




Organizations continually analyze and enrich the data stored in both SAP and their other data sources, aiming to maintain the highest data accuracy and integrity. Having invested in their ERP landscape, SAP customers are keen to optimize operations governing their critical business data and often create a SAP competence center internally that centralizes SAP skills and knowledge.
An SAP competence center builds and nurtures roles such as business analyst, data engineer, or data analyst. Combined into one team, these personas are responsible for maintaining the Extract, Transform, Load (ETL) environment for analyzing large amounts of data in a descriptive way. This forms the intelligent core of an organization’s data science project strategy, which serves to leverage the investment of the existing infrastructure. However, not all environments are optimized, all of the time.
Dataiku’s all-in-one platform gives views and tools for the data unique to these different personas. Dataiku is the only single solution designed to manage all users from end to end for analytics projects involving SAP. It has a visual interface, data preparation capabilities, and a coding environment — all on the same platform — as well as prebuilt connectors to both the SAP infrastructure and other data sources.
Data teams benefit from collaboration and clarity, having insight into each other's roles and project contributions. Dataiku enables data science projects involving SAP at scale and in unison, and new projects have the power to leverage the elements of previous projects. Dataiku fosters clear communication and collaboration between people with interdependent yet different roles. This provides a heightened return on the investment made in the SAP landscape — integrating data science web apps and SAP Fiori Launchpad and pushing results into SAP Analytics Cloud (SAC).
High-Level Customer Setup
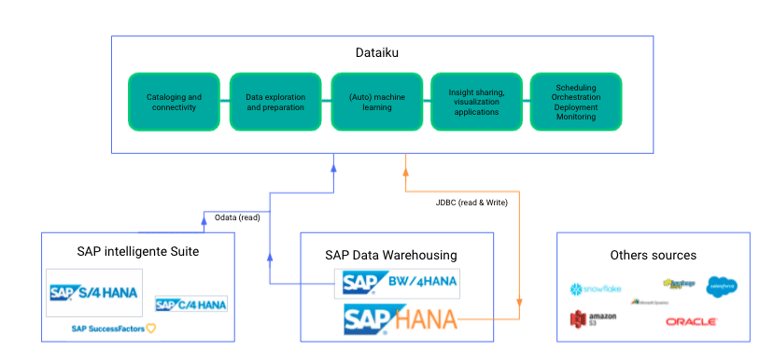
{kind=link}
The architecture diagram above highlights how Dataiku integrates with SAP HANA and other data sources, leverages the compute power of SAP HANA, and promotes the consumption of results with SAP Fiori Launchpad and SAC. Dataiku enables users to:
- Read SAP data — especially tables — using the SAP HANA Connector
- Read SAP data using the Dataiku SAP OData Plugin (CDS Views)
- Use the HANA database to store data during the transformation process
- Use SAP HANA as a compute engine to execute data preparation tasks (i.e., a join recipe)
- Create AI models using the Dataiku Lab
- Use Dataiku Python code recipes with the SAP HANA Predictive Analytics Library (PAL)
- Publish charts and dashboards within SAP SAC
- Promote Dataiku webapps within SAP Fiori Launchpad
Dataiku and SAP in Action
Dataiku offers two major components to read SAP data:
- SAP HANA Connector
- SAP OData Plugin
In our demo example, we will read the table “KNA1” using the HANA Connector and sales orders using the CDS View “GWSAMPLE_BASIC'' using the OData Plugin. The data is enriched from other external sources available either via a SQL table or CSV file and which include, for example, statistics about GDP. Within the Dataiku flow, our flow zone is dedicated to connecting to the different datasets.
The middle flow zone performs data transformations and joins the datasets. All the data transformations are done directly in SAP HANA and the result is stored in a new SAP HANA table.At the end of the transformation flow, the datasets are split for training and testing. The right side has two zones: The lower zone uses the Dataiku AI Lab for building a prediction model and the zone above uses the SAP PAL library within a Dataiku Python notebook to define a prediction model.
Set Up Dataiku for SAP
1. Set up the HANA connector.
You can follow the Dataiku online documentation for SAP HANA and provide credentials like “Host,” “Port,” and “User/PW” via Administration and Connections. Once the setup is done, you can use the SAP HANA connection within your Dataiku flow using the “+Dataset” menu to select SQL and SAP HANA.
2. Set up the Odata plugin.
Install the SAP OData Plugin from the plugin store. Within the parameters set, provide the credentials like your SAP ERP URL, Client, and User/PW. Within your Dataiku flow, add a new dataset via “+Datasets” and select the SAP OData dataset. Choose your SAP Odata service, the entity, and your parameter preset. Check the connection by clicking on “test and get schema.” If you see your data preview, the connection is working well.
3. You can save and create your dataset!
Optional: Set Up SAP
HANA
You can use either your SAP HANA database as part of your license or you can also install the SAP HANA express edition. It is limited in size but could be a good starting point for small projects and proof-of-value projects.
CDS Views
SAP has many predefined CDS views. In order to use CDS Views via SAP OData, they have to be marked as public. CDS views can be easily developed using SAP tools (e.g., ABAP).
SAC
SAP Analytics Cloud has many possibilities and we integrated our use case following the connectivity guidelines.
Fiori Launchpad
We use the SAP Fiori Launchpad in order to embed and call the Dataiku webapp. Using this approach you can build your Dataiku flows and provide a webapp that can be integrated easily into SAP so that the SAP user has the same UI experience using the new intelligent enterprise application.
SAP Cloud Platform (SCP)
In order to provide a seamless experience to SAP users, you can leverage SCP to develop an application using FIORI standard and call Dataiku exposed models in order to realize real time scoring. This way, SAP users are able to use Dataiku deployed models from the same interface (Fiori Launchpad) and with the same experience (FIORI app) than their other SAP applications.
Training ML Models
Dataiku AutoML and Expert Mode
Data scientists can leverage the Dataiku Lab to build AI models and benefit from explainable AI, model monitoring, governance, and model documentation. All this can be achieved using the AutoML or Expert mode, without coding or with coding in your own notebooks.
This way, you can leverage all the governance, interpretability, and traceability features of Dataiku and maintain the capacity to delegate the modeling and computing to another platform (i.e., Spark, Spark on Kubernetes).
Leverage SAP PAL
SAP PAL is a great way to leverage the compute power of SAP HANA and build your AI models directly inside HANA, using the Dataiku coding approach with Python notebooks. Connect data sources for your data science flow and use the data with your SAP PAL library to create a variety of predictive models. As a result, you can leverage the predictive capabilities of HANA and the governance and MLOps capabilities of Dataiku.
Put It Into Practice
With the enriched capabilities for leveraging SAP HANA, SAC, SAP PAL, and Fiori Launchpad in Dataiku, any SAP customer can deliver state-of-the-art data science solutions. Existing investments into SAP can be leveraged and final solutions can be deployed into SAP Fiori for a seamless UI experience. By using these tips, organizations can enable citizen data scientists to collaborate with teams of data scientists and empower them to develop their own models at scale.