




Traditionally, organizations rely heavily on individuals, sometimes lawyers with a notoriously high hourly rate, to read through documents manually. They often search for relevant materials in an ad hoc manner, with no systematic way of categorizing, understanding, and interpreting the information and trends.
The technologist in me was aware of the new innovations in the field of Natural Language Processing (NLP) with pre-trained word embeddings like Word2Vec, GloVe, and BERT. I thought to myself, can an NLP algorithm perform this text-based search, identify provisions or statements based on select keywords, and provide consumable insights to the business? I often use Ctrl+F to search through documents for an initial pass-through, so why not develop an algorithm to do the same? I couldn’t help but wonder, “Could other industries benefit from a modular and reusable intelligent document processing pipeline?”
So I put my thinking cap on, hands to the keyboard, and began my quest to develop an end-to-end solution through a combination of visual recipes, Dataiku plugins, and custom code recipes in Dataiku. Since most successful projects come from a strong problem statement, I was curious to uncover what actions companies were taking in response to sustainable finance. Specifically, I hoped to answer:
- At what level of detail do organizations publish their current or future ESG goals? Is the language generic, or is there a clear definition on how to embed these goals across business processes?
- How are firms responding to the increased conversation and social pressure concerning ESG? Is there a positive or negative correlation to the amount of “ESG keywords” used in the last five years?
- Has the overall sentiment regarding ESG become more positive or negative over the last five years? Is there a clear market leader in a given sector?
- What are the common words or phrases when referring to ESG? Are these similar across a specific industry?
- In general, how can we empower a financial analyst with ESG through analytics and data science?
The next step was finding a representative, publicly available document corpus to test my hypothesis. I landed on SEC 10-K reports: comprehensive documents, filed annually, that outline a company’s main operations, risk factors, financial data, and earning statements. I figured this untapped data source could provide insight into how and what companies were doing to embed an ESG mindset into their day-to-day business processes. I started my analysis in Dataiku with the intention to develop a reusable pipeline to analyze this use case and more to come. If you are already familiar with Dataiku, keep reading on for a technical deep dive into the project design in the section below (and if you're not using Dataiku yet, check out a demo here).
