




{kind=link}
This article was written in collaboration with our friends at Aimpoint Digital.
Supply chain teams have long consisted of business analysts that have an excellent understanding of the thousands of moving pieces. Thousands of moving pieces equate to lots of data and an incredible opportunity to make data-driven decisions. The critical question, then, is how can supply chain analysts be empowered to make data-driven decisions? In this two-part blog, we walk through an end-to-end supply chain use case without writing a single line of code.
Before diving into the data science fun, let's set forth the goals and benefits of the project. Starting a data project with a clear goal in mind is critical for the project's success. Data projects require iterations of hypothesis testing with many different data sources. The idea is not to have all questions answered before starting the project. However, beginning with a goal (reduce late deliveries) and benefits (save millions of dollars on late fees) keeps us focused on the big picture when we inevitably face limitations and need to make critical project decisions.

On-Time Delivery With Dataiku
One of the interesting outcomes of pandemic-related disruptions is that discussions about supply chains are now commonplace. Let’s take this opportunity to learn more about this previously low-key backbone of commerce.
Use Case Background
Goal: Reduce late deliveries. On-time delivery is the use case focused on predicting if a truck will meet its delivery window. Let’s unpack that.
- “Predicting if” equates to machine learning (ML) and, precisely, a classification task.
- “Truck” All modes of transportation are used to transport goods. In our case, trucks!
- “Meet its delivery window” is a predefined time slot provided by the retailer ordering the goods.
Business Value Benefits
Missing delivery windows lead to fines and each retailer has its own penalty schedule. Walmart, for example, charges 3% of the cost of goods in the order. It adds up to millions of dollars per quarter. Considering these orders are headed for distribution centers, their potential order value is hundreds of thousands, and there are thousands of orders. A company can decrease its operating expenses by millions of dollars if an ML model can proactively call out deliveries with a high probability of missing delivery windows.
Requirements:
1. Data
Historical delivery data with labels that classify each record as "on-time" or "not on-time." This data is, almost certainly, scattered across multiple supplier systems. But it is required for our eventual ML model.
2. People
- Based on our data requirements, you might have guessed that we need a Data Engineer (DE). Beyond curating data for other groups, a DE is also critical in managing the project and models built on top of the data they provide.
- Analysts. This group is especially critical for supply chain projects. They have an in-depth understanding of things like carrier codes. Supply chain data tends to be incredibly messy, and the analysts know and work with this data daily. This group is also our domain experts.
- Data Scientists (DS). This group is the statistically inclined bunch. They will need to work closely with the other two roles. They will have to work with the analysts to understand and transform the data for modeling. And work with data engineers to help them manage the ensuing models.
Data
Each company has unique data systems. Even for an identical use case, the data sources will vary from one company to another. Ultimately, the data we needed was spread across multiple sources like flat files from various carriers, historical financial data for late fees from SAP, and domain-specific systems like Transplace or C.H. Robinson. These three systems are the sources of the dataset used in this blog. The dataset has 88 columns and about 90K rows, with each row being a distinct delivery marked as "on-time" or "missed delivery window."
Data Preparation
Preparation of the data is arguably the most critical step. It is also the most extensive component of most data projects. Our final project pipeline has over 70 individual preprocessing steps. Let's examine some of the critical steps.
Data Preparation requires an understanding of the data at hand. To that end, Dataiku has EDA (exploratory data analysis) capabilities built into the platform — check out this four-minute video on data exploration with Dataiku.
Data Leakage
Data leakage is the concept of creating a predictive model with information that will not be available to the model in production (e.g., when a delivery is requested, we may not know which carrier will pick up the order). To that end, we cannot train our model(s) with columns specific to the carrier. Right out of the gate, we deleted over 40 columns from our dataset that weren't available at the delivery request. Supply chain projects are especially susceptible to data leakage as data from carriers and buyers becomes available at varying frequencies.
Understanding which columns to remove is a gargantuan task as it requires a trial-and-error approach. Collaboration with the analyst team is a great way to leverage their subject matter expertise and reduce the trial-error cycles.
