




{kind=link}
Multiple steps must be taken to prepare raw data before it can be used to generate valuable insights. Together, these steps make up your data pipeline. The purpose of a data pipeline is to organize raw source data into a workflow, where it can be cleaned and used to create analytics. Keeping your data clean, in one place, and up to date is crucial for running effective MLOps. While data pipelines help you clean and prepare your data quickly and efficiently, they are not without their challenges.
Common Data Pipeline Problems
While building your data pipeline, you may come across a variety of obstacles, including:
- Missing data: Too many missing or invalid values mean that those variables won’t have any predictive power (many machine learning algorithms are not able to handle rows with missing data). Depending on the use case, it’s possible to impute (or assign) the missing values with a constant, like zero, or with the median or mean of the column. In other cases, one might choose to drop rows with missing values entirely.
- Non-standardized dates: Working with dates poses a number of data cleaning challenges. There are many date formats, different time zones, and components like “day of the week” which can be difficult to extract. A human might be able to recognize that “1/5/19”, “2019-01-05”, and “1 May, 2019” are all the same date. However, to a computer, these are just three different strings.
- Multiple fields in a single column: Sometimes you will see a lot of information in one column. You might want to separate that information into multiple columns to get the most out of your data.
- Non-unique column headers: It may happen that your dataset includes columns with the same names for different sets of information. You will want to change that to clarify what each column represents.
You’re in luck, because Dataiku has a very simple solution to each of these challenges!
Dataiku’s Solutions
Dataiku is an efficient tool for building data pipelines, especially as part of a larger Enterprise AI strategy and the operationalization of models in production. It offers a great way to clean and prepare data faster, so that it’s ready to generate valuable insights more quickly. In addition to full code options for more technical users, Dataiku offers visual recipes to accomplish the most common data transformation operations, such as cleaning, grouping, and filtering, through a pre-defined graphical user interface. The four pain points identified above can all be solved by using the Prepare recipe.
The Prepare recipe is a visual recipe in Dataiku that allows you to create data cleansing, normalization, and enrichment scripts in an interactive way. This is achieved by assembling a series of transformation steps from a library of more than 95 processors. Most processors are designed to handle one specific task, such as filtering rows, rounding numbers, extracting regular expressions, concatenating or splitting columns, and much more. 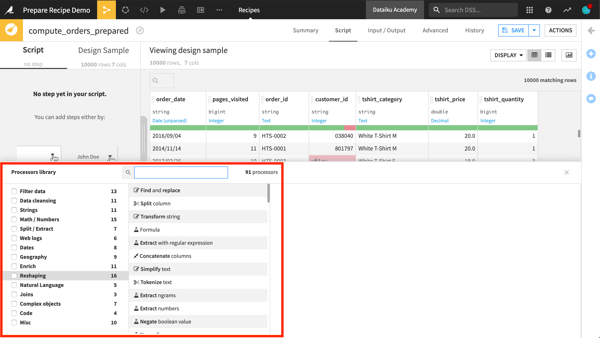
Now let’s discover four processors that can help us fix the pain points we identified.
- Missing data: Find and replace processor
With this processor, you can choose to replace all empty fields by a value, text, or any other meaning you please.
- Non-standardized dates: Parse to standard date format processor
Strings representing dates need to be parsed, so that the computer can recognize the true, unambiguous meaning of the date. When you have a column that appears to be a date, Dataiku is able to recognize it as a date.
You can open the processor library and search for the Parse date processor.
Once you have chosen the correct processor, it is just a few more clicks to select the correct settings, for example, the format of the date and the timezone.
- Multiple fields in a single column: Split column processor
You can use the Split column processor to separate information of one column into two or more columns. For example, you could split a birthdate_parsed column into a birthday_year and birthday_month to have one column for years and another for months.
- Non-unique column headers: Rename columns processor
To rename columns, whether it is because multiple columns have the same name or you simply wish to change the name, you can use the Rename column processor.
All you have to do next is select the column you wish to rename and type in the new name!
Three Prepare Recipe Shortcuts
In addition to directly adding steps to the Prepare recipe from the processor library, there are a couple shortcuts to add steps to the script that can help you clean and organize your data even faster!
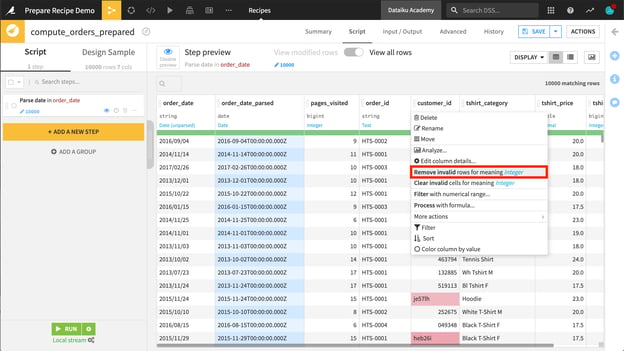
- The column context menu
In the column context menu, Dataiku will suggest steps to add based on the column’s meaning. For example, Dataiku will suggest parsing dates when it recognizes unstandardized data.
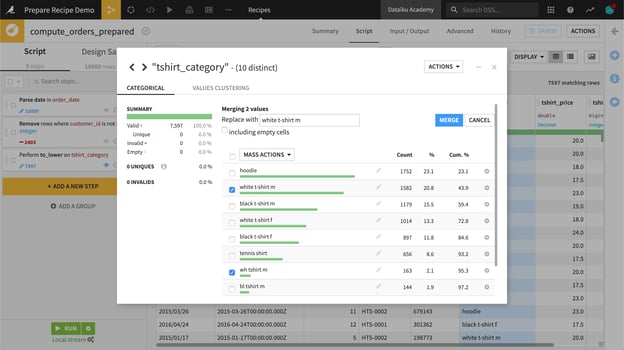
- The Analyze window
Another method to add steps to the script is through the Analyze window. Within a Prepare recipe, the Analyze window can guide data preparation, for example merging categorical values.
- Dragging columns
You can also directly drag columns to adjust their order, or switch from the Table view to the Columns view to apply certain steps to more than one column at a time.
We’re Here to Help You!
As you can see, Dataiku has a lot of tricks up its sleeves. There are numerous options to discover, so do not hesitate to ask the Dataiku Community if you need help. Now it’s your turn to build your data pipeline and master any data preparation obstacle you may face!