




A long time ago in a galaxy far, far away…
It is a period of uncertainty for sales forecasting. With the upcoming Life Day holiday season, it is difficult to plan how many products will be sold on each planet ahead of time. The data team at STARMART, the largest retail chain in the galaxy, has started a task force to provide the store managers of each planet with detailed forecasts per product.
The IT department managed to install the data professionals’ ultimate tool, DATAIKU, an end-to-end platform with enough features for data scientists, engineers, and business experts to work together and build machine learning pipelines from raw data to predictions.
With a tight deadline to finish the first Proof of Concept in a week, Mara, the data scientist, races to get started with DATAIKU, using time series capabilities that can save her time preparing data, analyzing it, and training forecasting models in a few clicks.
Data Preparation: Getting the Dataset Ready for Use

Hello there… Mara speaking, here to explain how I completed this fun mission!
It all starts with one dataset: weekly sales for 50 planets and 100 products (lightsabers, speeder bikes, hoth chocolate, etc.) over two standard years.
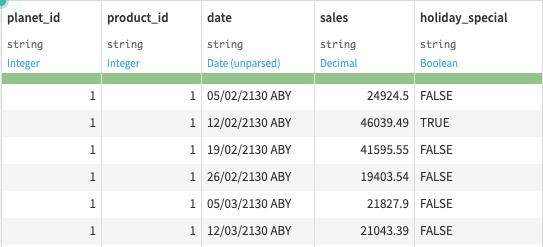
Initial sales dataset
Let’s begin with a bit of data preparation to get our sales dataset clean and ready to be analyzed.
The first step is enrichment. For each row, we want to know the name of the product and the planet to make our future analysis easier to interpret. We simply use the Join recipe to join the sales dataset with the product and planet datasets (via lookup tables between product/planet id and product/planet name).
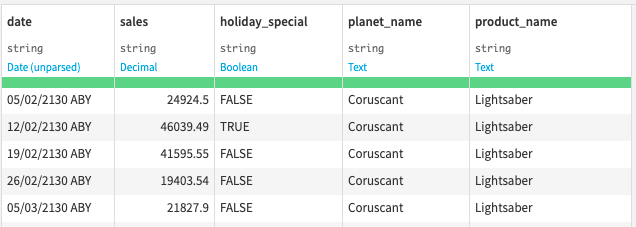
Output dataset of the Join recipe
Next, let’s do some cleaning so that our data has the expected format for our time series analysis tools. We parse the dates, set the correct data types (double for the ‘sales’ column and int for the ‘holiday_special’ column) and reorder the columns so that the table is easier to read. It can all be done in one Prepare recipe.
We also want to remove the combinations of product/planet for which we have too little history. We use the Window recipe: For each pair of product/planet, we compute the number of observed dates and then filter on pairs that have at least 100 observations (i.e., two years of history).
Last but not least, we need to resample the time series. Our time series have missing values (dates for which we have no observation) that we need to fill so that all the time series have a regular date range. Fortunately, we can use the Resampling recipe from the time series preparation plugin that will make this task very easy.
