




{kind=link}
Last week, our Dataiku Lab team presented their annual findings for up-and-coming machine learning (ML) trends, based on the work they do in machine learning research. In this series, we're going to break up their key topics (trustworthy ML, human-in-the-loop ML, causality, and the connection between reinforcement learning and AutoML) so they're easy for you to digest as you aim to optimize your ML projects in 2021. This post is a transcription of the section on trustworthy ML, led by research scientist Simona Maggio. Enjoy!
Simona Maggio:
Trustworthy ML is the concept of building machine learning models that can satisfy real-life requirements. This has been a major concern for organizations as they deploy more and more models in real-life conditions, especially for safety critical applications such as healthcare, education, justice, and transportation. So some of the targets of trustworthy ML are fairness, transparency, security, reliability, and others. And, in 2020, we've seen the major conferences in ML organizing many workshops and initiatives around trustworthy ML. And we believe that this trend is going to go on the next few years. And in particular there are two of these targets of trustworthy ML that are very well known and have gained momentum, especially because of regulatory compliance requirements: transparency and privacy.
They are still very much two big trends yet. We can see privacy-preserving techniques that are still emerging, as there is a lot of work on them and also the rise of open source communities around these topics such as OpenMined. And as far as transparency is concerned, we can see also that there is a lot of research on interpretability techniques to explain model behavior, also to perform a counterfactual analysis. And so interpretability is still a big trend. We are going to focus more on how interpretability connects to other topics that we're going to talk about today, in particular in this webinar I'll only focus on one of the targets of trustworthy ML, which is reliability.
Breaking Down "Reliability"
So first we can think of reliability as a software-like reliability, and also the research community is thinking of machine learning models this way now. So a machine learning model is not only an algorithm considered in isolation, but is a part of a software ecosystem, a more complex system. And as such, it has to be debugged as any other piece of software, against failure that are problems in accuracy, in fairness, or in security. That's why major ML players in the field like Google, IBM, and Microsoft, they are putting research effort forward, so developing techniques to allow people to do ML debugging, in particular to detect pattern of errors that could reveal the biases, but also to detect anomalies that could reveal some behavior when the model behaves in unexpected ways.
And also a part of the research is working on how to detect security flaws and also to assess whether a model is secure against attacks meant to steal sensitive data or maybe to alter the model output. But it's not only about detection of model flaws. It's also about remediation strategies to fix these model flaws. And that's why there is also a lot of research in testing techniques for assisted data cleaning, assisted data augmentation, targeted regularization, and also model assertions.
Another effort in reliability of machine learning models comes from the latest research of Microsoft about model compatibility. So compatibility is not a built-in feature of machine learning models because when you have a new model that you train on new data and it is performing namely better than an old deployed model, and you want to replace it, actually, this could break the overall system performance. And that's especially because the failure modes might be different. So that's why research is working into providing engineers with tools to evaluate this compatibility of machine learning models, and also more in general, to evaluate a model in an evolving ecosystem multiple times during its life cycle and not in a single time in lab condition as an isolated metric. So ML debugging is still an emergent field, and we will see many advances in the next few years.
Performing Well in Out-of-Design Conditions
So now another kind of reliability is a reliability as a performance in out-of-design conditions. Indeed, when you have a model that you consider reliable, you might think that you will perform well, even in slightly different conditions from what was faced during training. But actually we can observe that machine learning models have many blind spots, in particular they are not robust to perturbation. So with slight perturbation a high confidence prediction of a cat can be turned into a high confidence prediction of a guacamole, and this is the example of this adversarial perturbation that you have in the first line.