Project Design
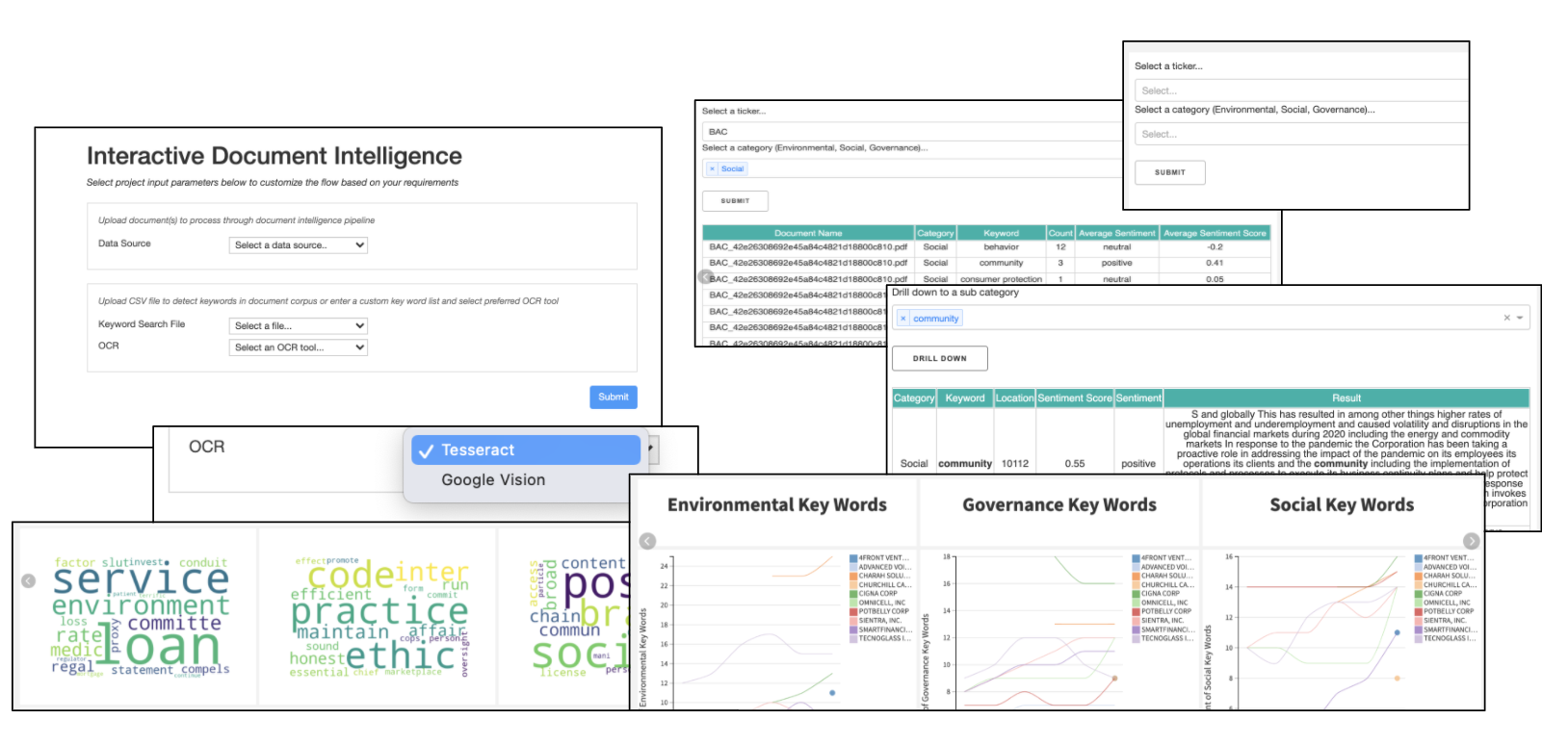
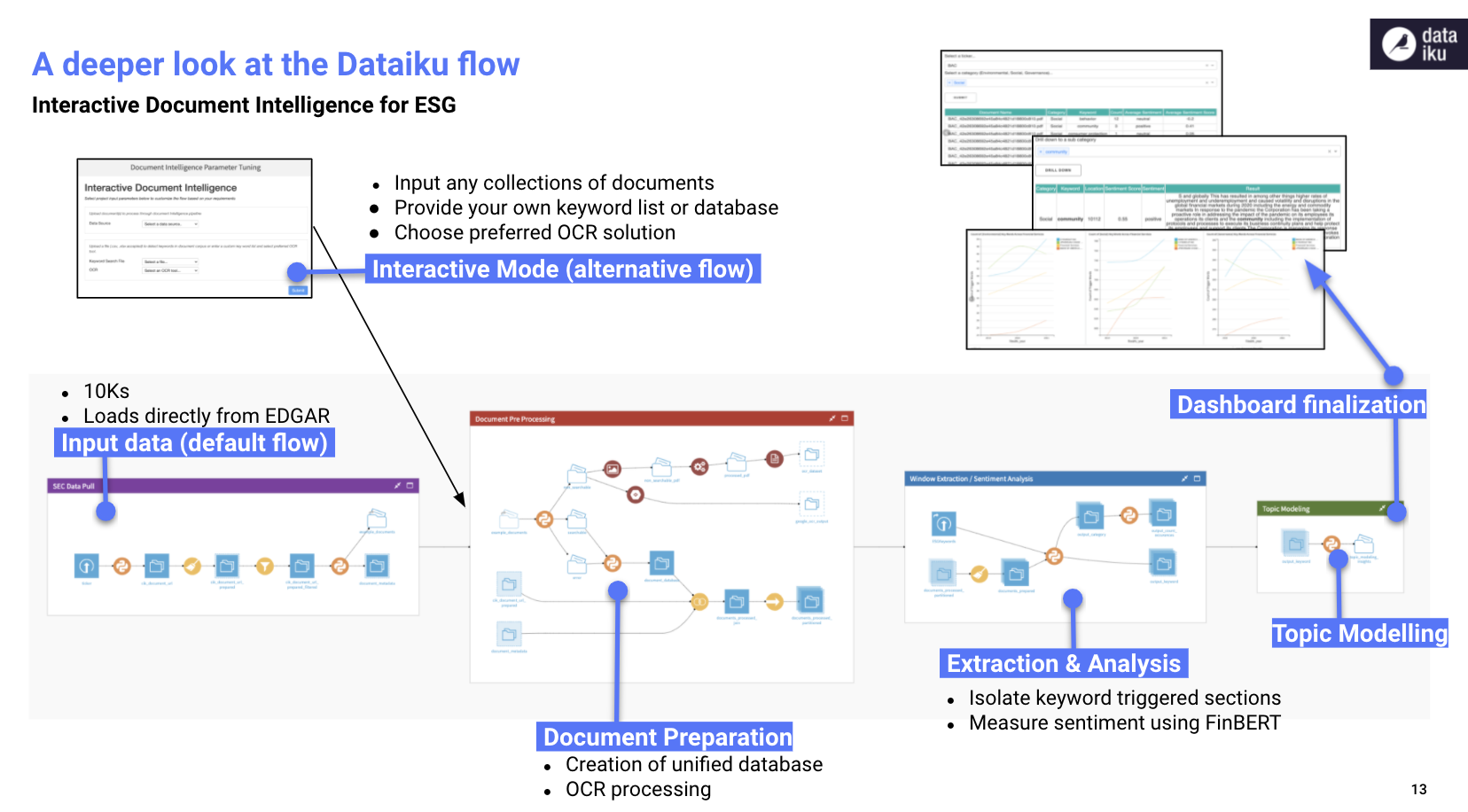
At a high level, this project accepts a document corpus (digitized and native images) as input. A pipeline then digitizes each document, extracts its text, and consolidates the entire text corpus into a unified and searchable database. After consolidation, we apply multiple NLP techniques to prepare, categorize, and analyze this textual data based on a theme of interest (in this project, ESG). The output provides business users with an interactive, purpose-built custom dashboard to analyze high-level trends and drill down into aggregated insights.
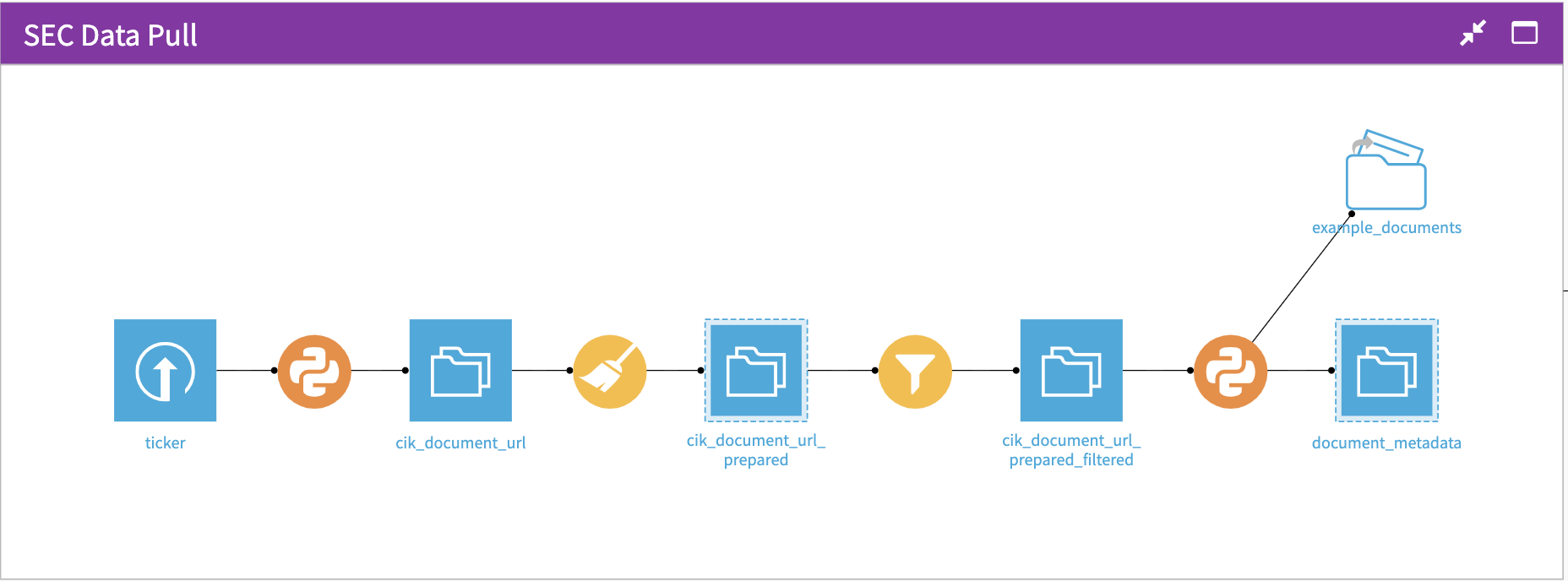
SEC Data Pull
We kick off the flow by obtaining a sample of 10-K filings from the SECs Electronic Data Gathering, Analytics, and Retrieval (EDGAR) system. A custom Python recipe calls the EDGAR API to find the associated 10-K reports from about 12,000 stock tickers. From there, a filter is applied to subset the 10-K reports that will be run through the pipeline for downstream analysis as well as associated document metadata (e.g., filing year, CIK, SIC Description, etc.).

