




Nowadays, there seems to be only two ways to correctly perform A/B tests. You can trust the black boxes from dominant platforms like LinkedIn and Facebook, whose testing APIs are powerful but increasingly opaque. Alternatively, you can do it by yourself and follow the best practices that seem to have been set in stone by the never-ending list of articles on the subject, such as “no peeking” or “segment your population beforehand.”
What if there was a third way? A way where understanding the statistical model behind your test endows you with the ability to prepare for the worst by taking extra precautions but also to hope for the best by taking calculated risks?
In this blog post, we outline the statistical tests at stake when performing an A/B test that replaces the text of marketing email campaigns with shorter copy. We explain how to set the parameters of the A/B test and how this approach can help us make better decisions.
Eyes on the Prize
A/B testing is an experimental design used to compare a reference variant against a testing one and measure the difference between their performance. This test process starts with the definition of the performance indicator to compare between the two variants. It is key to select a metric that is relevant with respect to our test but also one that brings the best statistical guarantees.
A good indicator is well correlated with the variant — it has a low noise level and is not influenced by external factors. Further, its cardinality must be as high as possible. For instance, in our email campaign, the click-through rate is the best indicator. We do not expect the open rate to be impacted by the length of the text and, although it denotes better engagement, the rate of people actually subscribing to the advertised event is too low to be our only indicator.
Finally, we are going to use a statistical test that measures the difference between distribution parameters. For this purpose, knowing the distribution followed by the values and their parameters (such as variance or homoscedasticity) increases the power of the test. In our case, we will analyze the clicks of users that follow a binomial distribution.
After picking the relevant metric, you may choose which variants to compare. If you aim at understanding the workings of your campaigns, the choice of the variants should be intentional. Which format do my recipients prefer? When is the best send time? It is worth focusing on one variation per experiment if you want to know which variation results in an uplift? For example, one may not want to change the send time and subject line of an email campaign at the same time because it is not possible to determine which parameter is responsible for the outcome. Once the goal of the experiment is defined, you may choose which test to use.
Defining Our Comparison Hypothesis
The role of the validation test is to determine if the difference observed between the metrics is due to chance or to our action. Explaining how to perform statistical testing is way beyond the scope of this blog post (it is actually the subject of whole books) so we will focus on how to choose and use one. This blog post focuses on measuring differences between binary signals such as click or conversion, therefore the metrics involved are proportions of success like conversion rates and click rates.
To apply testing, it is first assumed that samples are independent from each other. It means that the outcome of the test for one user does not influence others. As the experiment measures if a variation leads to a success or failure of an event, such as the sending of an email, it can be modeled by a Bernoulli distribution. A Bernoulli distribution is a very simple distribution parameterized only by the probability of fulfillment of a given event. If X follows a Bernoulli distribution associated with probability p, we can write:
Since we are dealing with two different groups, we note pA and pB, the true success probabilities for each group. These parameters are unknown. Let’s note the sample sizes nA, and nB, and the total sample size, n, n = nA + nB.
We define both our hypotheses: H₀, the null hypothesis assumes that the variant is as efficient as the reference, hence pA = pB. H₁ states that the difference is significant, hence that the probability of conversion of the reference pA is inferior to the one of the variant. We define the test as follows:
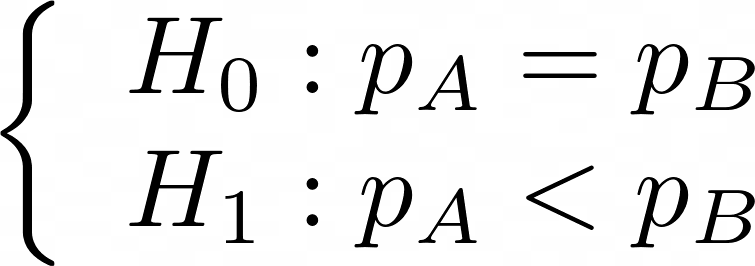
Choosing the Validation Statistical Test
The reference test for binomial distributions is the binomial test. It is defined as:
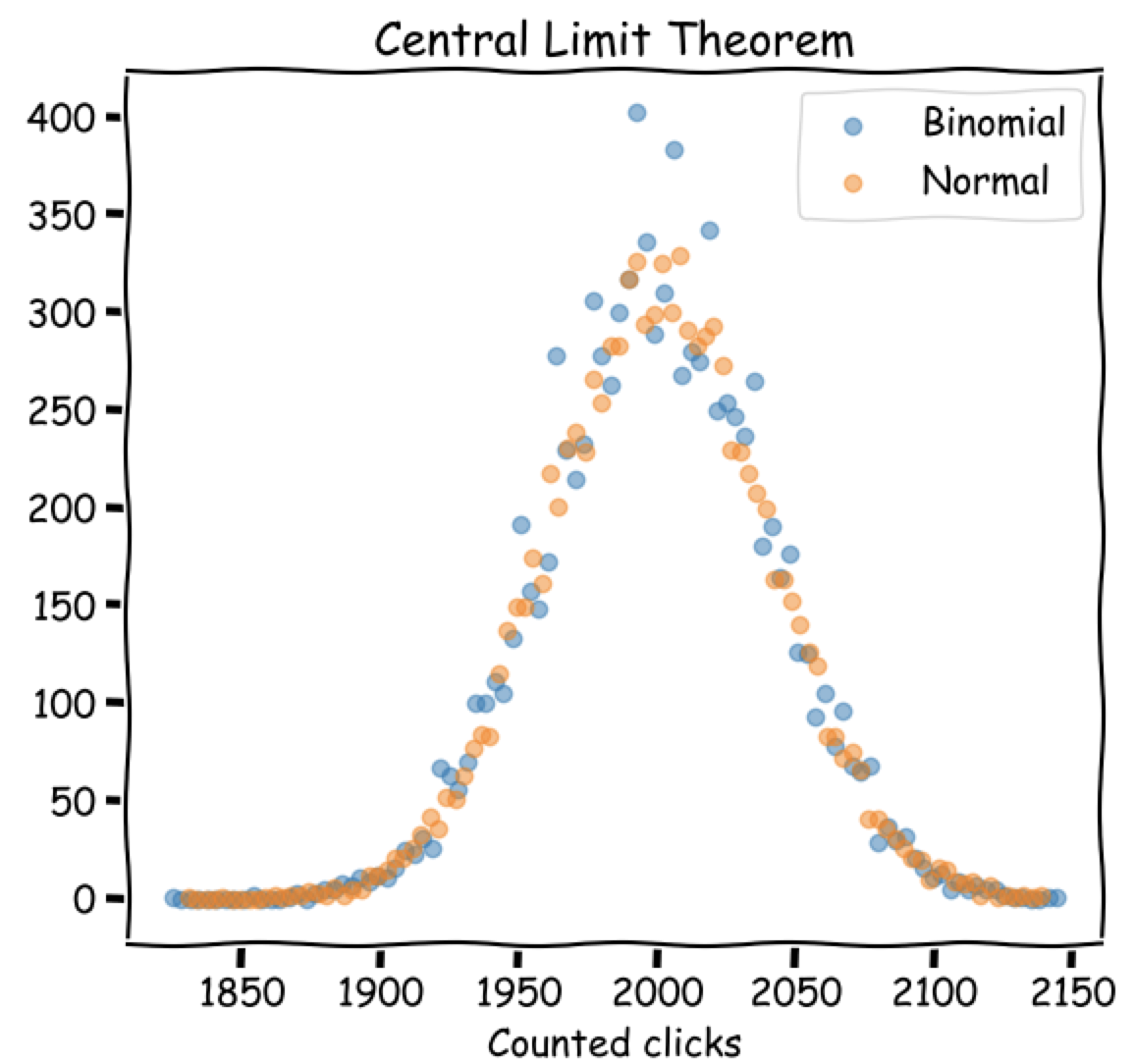
Unfortunately computing (n k) is prohibitive for large values of n. Fortunately, the Central Limit Theorem tells us that a normalized sum of several independent random variables, regardless of their distribution, follows a normal distribution.
In the specific case of binomial distribution, given that np > 10 and n(1-p)> 10, the sum of all clicks in our population follow a normal distribution parameterized by:
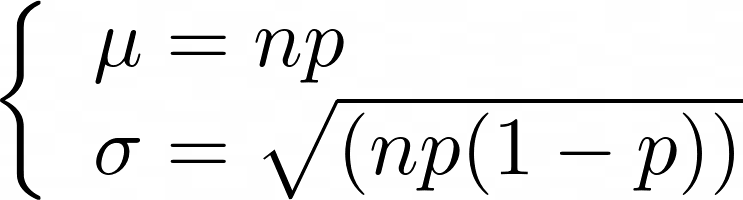
It is easy to check this theorem in practice by simulating users following as random variables after each distribution. We see here that the outcomes of simulated experiments are very similar:
Since we assimilate our results to a normal distribution, we can now use the Z-test that applies to normal distributions. This test allows us to test if a variant is better or worse than a reference in its one-tailed version or both of them at the same time in its two-tailed version.
Size and Choice of the Test Population
Would you trust an A/B test run on six users? Probably not. How about on 1,000 users? This seems better. How many people should the test be run on to sound trustworthy? In order to determine the minimum required sample size, we need to first define the guarantees we want:
- The minimum detectable effect, written 𝛅, is the size of the effect we want to measure. This is usually determined in collaboration with the business. For example, if the variant is more costly than the reference, the minimum detectable effect must be chosen so that this effect brings more uplift than this additional cost.
- The Type I error rate, written 𝝰, determines the risk to detect a significant change while there is not. A value of 5% is usually advised.
- The Type II error rate, written 𝝱, is the probability to fail to detect a change when there is actually one. Note that statisticians usually do not refer to 𝝱, but to (1 - 𝝱) which is called the power.
When all these quantities are defined, one can take a quick look at the formula of the minimum sample size for a Z-test:
This formula is very important because usually the number of samples is a limiting factor of the experiment. One could not let an A/B test run for several months. It is therefore time to play with the parameters evoked before. Note that the critical values of the Z-test do not evolve linearly:

Depending on your business case, you can play with different parameters.
- 𝝰 is related to the cost of deployment, operation, and maintenance of the variant.
- 𝝱 and 𝝳 are related to the cost of missed opportunities. Business analysts can usually help define the costs relative to your use case.
You can check out this A/B test calculator web app to observe their impact on the minimum sample size. Regarding the probability p, namely the baseline success rate, the probability observed in the reference is usually a good guess. In the formulas below, pA(1-pA) is maximized for pA=50%. This value can be used in a worst case scenario.
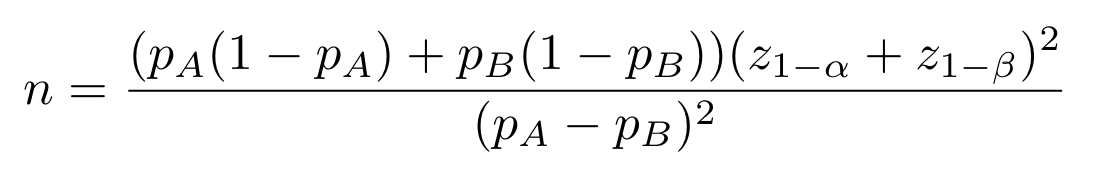
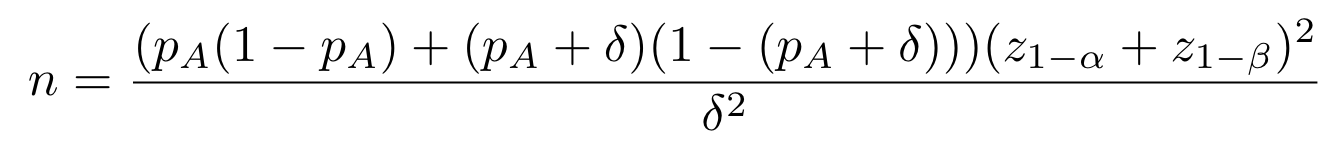
Finally, this number is based on numerous assumptions made on the data. We expect independence between samples, for example, but this may not hold in practice. In our case, a prospect of population B could forward his mail to a prospect of population A. Some prospects may also have registered with their personal and professional email addresses and received both emails. In order to test our hypothesis, it is common to run A/A tests and observe the rate of false positives for example.
Population splitting: Once the number of required samples has been set, one must choose how to split the populations. It is required for both populations to be exchangeable. This means that they should have the same reaction when exposed to each variant. This property is essential for the validity of the test. However, for most A/B tests, a random splitting of the users in both populations is sufficient. In most settings, it is usual to perform a 50/50 test in order to increase the statistical significance of the test.

