




{kind=link}
Data scientists spend more than half of their time wrangling data. That’s down from about 70% 15 years ago but is still a lot and it is often cited as the least fun part of data science. However, it’s arguably the most important part. Now that everyone has XGBoost, TensorFlow, and low-cost public cloud infrastructure, the best way to improve a model is more data. So the question came up recently on a webinar panel, how can we use the fun part of the job — modeling — to improve data wrangling? Three ways we will explore in this article are transforming between data formats, decentralized quality assurance, and key matching.
Transforming Between Formats
Abstractly, AI and machine learning (ML) are about data transformation and reduction. One hundred and forty-some years ago, the Englishman Francis Galton measured the circumference of 700 sweet peas to determine if pea size is hereditary. Along the way he developed linear regression (not ordinary least squares or R2, which had been around a while), an ML technique that is still widely used today. Galton didn’t want 700 circumferences, he wanted a single bit: hereditary or not hereditary.
A hundred years later, database marketing became popular and today you can get 10,000 datum about every U.S. adult from products such as Experian CustomerView and Merkle M1. But analysts don’t want 10,000 datum per person, they want one number per person, such as propensity to churn or propensity to buy pet insurance. HBO’s Silicon Valley recently explained deep learning to millions of viewers as converting digital photos to a single bit:

Here are three examples of AI/ML in data wrangling to transform between data formats: PDFs, audio files, and photos.
A global food additives company had tens of thousands of PDF documents describing their current and past products, as well as those of competitors. The PDFs are useful to humans but not XGBoost or TensorFlow. They needed to extract key data about each product such as chemical composition, melting point, viscosity, and solid fat content at room temperature. They could have done that manually, hiring dozens of readers offshore, but that would have been slow, inaccurate, and expensive — three things data scientists abhor. Instead they developed an algorithm to automatically extract the data which processed all the PDFs in minutes.
The second example involves audio files. Digital twins for factories is a hot topic today, but adding digital sensors to big, old facilities can be slow, inaccurate, and expensive (as mentioned above, three things data scientists abhor) since there typically are numerous stakeholders involved, many of which lack experience with IT infrastructure. A shortcut some are using to get to a minimal viable digital twin is to add hundreds of wireless sound, vibration, and temperature sensors through a site. A temperature sensor on a pump, for example, can tell you if it’s working unusually hard, indicating that there may be a fouled pipe.
Sound sensors can detect squeals which indicate that pump bearings are failing. Sensor data can be streamed to cloud folders for processing. The factory maintenance manager, however, doesn’t want 20,000 audio files. They just want to know which pumps are likely to fail and when. Transforming thousands of audio files into a few hundred probabilities and dates is a good role for AI.
A third example uses computer vision in manufacturing quality control and is used by customers of ours in pharmaceuticals and consumer packaged goods. In fact, the AI luminary Andrew Ng has a startup in this area. The pharma company detects defects in medicine vials while the CPG company looks for mistakes in plastic packing film.
Human inspectors previously did it but are slow, inaccurate and expensive. Their accuracy fluctuates significantly by time of day, day of week, and day of the month. The AI programs they developed converted a photo to a single bit, defect or not defect, and made it available to human inspectors in real-time. Working together, inspectors and AI reduced false positives by 50% in one case and detected 98% of defects in another.
Decentralized Data Quality Assurance (QA)
IT teams have long had general-purpose QA tools that check for generic issues in tabular data like row counts, duplicate rows, and null value rates. Those are useful first steps, but something like a high null rate might be bad for some use cases and irrelevant for others. For example, it's not unusual in ML for high null rate columns to be predictive of rare events.
One size doesn’t fit all for data QA anymore. As the industry moves to data mesh architectures, data owners are distributed around the edges of the business rather than centralized in IT. Excessive cleaning can introduce bias so owners do minimal QA, allowing their data products to be used in a wide variety of use cases. Data users then do additional QA to meet their specific needs. Thus QA is decentralized and shared by data owners and users.
Suppose we’re using Merkle’s aforementioned 10,000 variables to predict customer churn, and household income turns out to be a key variable. Then a few months later, a new version of the dataset is released and, for some reason, the household income column is mostly null. Is that a quality problem worth flagging? If you’re developing household income BI charts, then it is because humans will be viewing aggregates of that column. However, if only ML algorithms are viewing it, then one column going bad, one out of 10,000 (0.01%), might not be relevant. Besides, the dataset contains 40 other variables that are highly correlated (or even collinear) with household income so if household income goes bad then one of the others — disposable income, home value, automobile value — will pick up the slack. So individual null value rates aren't too important to the churn use case. What is important is that the dataset doesn’t lose its overall ability to predict churn.
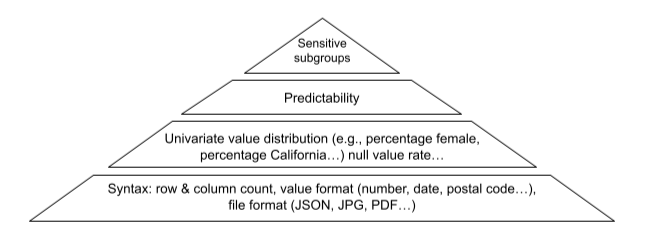
Some data science teams have taken to automatically developing simple, disposable, “mini” models of churn to quickly detect data issues, using algorithms such as Lasso regression and small, shallow random forests. Build a mini model for each new release of the dataset and alert MLOps when model accuracy deviates too much. This approach may be taken further by building mini models for sensitive customer subgroups, such as women, those with disabilities, and traditionally underserved communities, and comparing their accuracies. Here’s a hierarchy of data quality needs. At the bottom is basic syntax, and at the top are predictability and bias.
Key Matching
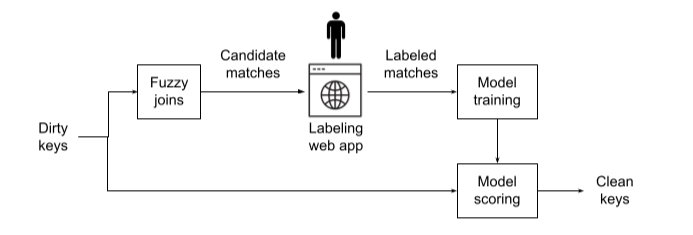
A third use of data science in data wrangling is key matching. Wouldn’t it be nice if every customer, supplier, product, and part had one and only one unique identifier (aka key) throughout an enterprise? That’s unrealistic and, even if it did happen following a multiyear master data management project, it won’t last long. My experience is that 10% of customers have five or more keys, even in a single database. And, until relatively recently, it wasn’t uncommon for retailers to have multiple product IDs across manufacturing, stores, and e-commerce. Continuous ML processes can help clean keys. The database luminary Michael Stonebraker has a startup in this area.
Dataiku has a variety of built-in “fuzzy join” functions that measure the similarity of records and can estimate whether two records are about the same entity. Damerau–Levenshtein text edit distance calculates the similarity between text and can estimate that “Dabrowski & Sons Trucking Co” and “Dabrowski and Sons Trucking Co.” may be the same supplier. Another uses geospatial distance and could decide that suppliers whose headquarters are within 200 feet of each other are the same. We can improve accuracy by combining multiple measures and setting thresholds. However, this approach is rule-based. We can do better with active learning and have a person label (aka grade) some candidate matches, and then use AI to learn a key matching algorithm.
In summary, there are many uses of AI in data wrangling including transforming unstructured data, decentralized QA on large numbers of variables, and key matching. These uses are likely to grow as AutoML improves and more datasets are integrated to improve models.