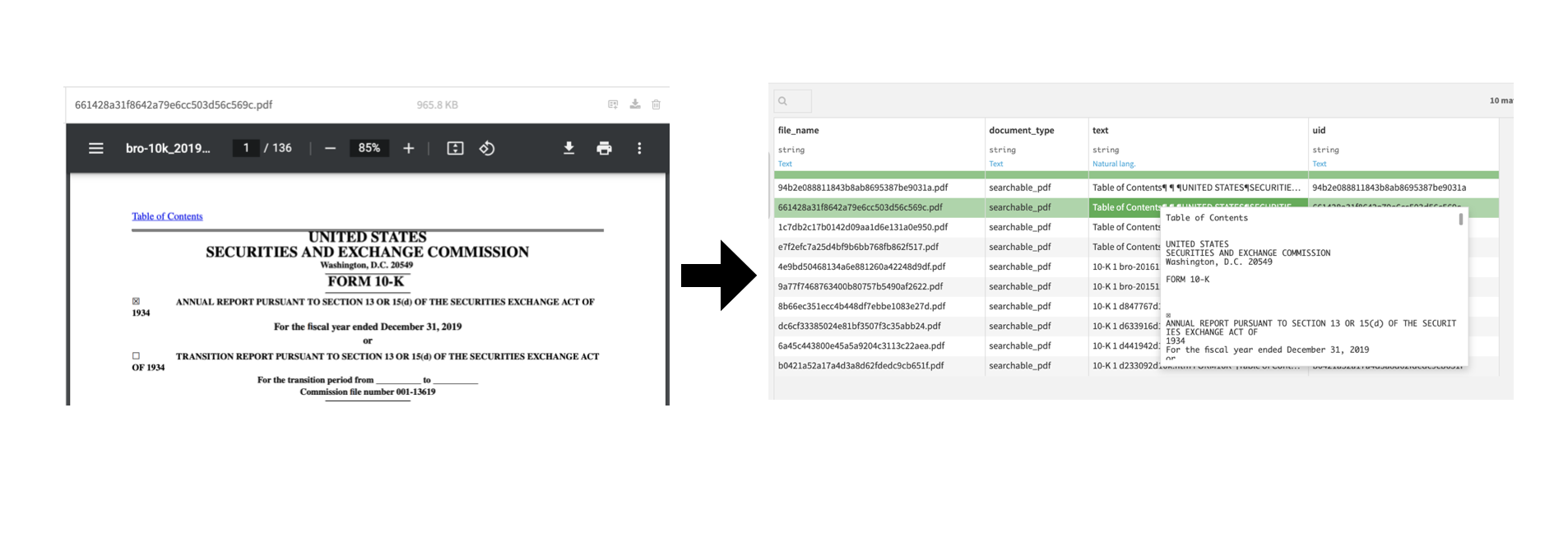
Document Pre-Processing
The document pre-processing flow zone includes document classification and digitization. Since the document repository can include various file types (e.g., pdf, jpegs, png, tiffs, etc.), each document is first classified as either digitized or a native image. For digitized documents, PyMuPDF extracts the text layer from the document. For images, we perform Optical Character Recognition (OCR) to transcribe the text from the image using the Dataiku Tesseract - OCR Plugin. While the flow uses Tesseract, this can be customized to use any OCR engine based on preference. The final step is to join all processed documents into a dataset for NLP analysis.