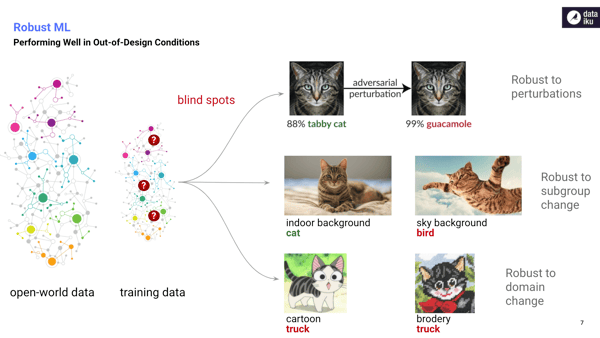
If you look at the second line of figures, also models tend to learn spurious correlation. So they learn correlation, something that correlated with the output that is not the right thing they should learn, and they can put too much weight on this spurious correlation to provide the answer, like in this case, giving way too much importance to the background instead of the subject of the photo. And these spurious correlations are really bad because they make the model perform differently on a different subpopulation, especially penalizing the less represented group.
So last, blind spots regarding the domain change. So machine learning models, they are not robust to domain change, like a change in a sensor collecting data or also a change in representation style like you can have in this illustration. And that's why machine learning research is focusing on robustness and, in particular, on understanding the reason for failure, like understanding why current training procedures are not yielding robust models. For instance, there are some works that suggest that learning for visual tasks features that are more aligned with human perception can actually lead to more robust models that can adapt to new situations, but, in general, researchers don't think there is a silver bullet solution to all our robustness problems.
There are many emerging techniques, so, that are based on iterative training procedure on multiple cooperating models. And they also leverage semi-supervised learning and meta learning techniques. But as we can't make a model robust to all the changing conditions that occur continuously in time, there is still a lot of research in the more traditional field of failure prevention with real time audits, such as novelty and anomaly detection and open class identification, identification of low trust prediction, and more in general research for models that have a better built-in uncertainty, such as the generative models.
Accuracy vs. Robustness
And now I want to conclude about robustness regarding a trade off between accuracy and robustness, because in contrast to the past where researchers tend to think that there is an intrinsic trade off between accuracy and robustness, actually the latest work is suggesting that actually we can achieve both accuracy and robustness in our training. In particular, if you look at this picture in this slide, it's a model that has been trained on four different types of cameras and in design conditions, it has a very good performance. And when we want to test it on camera number five, we can see that there is a performance that goes very low to the black line.
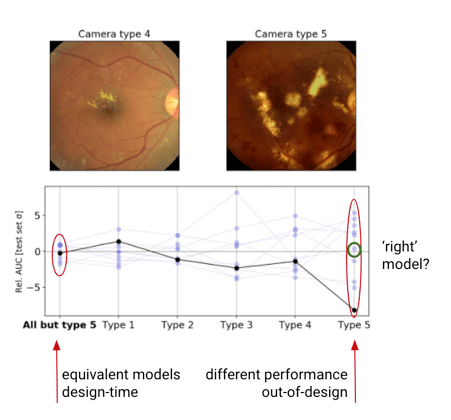
And we could think, okay, it's a structural failure. We can't learn what we would like from the available data with this model. And so there's nothing we can do. Just the model can't generalize on this new camera. But actually what has been found is that if you train with different random seeds, the same kind of model, same architecture, you can get the same behavior at design time, but really different behavior at deployment time. And maybe one of the models might even be learning the right thing, like it can be learning to generalize also in camera number five. So this is interesting because it means that robust models can be achieved. It's not a structural failure. It's another situation that has been named recently by Google researchers underspecification. And that's for this reason that there is also research not only regarding how to build more robust models, but how to evaluate models at deployment time.
And this can be done via application specific stress tests, including some simulation of data — simulation is especially useful for rare failures — and also development around some strategy, such as how to select the right model, the model that is learning the right inductive bias. And this could be via including domain knowledge with machine learning rules, expected explanation but also known causal relationships. Robustness is really a human-centric concept that is introducing a paradigm shift on how models are evaluated in research. So not a validation against a single metric in a lab condition, but validation against human expectations.
Stay tuned for the next article which gives an overview of the next ML trend for 2021, human-in-the-loop ML, which is all about involving the human in the validation process.