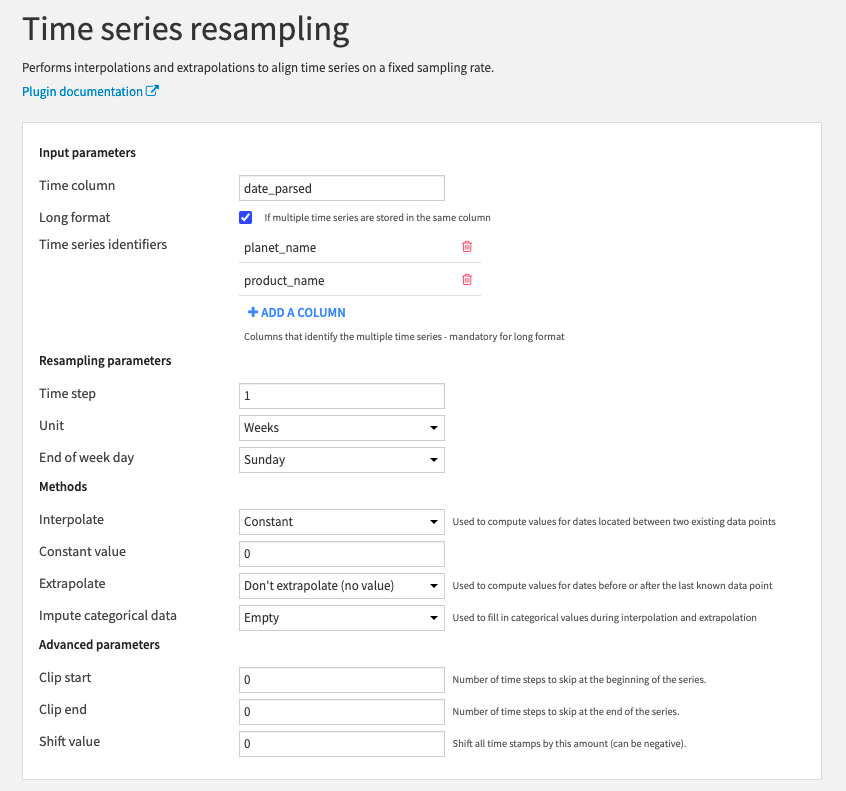
Settings of the Resampling recipe
Visual Analysis: Understanding the Time Series

Before going into forecasting, let’s have a look at the correlation between product sales across planets. We will use the Pivot recipe to get the data in the right shape and then generate a correlation chart. Fortunately, there is a predefined notebook for that, which we adapted to our needs and turned into a Python recipe.
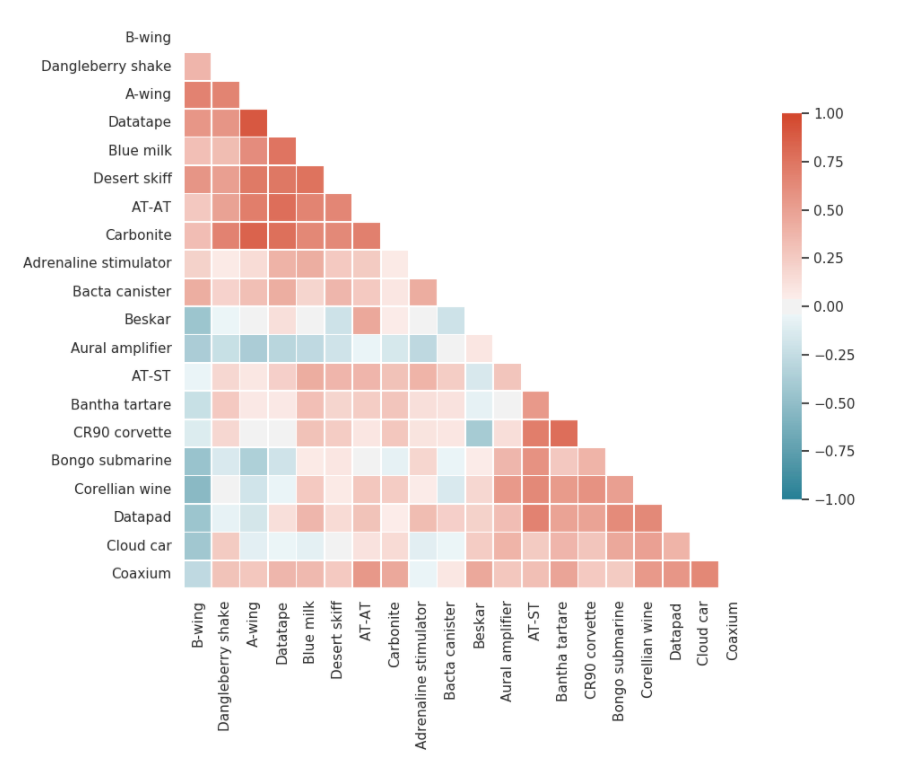
Correlation charts of products across planets. Values around 1 (red color) represent highly correlated products whereas values around -1 (blue color) represent negatively correlated products. Values around 0 are uncorrelated products.
Interestingly, we observe that the sales of CR90 corvettes are positively correlated with the sales of Bantha tartare. We could leverage this correlation with a joint marketing campaign.On the contrary, Corellian wine and B-wings are negatively correlated. We may need to investigate it a little bit more.
Forecasting: Predicting Future Sales

Now that we have spent 80% of our time preparing and understanding our data, we are ready to tackle the modeling part.