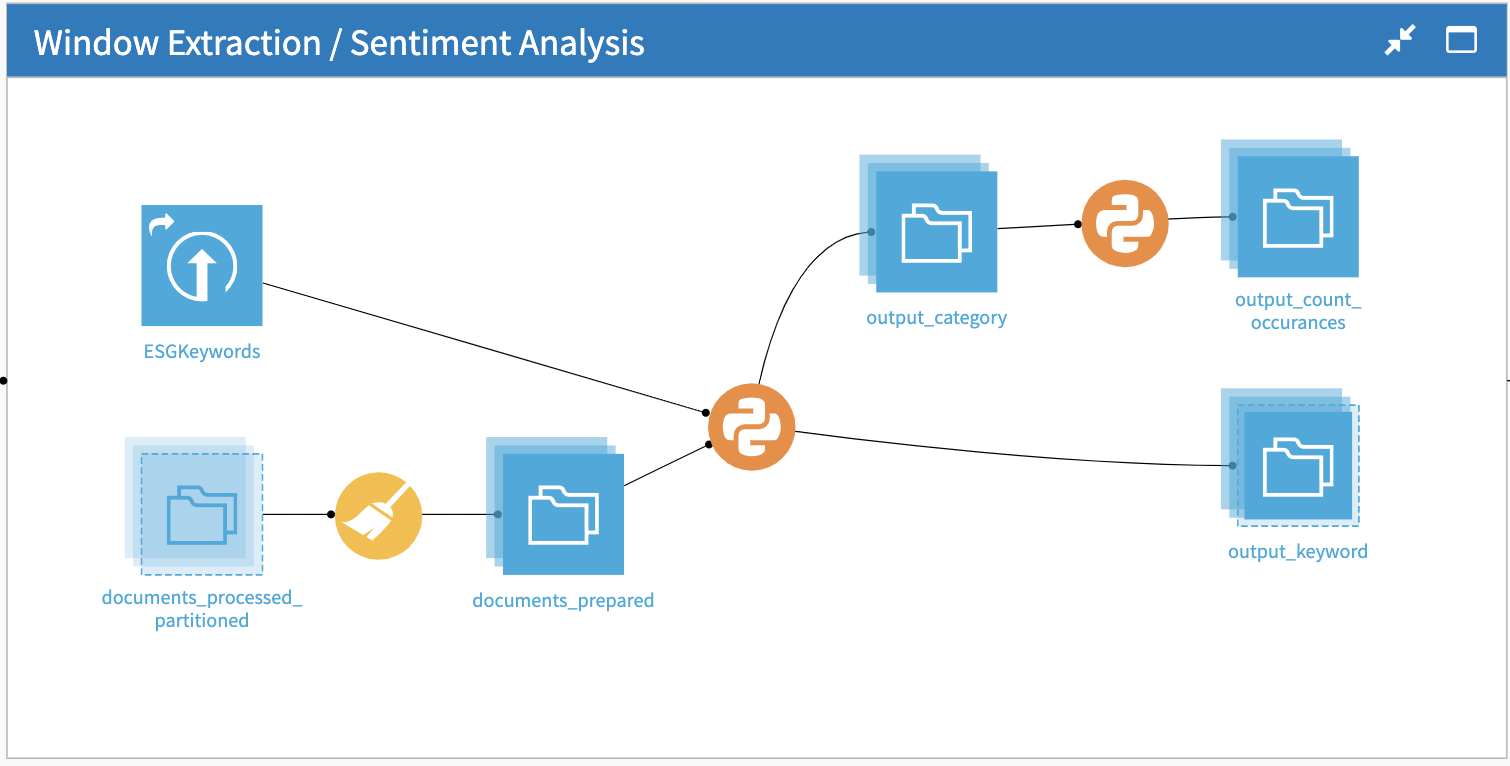
Window Extraction / Sentiment Analysis
In this example, we apply two NLP techniques, keyword search and FinBERT sentiment analysis, to understand what companies are saying in regards to their ESG goals. For keyword search, a search file of common terms is the input to a custom Python recipe to find relevant paragraphs from the 10-K corresponding to E, S and G, respectively.
Each window is then sent through a pre-trained FinBERT model to analyze the sentiment. FinBERT is a domain-specific language model developed to capture the nuanced language often found in financial documents. In fact, there are multiple industry-specific pretrained BERT models such as SciBERT, BioBERT, and even ESG-BERT! The output includes a predicted sentiment score between -1 and 1 and a corresponding sentiment label of positive, negative, or neutral. An additional code recipe is applied to aggregate the total amount of references to these keywords per E,S,G category.
