




{kind=link}
Working on text-based datasets is a different world than dealing with numbers. Comparisons between words are much harder, and it may be difficult to group or aggregate similar values. The new Yuzu version of Dataiku integrates tools to help you with natural language processing (NLP). This blog post presents two tips that I often use when working with text-based datasets.
*Note: This blog post shows screen shots from an older version of Dataiku. To see the latest version in action, check out the demo.
A textual input in your database is probably composed of a sequence of words. If you want to compare two inputs to check how close they are, it is difficult because:
- Words generally have different forms or inflections. A noun can be inflected for a number (singular or plural with the "s"), a verb for a tense (past tense with -ed), etc.
- Not all words give the same amount of information. Typically, some short function words that we call "stop words" ("a," "the," etc.) are generally meaningless when making phrase comparisons.
- Misspelled words add a layer of difficulty (and even though there are lists of the 100 most often misspelled words in English, misspellings can occur anywhere).
The AOL Dataset
To provide an example for this article, I downloaded a publicly available dataset of web queries collected on AOL Search in 2006 (note that as of 2016, this dataset can no longer be downloaded from infochimps, but you can learn more about the dataset in the README file). From the 20M search queries, I extracted 300,000 queries to create the dataset we are going to use.
Each row is a search query issued by a user. The columns are:
- AnonID: an anonymous user ID
- Query: the query -> what we are going to work on
- QueryTime: the time at which the query was submitted
- ItemRan: the rank of the item the user clicked on
- ClickURL: the domain of the link the user clicked on
This is a really interesting dataset because the queries come from a real case and with misspellings. Let's have a look at the data: we have around 300,000 rows. We see that a text transformation has already been applied to the dataset: all queries are in lower case.

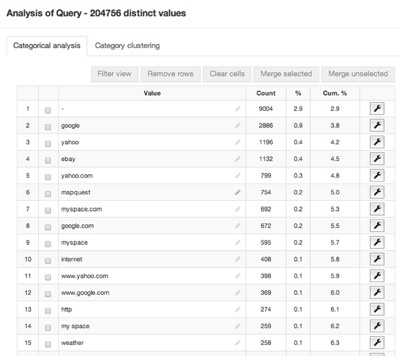
The top queries are:
Text Normalization
The first transformation we are going to do is to simplify the text of the queries, which will help us compare and regroup similar queries. By clicking on "add script" in Dataiku, we can choose the "simplify text" processor. Then we can change the settings to transform the Query column into a new column with the following actions:
- Normalizing text: Transform to lowercase, remove accents, and perform Unicode normalization.
- Stemming words: Transform each word into its "stem," i.e., its grammatical root. For example, grammatical would be transformed to "grammat."
- Clearing stop words: Remove so-called stop words (the, I, a, of, etc.).
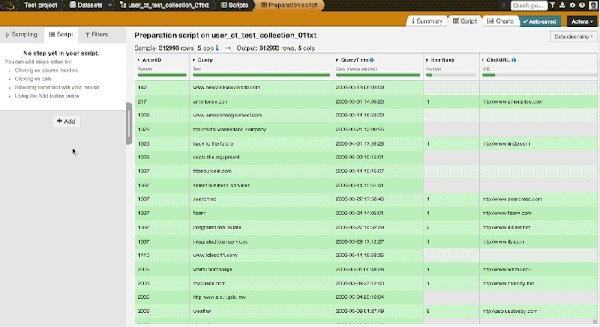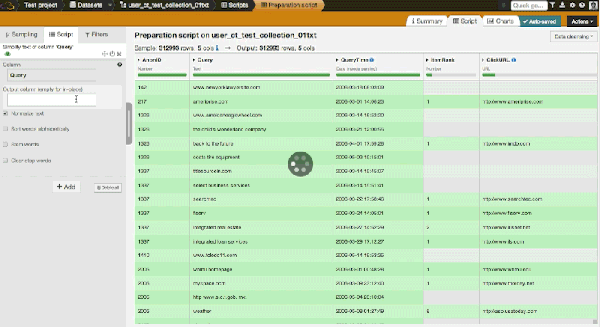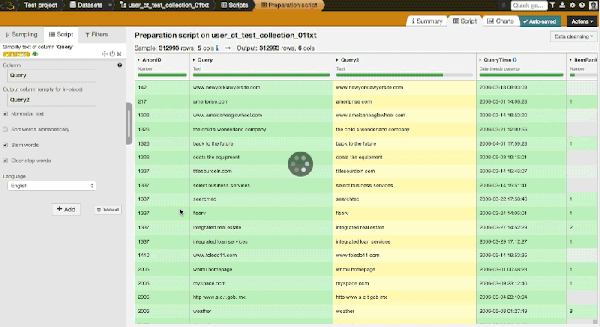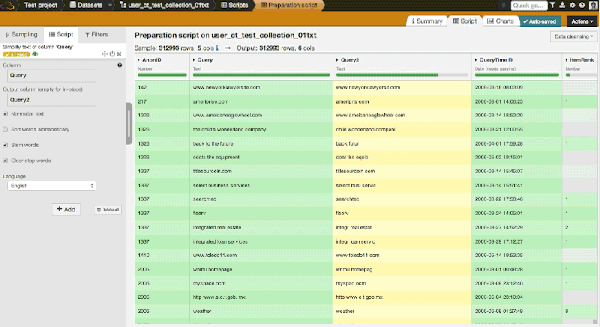
Top queries are now:

