




{kind=link}
In January, our Dataiku Lab team presented their annual findings for up-and-coming machine learning (ML) trends, based on the work they do in machine learning research. In this series, we're going to break up their key topics (trustworthy ML, human-in-the-loop ML, causality, and the connection between reinforcement learning and AutoML) so they're easy for you to digest as you aim to optimize your ML projects in 2021. We've already tackled trustworthy ML, human-in-the-loop ML, and causality, so up next is a summary of the section on reinforcement learning and AutoML, presented by Aimee Coelho. Enjoy!
Aimee Coelho:
As Leo mentioned, each year so far that we've given this ML trends webinar, we've looked at reinforcement learning. We've seen the amazing achievements in simulated environments, such as AlphaGo and AlphaStar. We've asked ourselves, "Is this going to be the year that we start to see more widespread applications appearing in the real world?" But perhaps the question that we should be asking first is "Why is it so difficult to transfer these advances into real world applications?" So reinforcement is a framework for learning sequential decision making. It can learn to solve very large and complex problems, even in the presence of uncertainty or a dynamic system. This is a natural fit for problems such as control in a physical system, dynamic pricing, or inventory control.
A reinforcement learning algorithm, or agent, learns optimal decision making strategy through trial and error, taking an action in its environment, and then receiving a reward. In video games, these environments are simulated. The algorithm can try as many things as it wants with no real-world consequences for poor decisions, but in real-world situations, a simulator may not be available or interacting with a real system may be expensive or dangerous. These are some of the nine challenges identified for productionizing reinforcement learning, which are being actively studied.

One recent exciting example where they managed to overcome some of these challenges is Loon. It's a paper recently published in nature by Google. Loon is a balloon that operates autonomously in the stratosphere for months at a time. It can deliver communications and take weather measurements. The goal of the navigation system of the balloon is to remain within a 50 kilometer radius of a particular ground station. The reinforcement learning agent must learn a control strategy to leverage the wind currents at different altitudes in order to maintain its position within that radius by moving up and down in altitude.
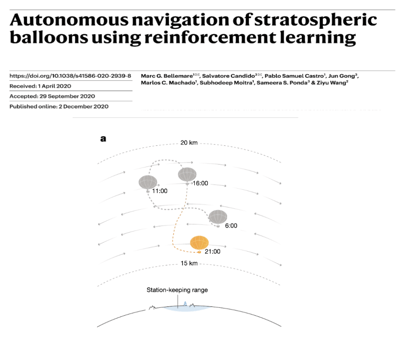
In the diagram, you can see that the movements required to remain in the radius may look like this, a figure eight. One key challenge in this application is that the weather forecasts may be wrong and the local wind measurements may be sparse. So the agent has to learn a strategy, which is robust to these types of errors. One way that the team addressed this was in the way that they built the data for their training simulations. They added procedural noise to historical meteorological datasets, and this acted as a form of data augmentation and helped to train a more robust agent. Once the algorithm had been trained, it was implemented on the balloon and tested live over the Pacific Ocean in a 39-day flight, where it was able to outperform the current expert design system based on physical models.
Reinforcement Learning Applied to AutoML
In addition to reinforcement learning being applied to this type of real-world control problem, an interesting trend is the application of reinforcement learning to machine learning itself, in particular to AutoML. While it may not be a new idea to apply reinforcement learning to AutoML, it's certainly noticeable that as the field grows and matures, it's being applied to a wider range of problems. Today, I'm going to highlight just three examples.
Automated Feature Engineering
The goal of full AutoML is to be able to produce optimal models for new tasks, with a minimal amount of human intervention and computation time. In order to build a machine learning model, there are a number of decisions which need to be made, such as which algorithm or architecture to use and how to set the hyperparameters. When using classical machine learning, one key issue is how you transform the input features you have in your data set to improve performance. Applying transformations such as log operations, squares, or producing combinations of multiple features has been shown to be beneficial. A simple approach might be to apply a number of these transformations to all the input features and then apply a feature selection step. This is known as an expansion reduction technique, but with many features and available transformations, even the decision to apply second order transformations to get features like A upon B squared can lead to an explosion in the number of transformed features.