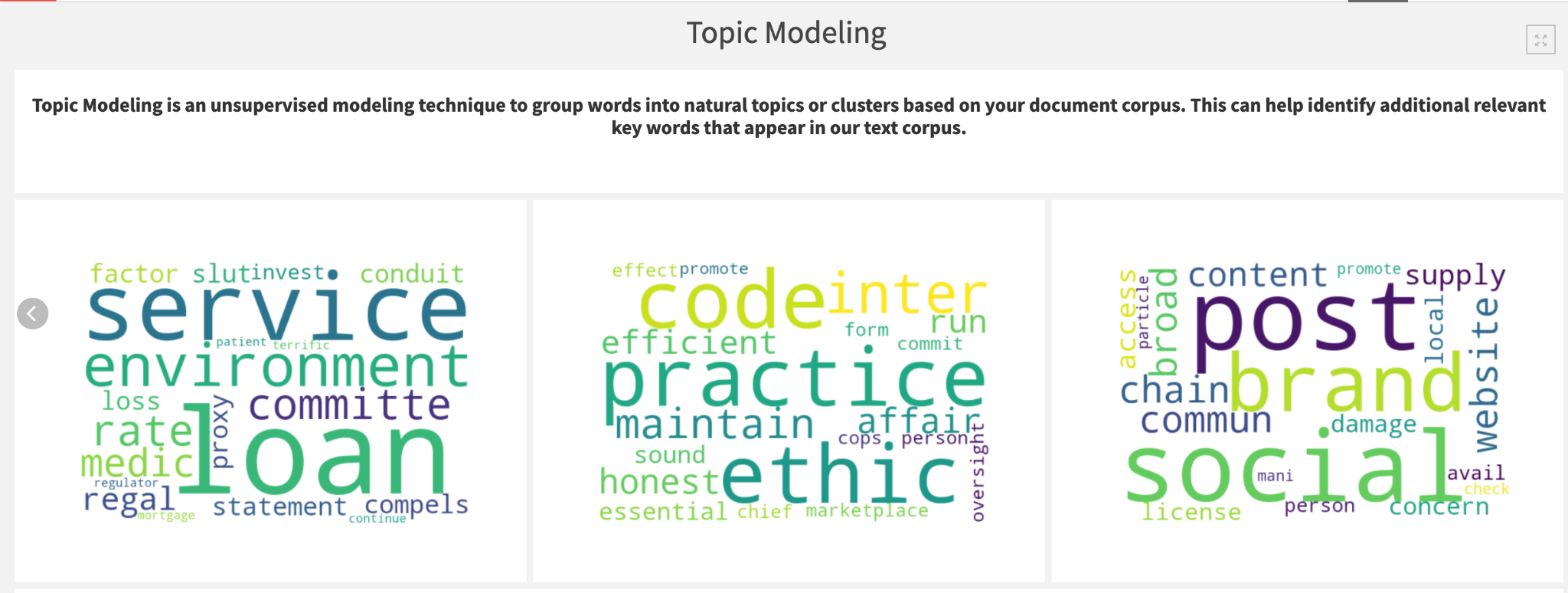
Topic Modeling
The final flow zone leverages an unsupervised modeling approach, applying an LDA topic model to the extracted text. Topic modeling is a common technique used to unveil abstract topics in a document text corpus by classifying documents with similar words and word frequencies into the same topic cluster. In our example, we set n_topics=3, requesting our model to look for three topics in hopes of natural clusters of E,S,G emerging. From here, we generate a word cloud for each topic to visualize the most frequent words that appear.
Dashboard Analysis
We publish all curated NLP analysis insights into interactive dashboards for business users to analyze high-level trends and drill down into areas of interest. We are able to search a company name, select a category (or multiple categories), and view the model results. We can drill down into a sub category to observe the extracted windows from the document as well as the sentiment score. The dashboard also includes time series frequency analysis to track how the frequency of keywords and sentiment has changed overtime. We can analyze the word count and frequencies around the ‘clusters’ of words that result from the LDA topic model, revealing new insights and perspectives.
And Just Like That, From Passion Project to Business Solution
{kind=link}
Despite the fact that my quest to find the top companies investing in sustainable finance is still ongoing, this project provided me with a larger realization — many companies want an automated way to sift through a large document corpus and extract keywords, phrases, or provisions. While I tackle a use case in the financial services space, the project's approach and modular design allows it to be readily applied to other industries. Each element can be adjusted or enhanced to suit the needs and preferences of a given use case. For example, the keyword search process is customizable to use your own list of keywords or a database of terms! Be sure to check out the project in the Dataiku project gallery here.
If you found this interesting, I invite you to sign up for the webinar, Interactive Document Intelligence with NLP, on October 20 where I will demo this solution in action as well as answer any questions you may have in regards to NLP and Dataiku. Until then, I encourage you to explore the Interactive Document Intelligence for ESG solution, the latest industry solution for financial services!