To speed things up, we use Dataiku’s forecast plugin. It helps automate the training, evaluation, and deployment of forecasting models using both deep learning and statistical time series approaches — all without requiring us to write custom code.
As you can see on the interface below, we can take advantage of a few specific features of this plugin:
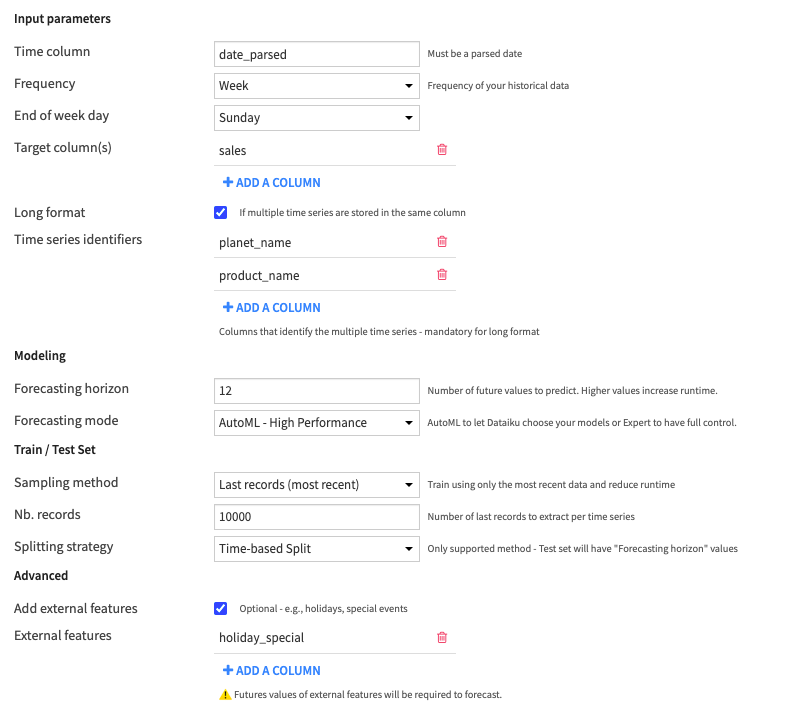
Settings of the "Train and Evaluate Forecasting Models" recipe
Multivariate forecasting
- We activate the Long format parameter and pass our planet_name and product_name columns as time series identifiers.
- This will allow deep learning models to learn from patterns across our different time series (e.g., sales of lightsabers in Coruscant and sales of jedi robes in Tatooine)
AutoML
- We use the built-in “AutoML - High performance” mode to train and compare multiple models automatically.
- This mode will train two powerful deep learning neural networks for forecasting: DeepAR and Transformer.
- For benchmarking purposes, these models are compared to two baselines: a “Trivial Identity” model which predicts that the next 12 weeks will be the same as the last, and a “Seasonal Naive” model which repeats the seasonal pattern of the last 52 weeks.
External features
- We pass the holiday_special numeric indicator as an External feature to allow models to better learn the spiky pattern related to these dates.
- Note that future values of this external feature will be required to forecast.
After a few hours of gradient descent on our CPU-enabled server droid, our models finished training! To understand which model performed best, we created the following chart on the performance metrics dataset output from the previous recipe.
