




{kind=link}
In order to understand the hype around Transformer NLP models and their real-world implications, it’s worth taking a step back and looking into the architecture and inner workings behind these models. In this blog post, we’ll walk you through the rise of the Transformer NLP architecture, starting by its key component — the Attention paradigm.
The Attention Mechanisms Origin Story: Machine Translation
The Attention paradigm made its grand entrance into the NLP landscape back in 2014, before the deep learning hype, and was first applied to the problem of machine translation.
Typically, a machine translation system follows a basic encoder-decoder architecture (as shown in the image below), where both the encoder and decoder are generally variants of recurrent neural networks (RNNs). To understand how a RNN works, it helps to imagine it as a succession of cells. The encoder RNN receives an input sentence and reads it one token at a time: each cell receives an input word and produces a hidden state as output, which is then fed as input to the next RNN cell, until all the words in the sentence are processed.
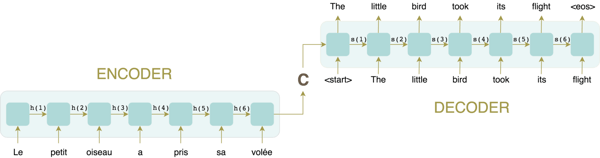
After this, the last-generated hidden state will hopefully capture the gist of all the information contained in every word of the input sentence. This vector, called the context vector, will then be fed as input to the decoder RNN, which will produce the translated sentence one word at a time.
But is it safe to reasonably assume that the context vector can retain ALL the needed information of the input sentence? What about if the sentence is, say, 50 words long? Because of the inherent sequential structure of RNNs, each input cell only produces one output hidden state vector for each word in the sentence, one by one. Due to the sequential order of word processing, it’s harder for the context vector to capture all the information contained in a sentence for long sentences with complicated dependencies between words — this is referred to as “the bottleneck problem”.
Solving the Bottleneck Problem With Attention
To address this bottleneck issue, researchers created a technique for paying attention to specific words. When translating a sentence or transcribing an audio recording, a human agent would pay special attention to the word they are presently translating or transcribing.
Neural networks can achieve this same behavior using Attention, focusing on part of a subset of the information they are given. Remember that each input RNN cell produces one hidden state vector for each input word. We can then concatenate these vectors, average them, or (even better!) weight them as to give higher importance to words — from the input sentence — that are most relevant to decode the next word (of the output sentence). This is what the Attention technique is all about.

If you want to get even more into the nitty gritty of Transformer NLP models and the Attention mechanism’s inner workings, we recommend that you read this Data From the Trenches blog post.
Towards Transformer NLP Models
As you now understand, Attention was a revolutionary idea in sequence-to-sequence systems such as translation models. Transformer NLP models are based on the Attention mechanism, taking its core idea even further: In addition to using Attention to compute representations (i.e., context vectors) out of the encoder’s hidden state vectors, why not use Attention to compute the encoder’s hidden state vectors themselves? The immediate advantage of this is getting rid of the inherent sequential structure of RNNs, which hinders the parallelization of models.
To solve the problem of parallelization, Attention boosts the speed of how fast the model can translate from one sequence to another. Thus, the main advantage of Transformer NLP models is that they are not sequential, which means that unlike RNNs, they can be more easily parallelized, and that bigger and bigger models can be trained by parallelizing the training.
What’s more, Transformer NLP models have so far displayed better performance and speed than RNN models. Due to all these factors, a lot of the NLP research in the past couple of years has been focused on Transformer NLP models, and we can expect this to translate into exciting new business use cases as well.