




{kind=link}
The retail industry has been data centric for a while. With the rise of loyalty programs and digital touchpoints, retailers have been able to collect more and more data about their customers over time, opening up the ability to create better personalized marketing offers and promotions.
*Note: This blog post contains screen shots from an older version of Dataiku, though all the functionality described still exists. Watch the on-demand demo to take a look at the latest release of Dataiku in action.
I was pretty excited to read that our partner Vertica recently added machine learning capabilities to its database . As Massively Parallel Processing (MPP) systems are fairly frequent in the retail world, it is a good occasion to try building the kind of application described above with a best-of-breed technology combined with Dataiku!
So What Did I Build?
I built a predictive application managed by Dataiku and running entirely on top of Vertica. This is a end-to-end data workflow starting from raw data acquisition to training a machine learning model, aiming at predicting whether or not a customer is going to make a purchase in a specific product category:
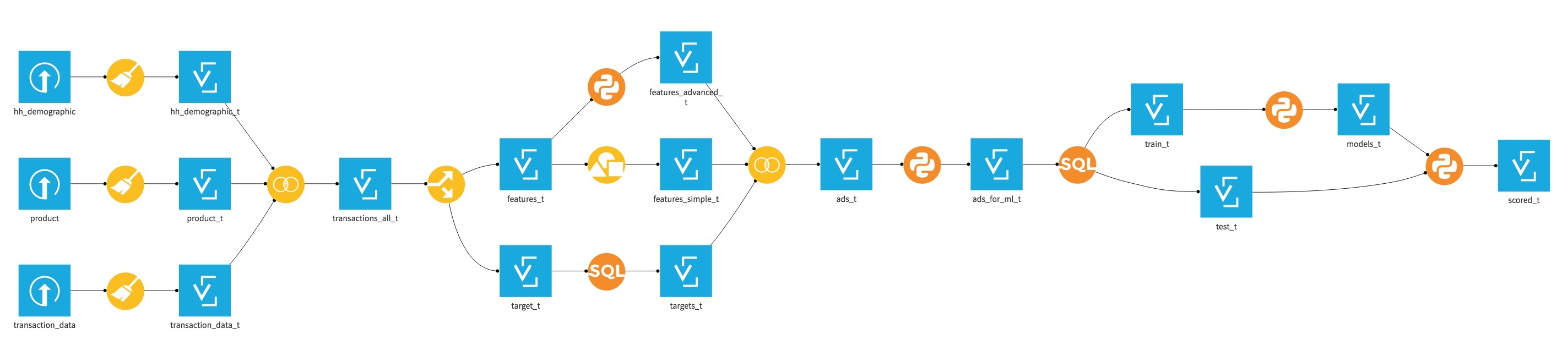
The Supporting Data
The data is provided by dunnhumby, a leading customer science company providing data and insights from shoppers across the globe. These are typical datasets from the retail industry:
-
A file storing two years of transactions with information about customers, products, time, store, and amount
-
A file storing demographics about the customers
-
A file storing product attributes: product hierarchy, packaging, etc.
The Data Science Process
1. Data Ingestion
As we are going to use Vertica both for storing and processing our data, the very first step is, of course, to push the data into Vertica. That's not rocket science with Dataiku: just create the Dataiku datasets from your raw data files, make them look good using a visual data preparation script if you wish, create a new output dataset stored in Vertica, and run your recipe. That's it. Your data is in Vertica. No coding, no SQL, no worries about how to move data around or how to handle schemas and data types: Dataiku does it all automatically for you. Great, isn't it ?