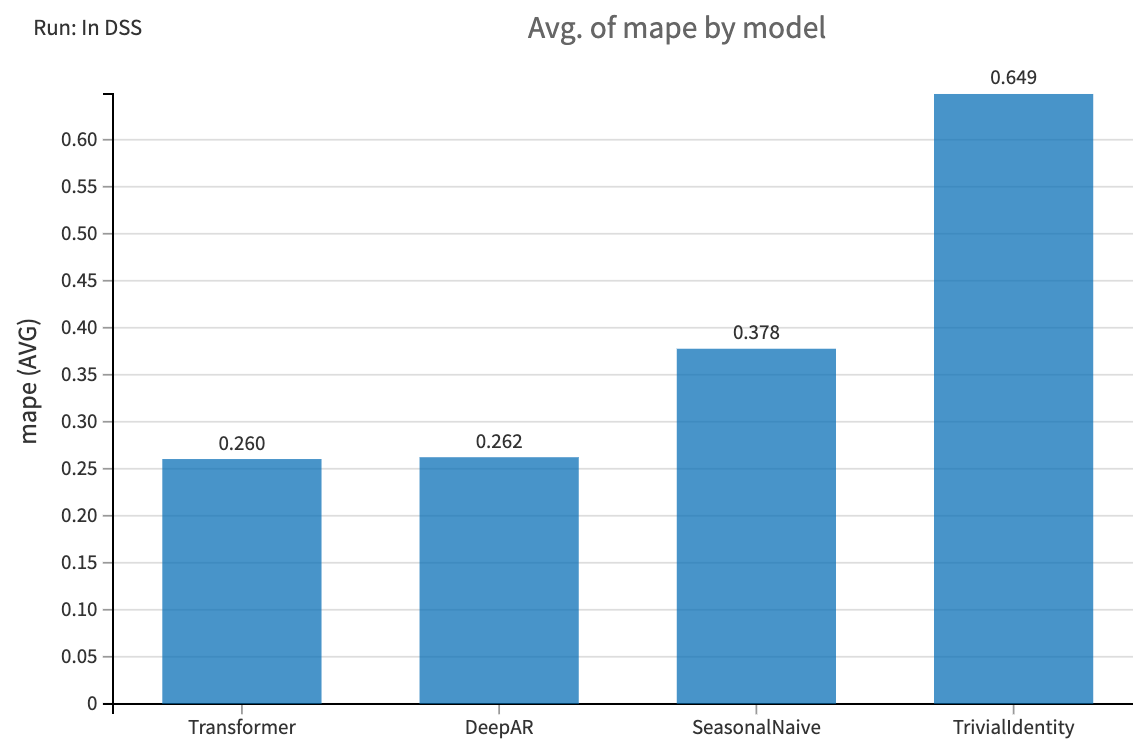
Comparison of the MAPE metric across models, evaluated on the last 12 weeks of historical data
We use the Mean Average Percentage Error (MAPE) as our evaluation metric. The Transformer model appears to be the best, with an MAPE of 26% across all planets and products. This is a significant improvement compared to the Trivial Identity model, with a MAPE of 65%.
We need to be mindful that this metric is computed at an aggregate level. While most time series are predictable, some may be harder to forecast, so let’s drill down into the performance of the Transformer model on each time series.
First, we investigate on which planet and for which product our model is struggling. Interestingly, dice sales are highly unpredictable, with an MAPE of 564%. This may be of interest to the purchasing manager in charge of this rather random product. We also notice that our model is performing rather poorly on Kamino. I have a bad feeling about this… We should definitely check with the Kaminoan sales manager to understand what’s going on!
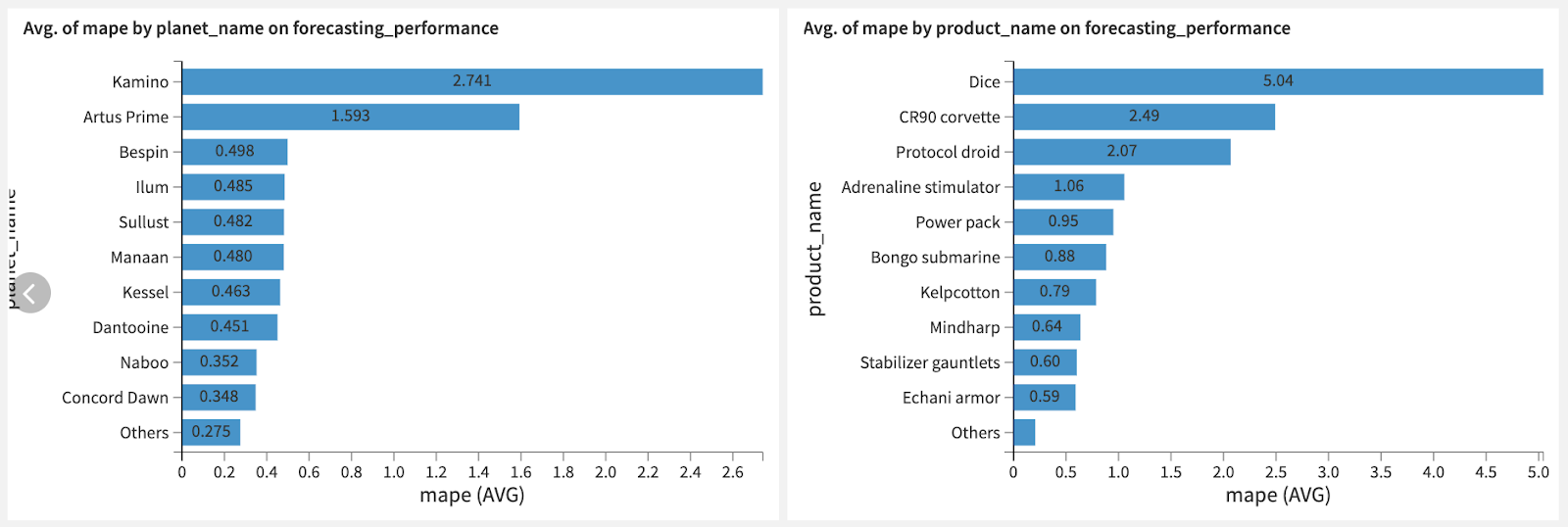
Evaluation of top errors per planet and per product for the Transformer model
Second, we build a pivot table of our model performance per planet and product. This will be a tool for sales managers to know where they can trust the model prediction and where they should apply caution and “trust their instincts.”