Text Clustering
The next step is to group or to cluster the similar queries. The idea behind this transformation is to reduce variance among the user queries. Simplifying the query allows us to have more relevant statistics by merging queries that should be considered as the same queries.
With Dataiku, this transformation is very easy. We open the Category clustering window, choose a few settings, and wait for suggested merge. Then, we choose the clusters to merge:
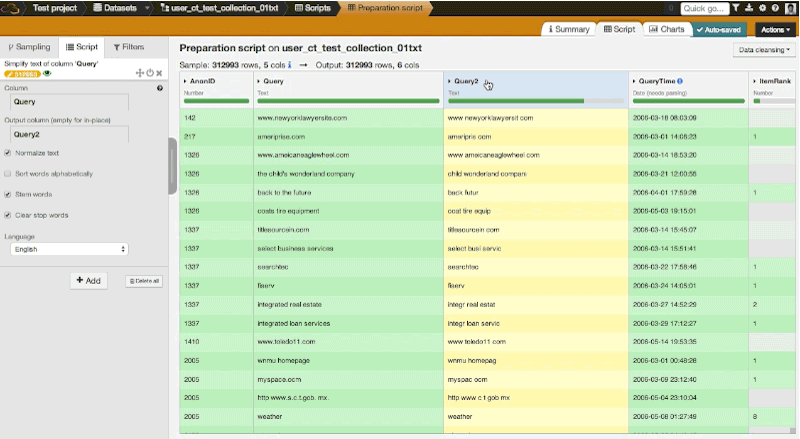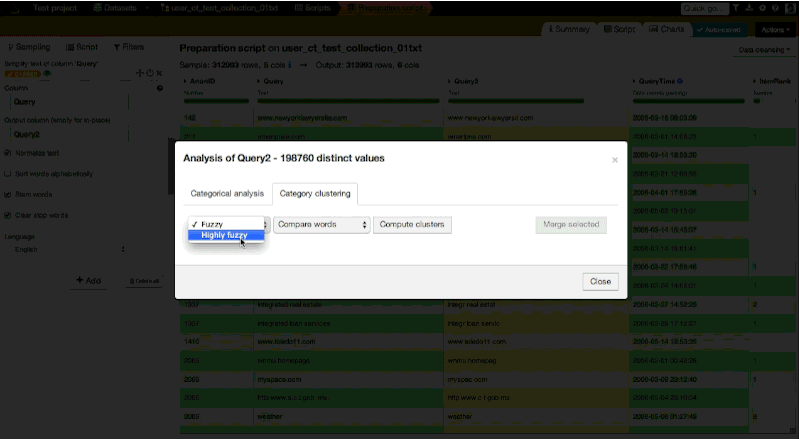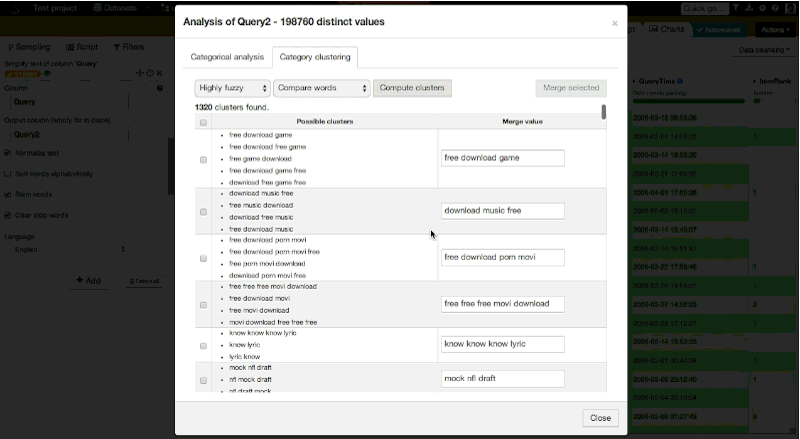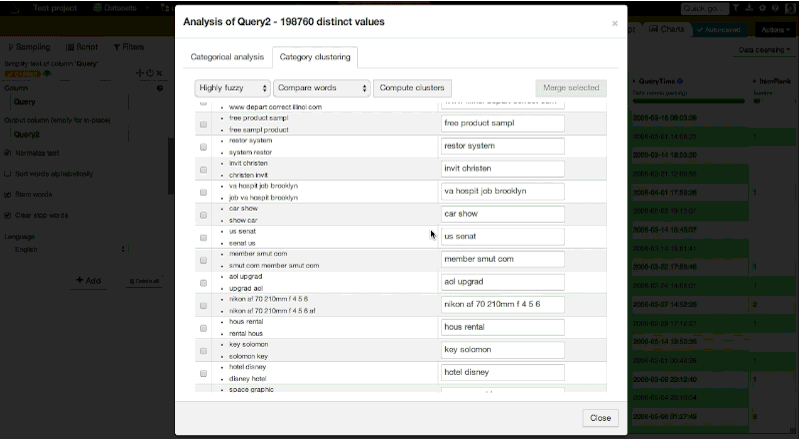
In our case, it calculated that we have 198,760 distinct values (out of ~300,000 queries). Among the distinct values, it found 1,320 clusters. Here is an overview:
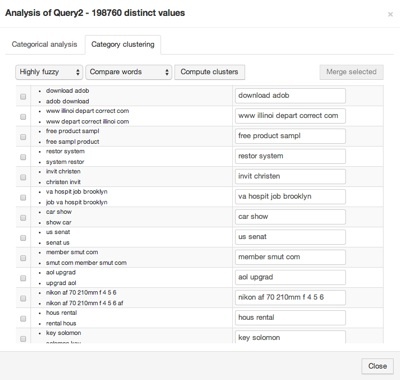
By merging clusters with a set of settings, we can easily reduce the number of distinct values by a few thousand.
Top queries after a two-step clustering:

That's it! This is a good way to work with text-based datasets. We have other great tools in Dataiku such as the fuzzy join for joining datasets on an approximate string matching.