




Now that every company out there is doing artificial intelligence (AI) - or at least claims to be - it’s becoming more and more clear that it’s way too easy to fall into a few simple traps that can discredit any well-intentioned efforts. With trust becoming a big topic in the field of AI for 2019, it’s time to be prudent about approaching machine learning-powered initiatives smartly. Here are some of the top AI pitfalls and how to address them.

{kind=link}
AI Pitfall #1: Working With Bad Quality Data
By far the number one reason that AI efforts fall flat is because of a lack of trust or lack of quality (or both) in the data. Most commonly, poor-quality data is rooted in swaths of missing data. But data quality can also be a problem in the sense that people in the company could use it without context on what exactly the data is - that is, where it comes from or what it means. This quickly leads to problematic data projects for obvious reasons.
Bad quality data really becomes a problem when there is confidence in the company’s data (that is, that it’s accurate and high-quality) but there shouldn’t be. It’s critical that IT teams validate (and continue to monitor) data being delivered for use by lines of business or data teams to ensure that it is accurate. The onus falls also on the users of the data to ensure they understand what exactly they are using and ask questions about any doubts in quality or accuracy.

AI Pitfall #2: Fake AI
Today, AI often is equated solely with automation. But are we still stuck at only appearances instead of what automation really is? Is anyone really doing AI? There are certainly some signs that the market for machine-based intelligence is still in its infancy, especially in terms of its understanding by the general public. Indeed, there is a great risk for a modern-day mechanical turk situation.
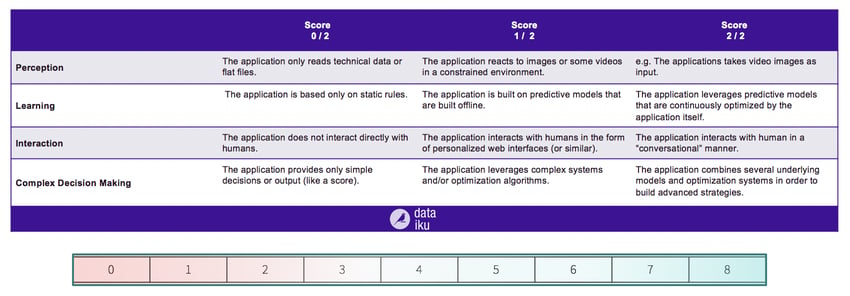
In looking at the AI scorecard, it’s true that today lots of companies are only doing “Immature AI” - that is, they are operating at Level 1. But there is an everything-is-AI-trend these days that would lead some to believe that Level 1 is enough to be able to say “yes, we’re doing AI.” The risk here is that businesses stop there because they’re already “doing” AI. So while Level 1 execution is a good first step, the trend toward setting sights and goals on this level of execution is a dangerous one — beware of getting to Immature AI and then stopping there.
AI Pitfall #3: Lack of Interpretability
As machine learning advances and becomes more complex (and especially when employing deep learning), outputs become increasingly more difficult for humans to explain. So interpretable machine learning is the idea that humans can - and should - understand, at some level, the decisions being made by algorithms.
At the end of the day, people (customers) and government (regulations) should be enough to make anyone who works on the development of ML models and systems care about ML interpretability. But there are still some skeptics that say only those in very highly regulated industries should have to be concerned with it. Yet in fact, everyone should care about ML interpretability, because at the end of the day, it builds better models - understanding and trusting models and their results is a hallmark of good science in general. And additional analysis to help understand decisions is just another check to ensure that models are sound and performing the way that they should be.
AI Pitfall #4: Blind Trust
An extension of the idea of interpretability, it is blind trust in the output of models that has recently gotten some big companies in trouble with AI that is sexist (looking at you, Amazon) or racist, to point out just a few horrifying examples. Really knowing why a model does what it does can help eliminate things like bias or other undesirable patterns and behaviors.