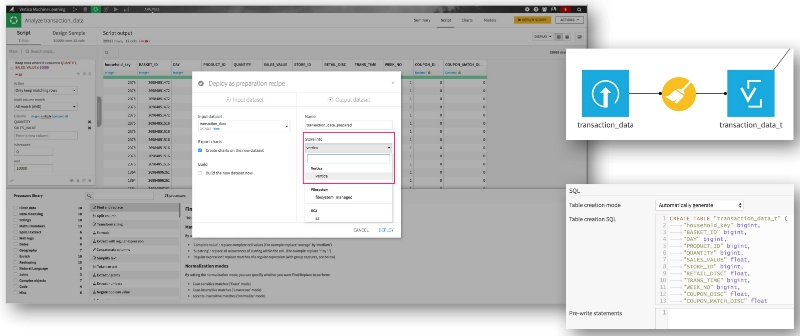
2. Data Preparation
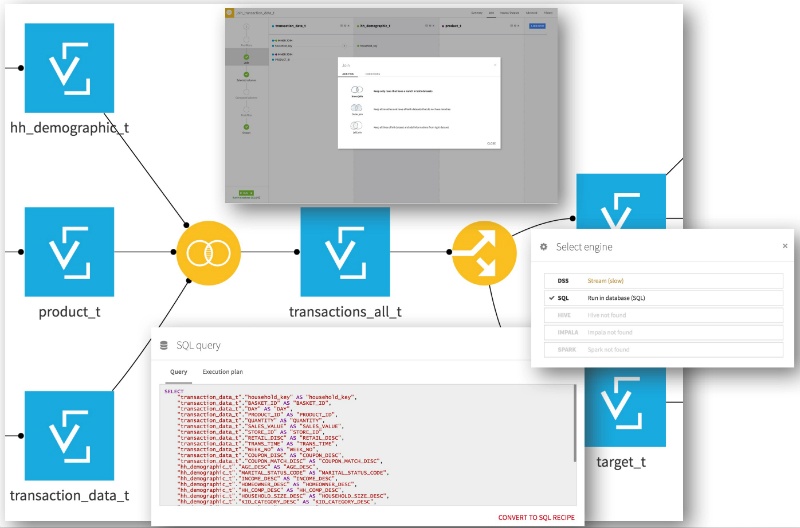
The files are disparate and have unnecessary data. With Dataiku, we can easily join, filter, and split datasets using visual recipes, all with no need to code. So what do we do now?
- We first merge the three initial datasets (transactions, products, and customers) all together to get a holistic view of the purchase behavior (we can do this with a join recipe).
- Then we split the newly created datasets into two using a split recipe: one part will be used to create the features or variables for our predictive model based on historical transaction data, and the other one will be used to create the labels, a simple new column indicating whether or not the person will purchase specific products in coming weeks.
3. Features Engineering
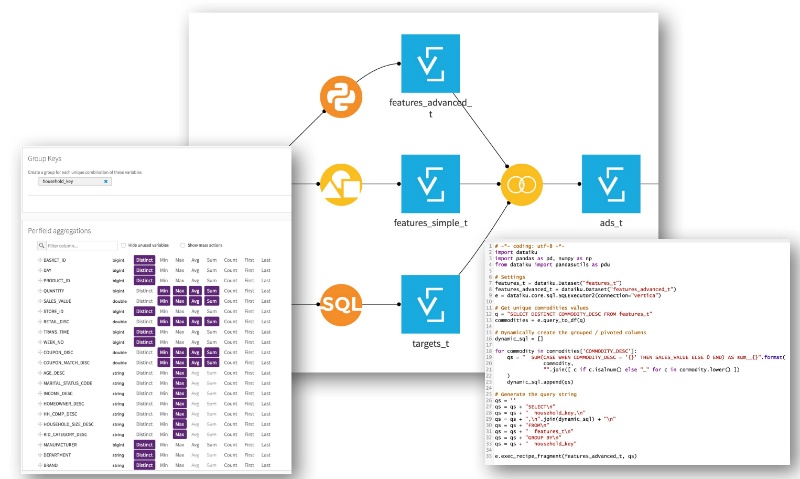
The data is still too raw to be used by machine learning algorithms directly. We need to switch from the detailed transactional view to an analytical view where the data will be aggregated to form a large set of attributes (or features, also known as variables) describing each customer. This step - known as feature engineering - is crucial and one of the most difficult when creating a machine learning model.
Technically speaking, when working with an SQL database, this will be essentially a combination of group by / pivot operations. Fortunately enough, with Dataiku you can either use visual grouping recipes to generate your SQL statements or programmatically create much more complex queries using helper Python functions.
So let's move ahead and generate this aggregated dataset (which ends up with more than 340 columns!) by combining simple counts-based features and the money spent for each type of product:
4. Data Preprocessing for Machine Learning
We're getting closer to our machine learning model. There is just one remaining step: many ML algorithm implementations expect numeric-only features with no missing values. This is unfortunately very uncommon in practice, as we often need to deal with not-so-clean and mixed data types. So in this step, we are going to impute missing values with a sensible value (averages) - even if this is always questionable- and transform each categorical (text) feature into a set of "dummy" variables (if a feature has n possible values, we will create n-1 new columns filled with 0/1 depending on the absence/presence of the value). Again, Dataiku helps automate this process by offering the ability to dynamically generate the corresponding SQL statements.