Results of the A/B Test: Time to Jump to Conclusions
Now that the experiment has been run, it is about time to draw some conclusions about its results. We get two values out of the A/B test:
- The p-value of the Z-test is the probability to observe the obtained results if there were no difference between the variants. Usually, the null Hypothesis H0 is rejected for a p-value below 10% or 5%.
- The new conversion probability measured on the variant. This gives the size of the increase induced by the variant. This can be used to estimate the additional revenue generated by the variant.
If the answer to the test is conclusive, it is time to open the champagne and celebrate! Otherwise, it does not mean that the test is not positive, it just means that we failed to prove it significantly.

It is therefore still possible to take action:
- In the case of our email campaign, the p-value was 20% so the test was inconclusive. However, given that obtaining a similar performance with a shorter email is a win per se, we have decided to roll out the feature.
- If the test is not conclusive on the whole population, it may still be on a smaller one. For example, we could expect our shorter email to have more impact in countries where English is not an official language since people may spend more time and energy reading an email in English. We could therefore restrain our study to this population afterward, in a process known as a post-hoc analysis. However, as performing several statistical tests increases the chances of false positives, it is therefore advised to correct for multiple comparisons.
More compelling though, the answer to an A/B test might help define best practices. This is the most insightful step for operational teams, as it addresses the real issues that they are facing. What can we learn from the success or the failure of a campaign? How should I adapt my next campaigns to make them more successful?
By bringing statistical and business evidence, a traditional A/B test fosters an understanding of the changes at stake, which are often missed by automated tools. For instance, by A/B testing different formats of video ads, we were able to determine guidelines for future online campaigns.
Hindsight About A/B Testing: Let's Take a Step Back

{kind=link}
Planning extra-time. In the previous section, we computed the number of samples necessary to validate our hypothesis. However, necessary does not mean sufficient and we never know what can happen during an A/B test. For example, part of the population can be excluded afterward because of technical problems (such as both mails being sent to them by mistake). We may also want to perform post-segmentation analysis as described above. For all these reasons, it is considered good practice —once the minimum number of samples has been decided — to plan for extra A/B testing time.
No peeking. Peeking consists in looking at the results of the A/B test during the experiment. This is a very bad habit in frequentist A/B testing, as it leads to making decisions on partial data, while can increase the rate of Type I error. If early stopping is necessary, Bayesian approaches are said to be more robust to peeking although they are not immune to it. Stay tuned for a step-by-step post about how you can use Dataiku to A/B test your marketing campaigns smoothly!