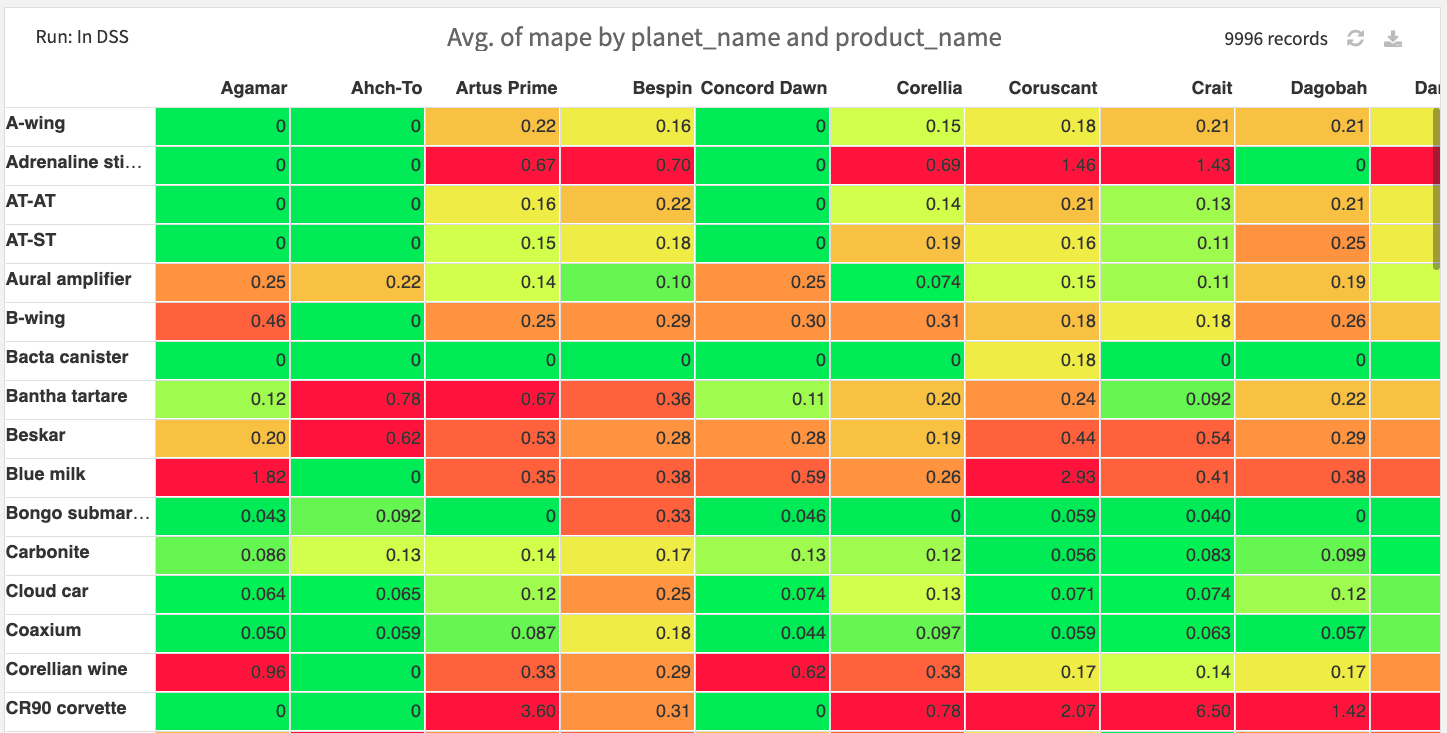
Pivot table of error metrics per planet and product for the Transformer model
Voila! Our model is finally ready for deployment. For that, we use the forecast future values recipe of the forecast plugin.
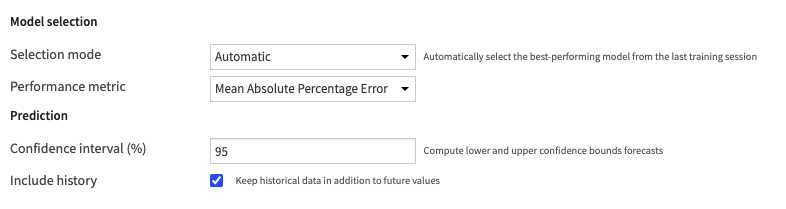
Settings of the “Forecast future values” Recipe
This recipe outputs a dataset with the prediction for the next 12 weeks, along with 95% confidence intervals. We use it to create a time series chart per product and planet, for each store manager to see her forecasts.
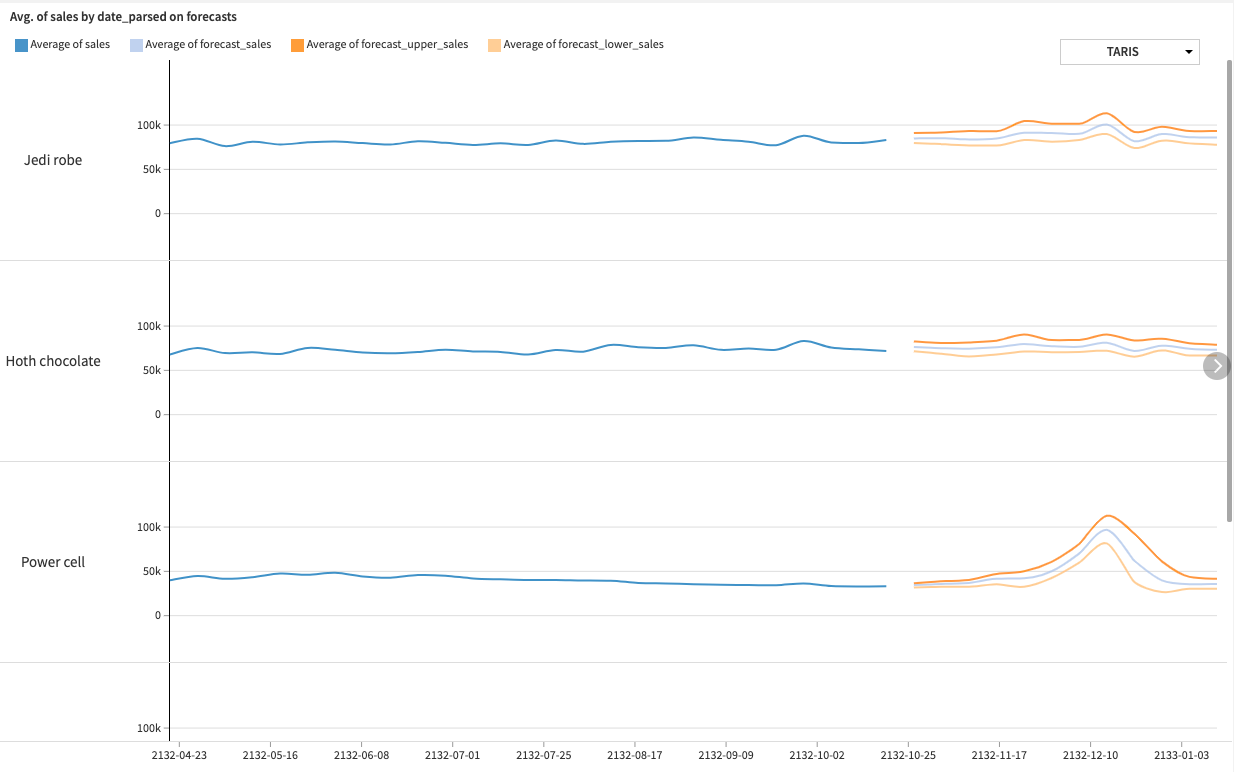
Time series chart of forecast and confidence intervals per product and planet
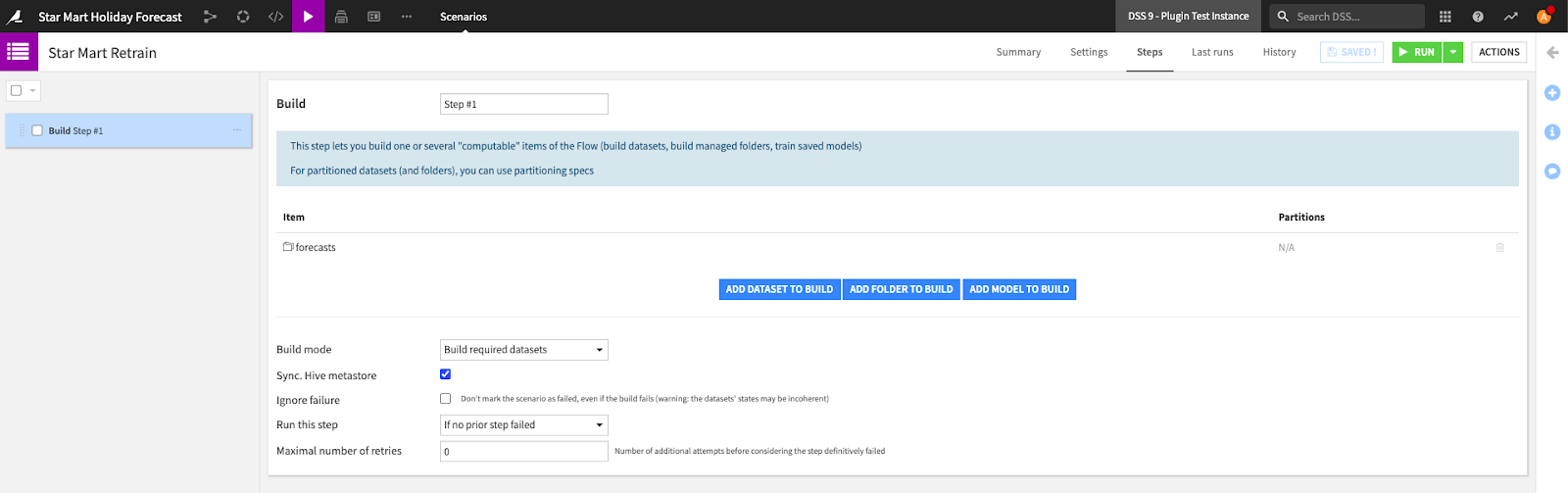
Finally, let’s get this pipeline ready for production. With Dataiku, it’s as simple as creating a scenario which rebuilds the final forecast dataset. Rebuilding this dataset will automatically run our pipeline from data preparation to forecasting.
The forecast plugin is designed for production: when running recipes for a second time, it automatically retrains models and uses the best model from the last training session to forecast future values.
{kind=link}
Dataiku scenario to retrain our forecasting models
This scenario will run the entire pipeline every weekend: prepare the new data, train forecasting models, evaluate them in the last 12 weeks, select the best model, and predict the next 12 weeks. The dashboard with the charts for the sales manager will be automatically updated as the underlying data changes.
Conclusion
We were able to complete the Proof of Concept in less than a week. We went from raw data to models ready for production and for business users to consume. More importantly, we were able to find interesting business insights on sales of specific products and planets and to showcase them visually.
It was also helpful to find the best of both worlds: visual interfaces and code. Preparing data and training models can be done in a few clicks. And when a specific analysis demands it, you can write your own code. You can mix both, while having a single overview of your data and model pipeline!
As next steps to improve our pipeline, we are thinking of the following ideas:
- Using the forecast plugin’s expert mode to tune the forecasting model parameters ourselves
- Try out the GPU version of the plugin to train deep learning models even faster
- Add data checks to ensure new data coming in is still valid
- Configure email notifications on our scenario to alert sales managers of their new forecast
- Push our project and its scenario to an Automation node
May the Force Be With You!