One first approach from feature engineering for predictive modeling using reinforcement learning creates a transformation graph for a dataset, where each node represents a possible dataset and each edge represents a transformation. Then they use reinforcement learning to learn an efficient, performance-driven exploration strategy of that graph within a certain budget. Recent work in cross-data automatic feature engineering via meta learning and reinforcement learning builds on this idea, but instead their transformation graph applies transformations to individual features. They employ meta learning to learn a general of exploration strategy on a set of datasets, which is then fine tuned on the target dataset.
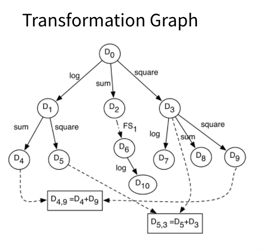
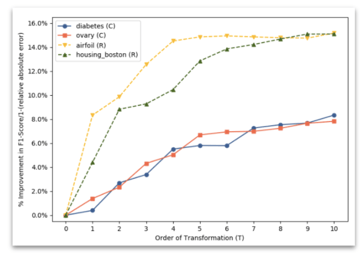
Another work, neural feature search takes a slightly different approach. They treat each feature independently and thus in parallel, using reinforcement learning to learn a neural transformation rule for each feature. In this setup, you have a neural controller, a recursive neural network, which is capable of generating a sequence of transformations for a feature up to a given length, and that sequence (or given length). That can include a delete operation, thus allowing for feature selection. Transformation rules are then sampled from the controllers, one per feature, applied to the dataset and the dataset is trained and evaluated. The returned metric is then used in the reward to train the controllers. So you have this loop that you see in the image above. With this efficient approach, they're able to generate transformations up to higher orders than in other works and, as you can see in the plot, the gains in performance can be seen all the way up to 10 steps for some datasets.
Learning to Improve Existing Algorithms: Bayesian Optimization for Hyperparameter Optimization
The next example applies reinforcement learning to improve one of the most widely used algorithms for performing hyperparameter optimization, Bayesian optimization. Bayesian optimization has two components, a surrogate model, most commonly a Gaussian process and an acquisition function, which controls the trade-off between exploration and exploitation of the space. The surrogate model will be fit to the evaluations of the objective function and then the acquisition function, which you can see underneath in orange on the left, can then leverage the predicted performance and uncertainty of the surrogate model to suggest which point to evaluate next.
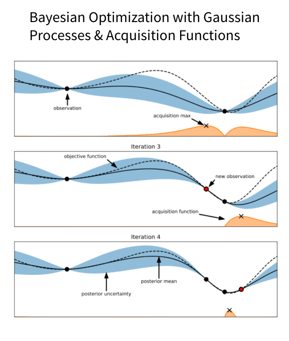
The key point is that in machine learning, for example, when we're repeatedly optimizing the hyperparameters of the same algorithm, but with different datasets, it would be valuable if we were able to transfer some of that information from previous runs in order to be more data efficient. That's exactly what this paper is doing. By learning a neural acquisition function over a set of training datasets, they're then able to apply it to the target dataset where it adapts online. This means that they're able to transfer valuable information about this particular objective function and speed up the time to find the optimal configuration.
Neural Architecture Search
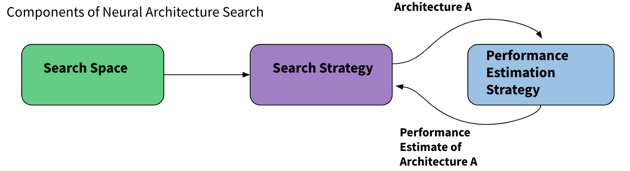
The third example is probably the best known, but I'd be remiss if I didn't talk about it. And that's neural architecture search. We all know that in recent years, expert designed deep learning architectures have achieved incredible performance across a wide range of tasks from image segmentation to language generation. However, designing the architectures for these tasks requires a lot of domain expertise and a lot of time, and it may not be optimal. The goal of neural architecture search is to automate the architecture design process by searching over many different configurations for optimal architectures for a given objective. And that objective can be purely performance based, but it could also be to maximize performance while minimizing resource consumption so as to design efficient networks for smaller devices like mobile. It's already been shown that it can beat state of the art hand engineered solutions. So how does it work?