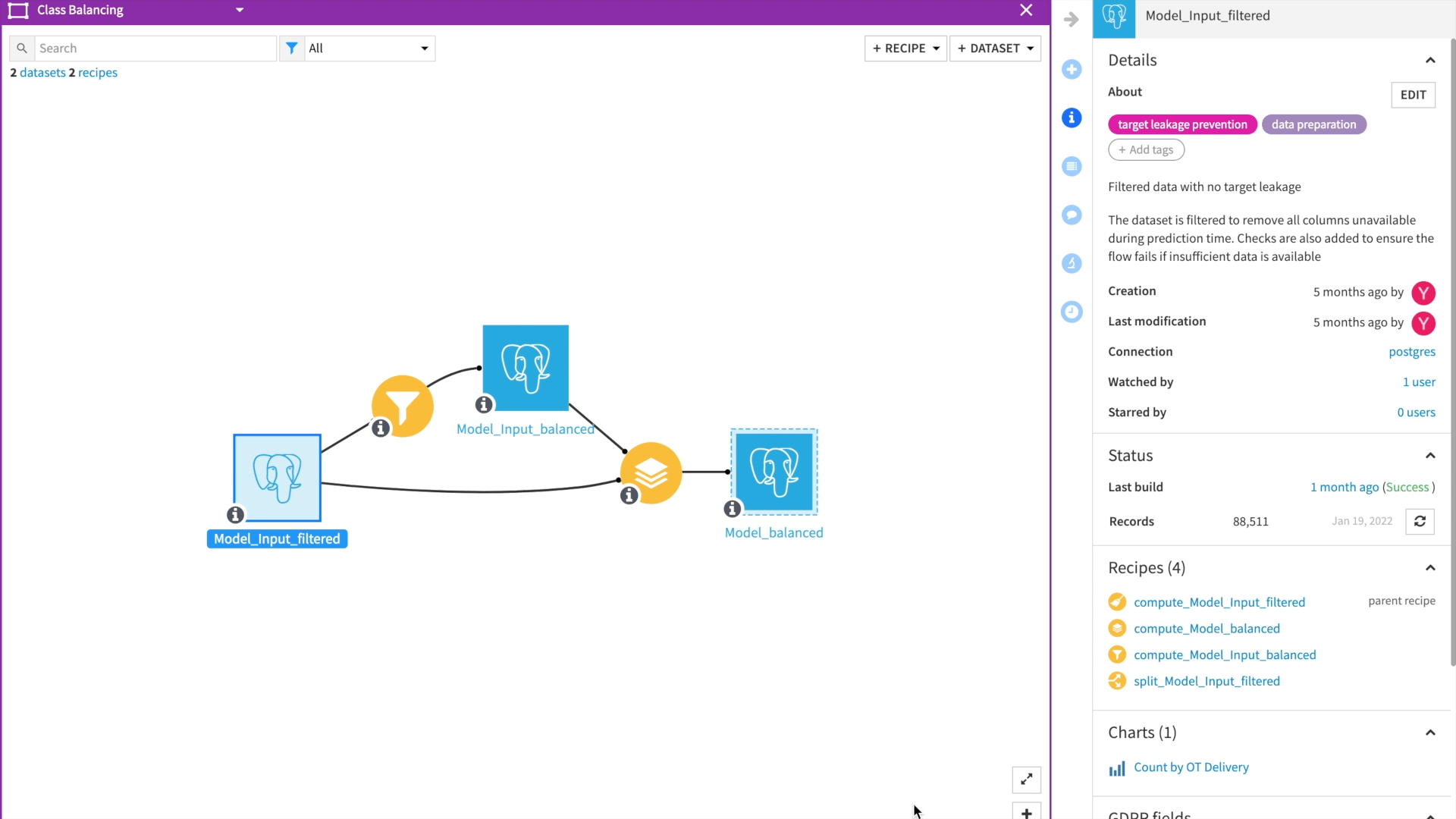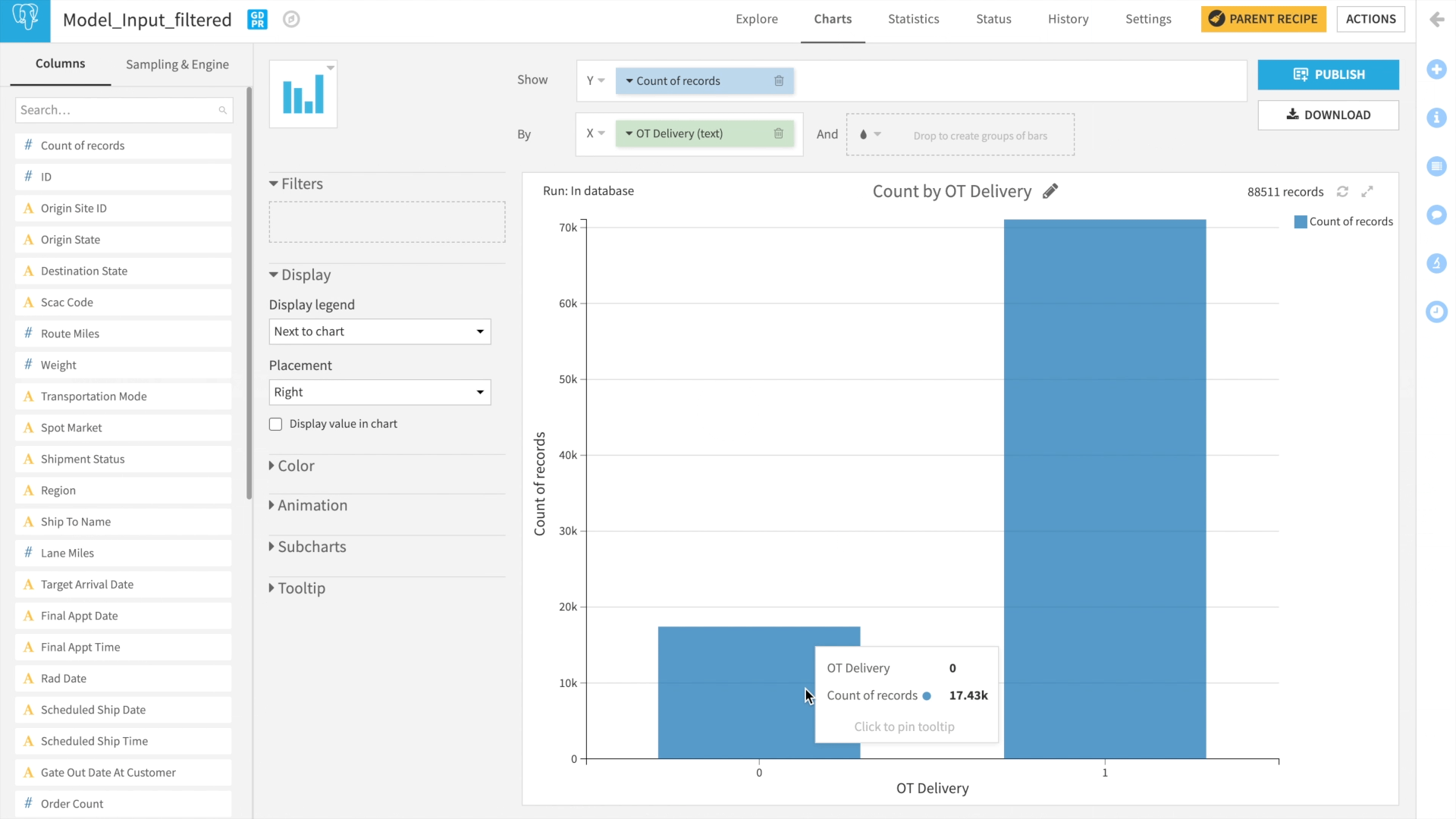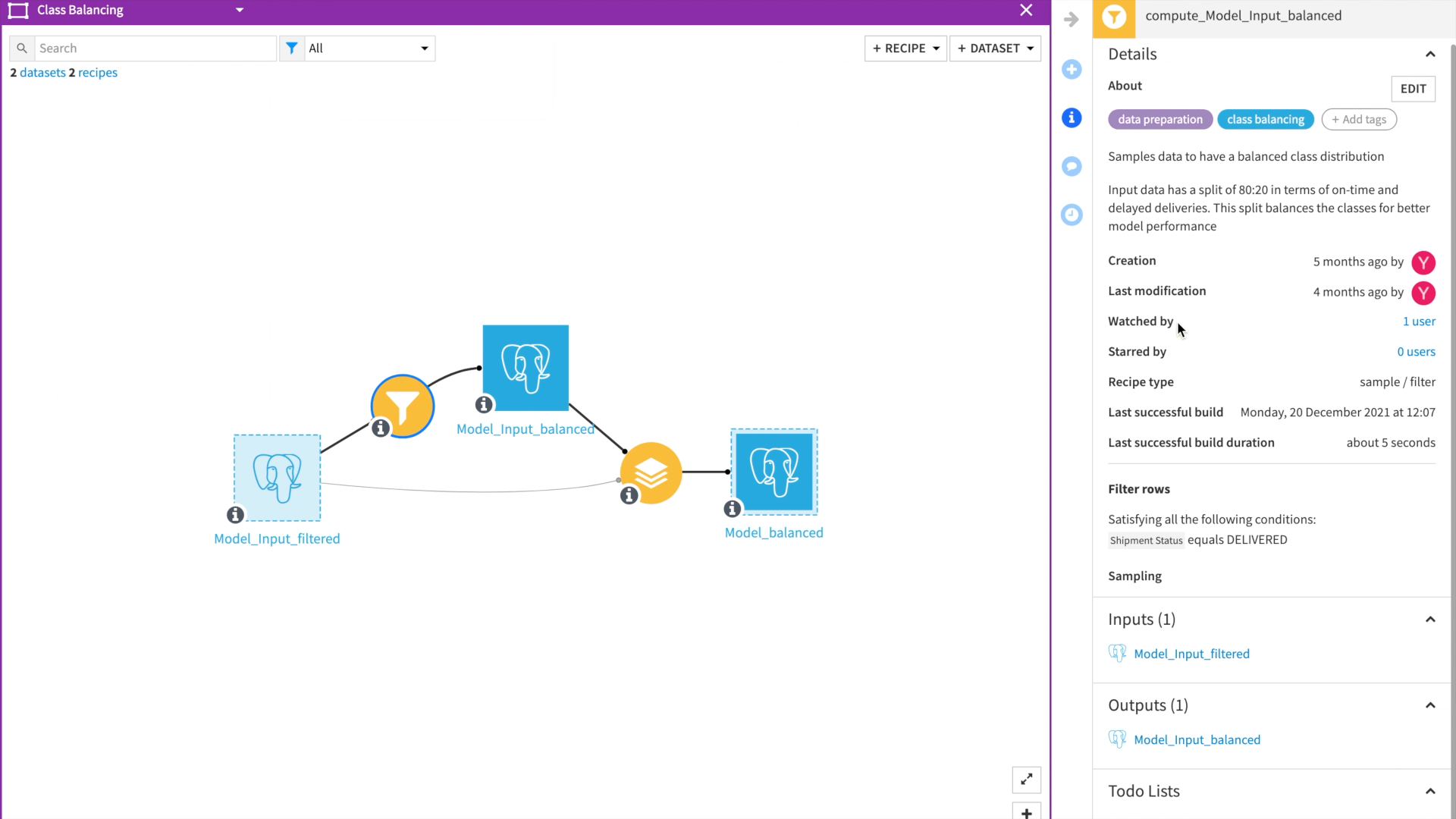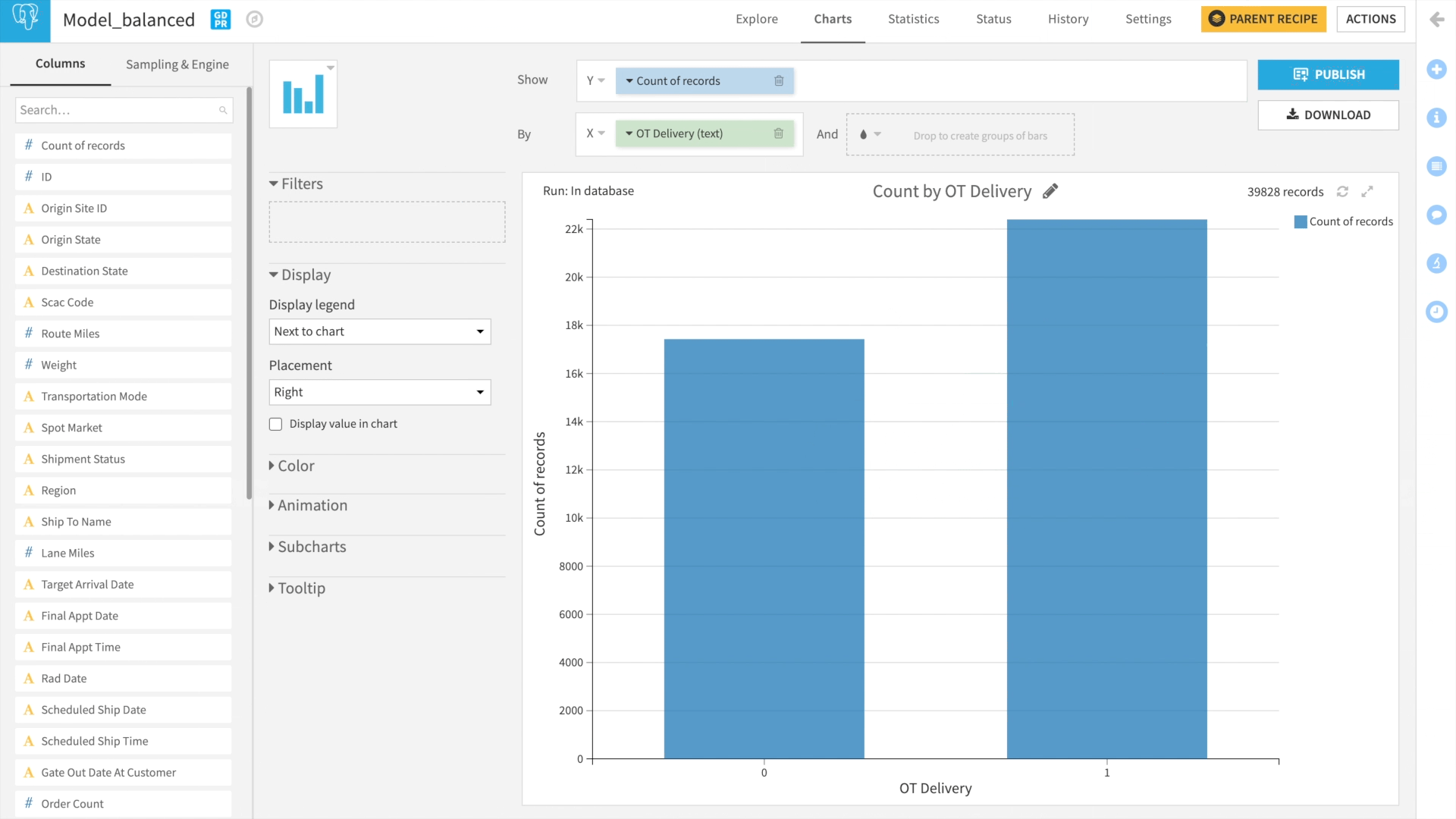
Class Rebalance
A common issue for classification-based models is accurately predicting the minority class. In our dataset, the minority class is “late delivery” because over 80% of our records are for deliveries that were on time. From a business standpoint, 80% of the deliveries on time might be acceptable. From an ML standpoint, we need data with equal distribution for deliveries on-time and late. As the below gif demonstrates, we are simply replicating records for late deliveries. This simple step can drastically improve model performance.
Final Data Preparation
Note that we did not write code for any of the preparation steps in our training pipeline (joins, string operations, aggregations, and pivots). However, you will still find full support for coding in Dataiku. The Dataiku Academy even has a course dedicated to coding.
Further, without Dataiku, we would need additional preparation steps for imputation, one-hot encoding, cyclical time encoding, and data normalization. Dataiku has built-in functionality for each of these steps.
Recap
We have covered lots of critical content. Let us recap some key points:
- Data projects should start with a clear goal and attached benefits.
- Be conscious of data leakage. It can lead to overly optimized models that can lead to bad business decisions.
- Be mindful of target class balance. Otherwise, the predictive model will have a tough time predicting the minority class.
Our project is now ready to start training predictive models, which will be covered in part two.