




Structured Query Language (SQL) has long been the standard for managing and querying relational databases, providing a powerful toolset for extracting insights from structured data. Large Language Models (LLMs), though, have been the talk of the town for over a year now and represent a breakthrough in natural language processing (NLP), enabling machines to understand and generate human-like text with remarkable accuracy and fluency.
The convergence of SQL and LLMs holds the promise of revolutionizing how organizations interact with and derive value from their data, and that’s part of the work that the Dataiku AI Lab team does: Build a bridge between ML research and practical business applications. This blog is a glimpse into the team’s most recent ML Research, in Practice video series with special guest Paolo Papotti, Associate Professor in the data science department at EURECOM, about how SQL and LLMs work separately and how to get the most value by using them together.

SQL and LLM Vows
Just like any wedding where two people make promises to each other in the form of vows, the same thing happens here. The first promise comes from LLMs: “I will help your users write SQL queries.” The second promise, from the SQL database, is “I will help your users benchmark data tasks” (Papicchio et al, NeurIPS 2023). Finally, there is a joint promise that they will answer the queries jointly (Saeed et al, EDBT 2024).

Semantic Parsing
If a language model is given a sentence or a question to express the semantic request, this should be translated in a SQL script, known in ML research as semantic parsing or text to SQL. This task is quite mature and is an example of natural language text to code and research shows that LLMs do very well according to benchmarks.
Notably, there’s Spider, Yale’s semantic parsing and text-to-SQL challenge, with the goal of developing natural language interfaces to cross-domain databases. It contains about 6,000 examples written by humans (with the natural language question and the corresponding expected SQL script) on 200 databases.
However, Papotti warns against these public benchmarks (or at least, treading with caution) because there are the risks of overfitting (systems optimized for queries in this dataset) and contamination (examples are on the internet). So, then, how should organizations proceed if they need to pick a model for their proprietary data? Will it work and, if so, how well?
It would be ideal to make a custom benchmark on user data, selecting a subset of models suitable for the use case — a problem for any tabular task with natural language text or tabular data. If there was a tool to do so, with proprietary data and a task to test, to automatically rank existing LLMs on.

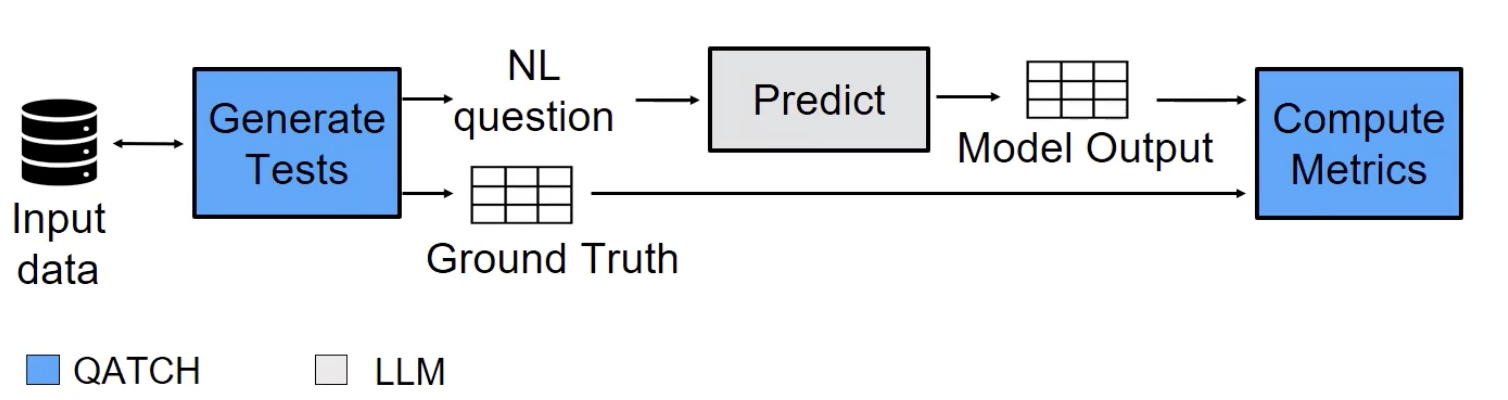
Papotti and team attempted to take on this challenge with QATCH: Query-Aided TRL Checklist. Given proprietary data and tasks (such as semantic parsing), the goal is to create a set of tests to measure the quality of LLMs on their own data. The only thing required as input is the input data as seen in the visual below:
{kind=link}
SQL to the Rescue?
In step two of the visual above, how can organizations generate “good” tests? Papotti and team created pairs of natural language questions and ground truth data directly from their table and they focused on the query complexity and simple text (i.e., no ambiguity, plain English).

When it comes to computing the metrics and evaluating on output data, Papotti and team focused on benchmarking multiple tasks (Question Answer output is data) and, with semantic parsing, organizations need to be very careful comparing SQL scripts (i.e., it is possible that SQL scripts are rather different but have the same semantics). Data comparison enables accurate metrics for semantic parsing, executing correct SQL and generated SQL on the data to compare data outputs.
Want to check out the results for the Question/Answer with ChatGPT that the team saw, as well as the results for the other tests? Did the wedding vows come true? Be sure to check out the comprehensive details on using SQL and LLMs together in the full video of the session: