




{kind=link}
We are all inquisitive about alternative scenarios, perhaps it’s simply in our nature. For example, one may wonder what their salary would be had they chosen a different major in college; another person may daydream about what the world would look like if there were no conflicts among nations; finally, a more practical question someone may ask is whether or not they would have missed their train if they had left home five minutes earlier.
Businesses are also naturally interested in these questions. For example, a gym owner might want to know whether a given customer would be more likely to renew their yearly subscription if they were offered a discount. A phone manufacturer would certainly be interested in knowing whether increasing the price of its lead product or not would yield greater profits.
All of these questions are inquiries about the causal effect of an action or “treatment” on some outcome of interest. The scientific discipline used to answer that type of question from data is called Causal Inference (CI).

CI is arguably more difficult to comprehend than classical machine learning (ML). It requires more constraining assumptions and uses different modeling techniques. Attempting to infer causal effects using the standard ML toolbox on observational data (i.e., data where the treatment variable is not controlled by researchers, usually encountered by data practitioners) is likely to give misleading results with unpredictable outcomes.
To introduce CI, we will work with an example of one of its most common applications: uplift modeling. Uplift modeling is prominent in the field of marketing and is seen as an improvement over classic churn modeling.
Churn Modeling: An Example
Consider a large fitness company with multiple gyms across the U.S. To maximize profits, the company must not only try to go after new customers but also make sure existing customers renew their yearly memberships. To maximize membership renewal, the company's data scientists use historical data to train an ML model to predict a customer churn target as a function of various customer characteristics (age, gym check-in history, etc.). The model is then used to score existing customers and obtain individual probability of churn. Those scores serve as the basis for the selection of which customers will receive a discount as an incentive for them to renew their membership.
What we just described is a classic churn modeling use case. Although this churn model helps predict whether or not a customer is at risk of churning, it provides no indication as to whether that customer would react favorably to the discount. The latter is a job for uplift modeling.
There Must Be a Better Way: Enter Uplift Modeling
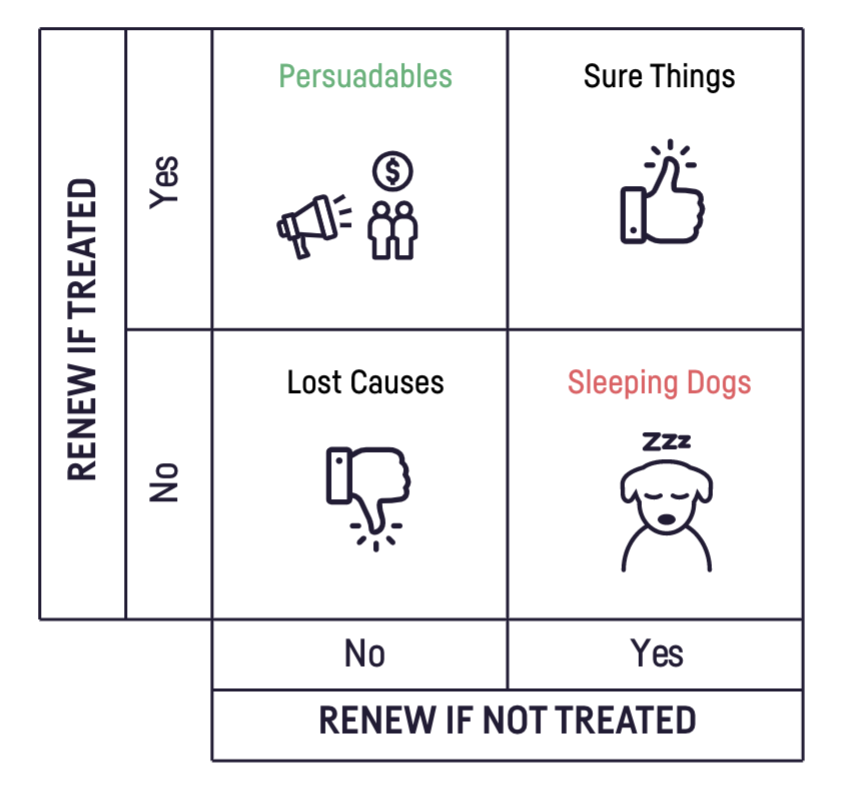
To know how each of its customers would react to the discount, the company would ideally need to know its customers' membership renewal status when they're "treated" with the discount as well as when they're left "untreated." In other words, the company would need to know two potential outcomes for each individual. The combinations of those two potential outcomes yields four customer types:
- Persuadables: These customers renew if treated and churn if not treated.
- Sure Things: These customers renew with and without treatment.
- Lost Causes: These customers churn with and without treatment.
- Sleeping Dogs: These customers churn if treated and renew if not treated.
The inability to observe counterfactuals is known as the fundamental problem of causal inference. This problem is ubiquitous in the field of CI. Thankfully, under some strong though mostly untestable assumptions about the data, this problem can be circumvented and customer uplift can be predicted:
Uplift = Probability Renewal(with discount) - Probability Renewal(without discount).
Customer uplift is defined as the effect of a treatment on the probability of customer renewal. An uplift model is any model — and there are many of them — that can be trained to predict that uplift. With a good uplift model, if a customer is predicted to have a positive uplift, we would expect the treatment to have a positive impact on the customer's likelihood of renewing their membership. The customer is more likely to be a "Persuadable."
One caveat is that those models are only as good as the data. Unsatisfied assumptions may result in errors in the predictions and misguide business decision makers.
What Are Those Crucial Assumptions?
We won't go over the details of those assumptions here, but refer the reader to this ebook if they want to learn more about them or CI in general. To train an uplift model, the company needs to run a campaign in which the treatment is assigned to some customers while other customers are left untreated. The assumptions govern how the treatment must be assigned to customers in that campaign.
One of them requires that any factor used to determine who gets or doesn't get the discount (e.g., age, or purchase history of the customer) and which affects renewal must be used in the uplift model. A scenario where this is unlikely is if discounts were given at the discretion of the staff working in the gym, because the staff may have information about customers that is not recorded in the data. For example, if the staff only gave the discount to gym goers who appeared highly motivated, uplift models will inflate the effect of the discount, as those highly-motivated customers are also probably more likely to renew their memberships. We have a positive bias in the uplift estimations.
Another assumption imposes that to predict uplift for a given type of customer — as measured by their observable features — that type of customer must have had a chance of getting the treatment during the campaign. If, for example, the discount was never given to older customers, uplift models won't be able to produce reliable predictions for that subpopulation. Fortunately, this assumption is testable, and groups that either always received the treatment or never received it can be detected. The best way to avoid all those potential biases and estimation problems is to randomize treatment assignments when possible.