Well, a neural architecture search system consists of three components. First, you have to define your search space. The options you include such as types of layers or allowing for the use of skip connections, will dictate both the complexity of the possible models and the total number of combinations possible. Once you have a search space, you'll need a search strategy. This search strategy needs to be able to traverse this large combinatorial space and find the best architecture. It could be something as simple as a random search, though some of the most popular strategies are reinforcement learning, evolution strategies, and Bayesian optimization — and the larger the search space is, the more important it becomes to have an intelligent search strategy.
Each time your search strategy identifies the next architecture that it would like to test, you'll need a performance estimation strategy, which can return you the estimated performance of that network. In the most straightforward case, this would be the validation accuracy from actually building and training that architecture. Back in 2017, a paper from Zoph and Le was released showing how to use reinforcement learning for neural architecture search. It drew a lot of attention to the field, which is still very active today. The system that they designed is the same one that's since been used for neural feature search, which I just talked about. You have a recurrent neural network as a controller, which is capable of generating a sequence of parameters, which describes an architecture. That architecture is then built and the model trained and the evaluation of the child network is then used to update the controller.
While it was exciting to see that this could work and rival the best handcrafted models, as you can imagine, needing to train an excess of 10,000 deep learning models is very costly. This experiment used 800 GPUs over a number of weeks. And so in order for neural architecture search to become practical, researchers have been working on techniques to make this more efficient, both by redesigning the search space and by coming up with efficient methods to estimate the performance of a neural network. Leveraging these speed-ups, reinforcement learning has recently been used to find highly competitive architectures for graph neural networks and for GANs on a single GPU in only seven hours.
Reproducibility
Another trend that we discussed last year was reproducibility, and we thought we'd take a look at how that's evolving a year Later. Following a lot of discussion about how we can improve reproducibility in the field, one initiative that was launched was a reproducibility challenge where people could claim a recent paper and try to reproduce the main findings of the paper, usually in contact with the authors. This proved to be a valuable exercise and this past year it took place again and was expanded to seven conferences.

Another initiative that was produced was a reproducibility checklist, which was introduced at NeurIPS, which included things like proper documentation of all hyperparameters used and the release of code. Already in its first year, it saw an increase of 25% in the number of papers releasing code with their submission. Over at Papers With Code, which is a fantastic resource in case you aren't familiar with it, they went further; they put together a set of best practices for the code repository, which was also incorporated into last year's checklist. This set of best practices includes things like documenting dependencies and how to set up the environment, and it also serves as a grading scale. After grading a random selection of submitted repositories, they plotted the grades against the medium number of GitHub stars, as a proxy for the usefulness to the community, to verify that these guidelines are indeed helpful.
One key argument for why reproducibility is so valuable is that it helps to drive robust scientific research and benchmarks are a valuable tool here. It's well known that they can help push the state of the art by enabling fair and fast comparisons between techniques with ImageNet being probably the most famous example. But benchmarks can also enable a deeper understanding. In this NASBench series of benchmarks, their goal is to leverage the heavy computation resources just once to train a very large number of neuron networks in a search space, and then to make these results available to the community. This can reduce the time taken to test a neural architecture search algorithm from days to just minutes on a laptop. This not only lowers the entry barrier to the field as now anyone with modest compute resources can participate in studies, but it also means that valuable systematic studies of certain design choices can be performed. While reproducibility is certainly not a solved problem, it's definitely great to see the progress that's being made in this area.