementing CI/CD pipelines and end-to-end lifecycle management. These concepts enable teams to test frequently without extensive test documentation and to deploy new releases with confidence.
2. Enables versioning code, data, and parameters.
You want to rerun an analysis with new data, but you do not know what code you used? Replication of experiments and analyses is a typical problem in data science projects because data science does not only consist of code but is also heavily dependent on data. MLOps solves this by not only versioning code but also the used data and model parameters.
3. Reduces costs with automated retraining.
Frequently retraining a model is essential to keep a model up to date, but manually checking the results leads to much overhead. Using automated techniques to discover model drift and data input drifts helps to reduce costs. Once implemented, one can self-confidently train and deploy new models frequently without worrying about odd model predictions.
4. Boosts productivity by automating manual labor.
Although it has some setup costs, MLOps increases the productivity in a project heavily. Running analyses manually or pushing the same buttons frequently is time-consuming and unsatisfying for every data scientist. When using MLOps, data scientists can focus on the fun part of data science — building models!
5. Combines multiple advantages that lead to a better product.
In the end, all that matters is that the organization has efficient and functioning data science products. Due to the benefits mentioned above (e.g., the ability to include feedback in the model and the automatization of repeating tasks), the team can reduce manual work, focus on more important aspects of their work and, in the long run, build the best product possible for the customer.
How to Implement MLOps in Dataiku
Dataiku offers many possibilities to implement the above-mentioned concepts. However, since explaining all options in detail would be beyond the scope of this article, I would like to present the tools for automatization and monitoring of models and data in Dataiku. Both tools were heavily used in my latest project at STATWORX, where we had to orchestrate complicated data pipelines and model monitoring was a legal necessity.
For automatization, Dataiku offers the concepts of scenarios. Scenarios are a set of actions that are triggered manually or after predefined conditions are satisfied. The significant advantage of scenarios is their flexibility. You can use them to run Python recipes, to trigger and run jobs for data preparation automatically, or to retrain models.
Additionally, the triggers to start a job can be time-based, dependent on dataset changes, or individually specified using Python code. A report of a scenario run result can be sent via mail or directly to a Slack channel. This function is handy in situations where you only want to be informed if problems emerge. Since you can define when a run should fail, it is possible to report model deviations, missing data, or other technical issues. To summarize, scenarios are a key feature for MLOps in Dataiku because of their orchestration and reporting abilities.
Another highly useful function in Dataiku is "Metrics & Checks." Consider the case of daily data batches that require daily model retraining. Monitoring the data and the models could be accomplished by using the "Metrics & Checks" function. "Metrics" are measurements of items in a dataset, managed folders, or models. For example, one could define a metric that calculates the maximum of a column or the accuracy of a model. They can be defined via Python functions, or one can use predefined metrics offered by Dataiku. After defining the metrics, only the implementation of checks is needed to test new data batches and model results automatically. "Checks" test if a metric satisfies a condition. This feature enables many possibilities to check data and models and, due to the Python integration, one is not bound to predefined metrics.
Looking Ahead
Building and managing data science products is challenging due to the interdependencies between data, code, models, and the complexity of the modern data science workflow. Adopting MLOps facilitates this task by offering tools and concepts that boost the productivity of the data science team. Due to the many features offered by Dataiku the mentioned concepts are easy to implement which leads to projects in which models are built and value is generated.