5. Model Creation
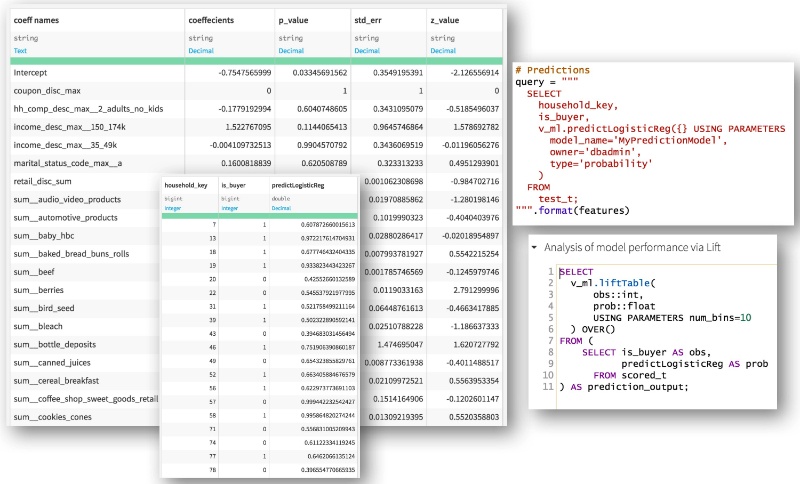
We can finally do machine learning now (!) and test the new machine learning for predictive analytics functionality released with the latest 7.2.2 version of Vertica. Training, storing, and getting statistics from your machine learning model is as easy as two queries:

As we are predicting whether or not someone will buy from a specific product category, we have a classification problem (with a binary outcome), hence the choice of logistic regression, which is available out of the box for Vertica. Training the model is done entirely in-database, with no need to move data around!
6. Model Assessment and Deployment
This is our last step. Using the statistics created by Vertica, we can easily see and analyze the coefficients and associated p-values for each feature of our model. As this is a regular Dataiku dataset, you are also free to keep on building your workflow from there (for instance by doing Checks / Metrics analysis).
Vertica also provides us with a set of handy functions to assess model performances via ROC or lift curves, which can be leveraged via Dataiku SQL Notebooks. Finally, the results can also be operationalized by using the model to score new records on a regular basis, done again fully in-database.
Conclusion
This is it, we now have a functional workflow orchestrated by Dataiku and running on top of Vertica to produce the purchase predictions, even if rather simplistic.
Creating such predictive applications is much more than training machine learning algorithms, which is in fact just a fairly small amount of work in the entire process. Data preparation, features engineering, preprocessing: these are just some of the many things to do before being able to move to the real fun of machine learning.
Even it may look like a sequential process through this post, it is in practice highly iterative. Data preparation and machine learning are deeply coupled, and Dataiku offers the immense benefit to be able to create the entire data science workflow in an integrated environment with no need to go back and forth between several tools.
As big data continues to dominate and best-of-breed technologies to manage it are made available (this what we call Technoslavia at Dataiku), Dataiku offers integrations with third-party solutions to make sure they can be properly leveraged. A key feature is the ability to push down calculations and processing to underlying, high performance system such as Vertica, which will avoid unnecessary data movements between systems and tools (one of the plagues in the big data world).
Vertica is also perfectly suited for the kind of workloads on structured data created by Dataiku: data scientists can join, filter, group, or pivot their data without worrying about tuning the system for performance and model tables properly: it will work fast out-of-the-box. The association is powerful - Vertica as a high-performance backend to predictive applications developed with Dataiku.
Working with our ecosystem is key to us, but even more for our clients as they can fully leverage their technological investments by creating high-value predictive applications more efficiently. We strive to keep on being more and more integrated with our ecosystem, but also to develop our partnerships with system integrators and consulting companies that can implement end-to-end data solutions on top of our technologies. So if you are interested in learning more, connect with me on LinkedIn or ping our team at partnerships@dataiku.com!