




{kind=link}
This is the story of one of the most remarkable technological advances in AI from the last decade: the evolution of text analytics and natural language processing (NLP) from manual and tedious rule-based systems to semantically-aware models. In other words, computers’ relationship with human language has evolved from syntax-based to context-based, and from merely “processing” to nuanced understanding.
In this blog, we’ll explore how the text analytics narrative is changing courtesy of large language models (LLMs), and explain how NLP in Dataiku can help you enrich outdated document intelligence processes with the latest technologies so you can get more out of your unstructured, raw text data.
Tracing the Origins: NLP’s Formative Years
As we delve into the history of NLP, our story begins in the 1960s with the reign of rule-based taxonomies, predefined pattern-matching, and other linguistic processing techniques. These methods — when properly combined with a slew of prerequisite data preparation steps — allowed us for decades to perform useful tasks on unstructured text such as automated content classification, information extraction, and sentiment analysis. And while these traditional techniques do have their merits, the downside is that they are undeniably complex, labor intensive, and language specific.
In the late 1980s, the increase in computational power and the shift to machine learning (ML) algorithms heralded the arrival of the statistical approach in NLP: word embeddings based on occurrences or frequency, N-Grams, recurrent nets, long short-term memory units, and so on.
While these early models are certainly more flexible and better able to emulate how humans perform these same business tasks, these techniques still have major flaws. They are task and language specific, they can only be used with extensive preprocessing and numerous steps of text cleaning, and perhaps most importantly, they often miss nuances in human language.
Don’t get me wrong, this doesn’t mean that rule-based systems, tf-idf, and tree-based models in custom pipelines should now be disregarded for NLP applications, or that they have gone out of style — far from it.
For this reason, Dataiku maintains a full suite of text analytics capabilities that are not going anywhere! For example, Dataiku provides built-in processors for handling textual data as well as many plugin recipes which make it easy for both coders and non-coders to take advantage of popular services such as MeaningCloud, Google Cloud Natural Language APIs, Microsoft Azure Cognitive Services APIs, and Amazon Comprehend. Check out the full library of NLP-specific plugins here. Everything you need to visually prepare & clean your text data, handle text features for ML, and train and deploy your favorite models is included as part of Dataiku’s platform.
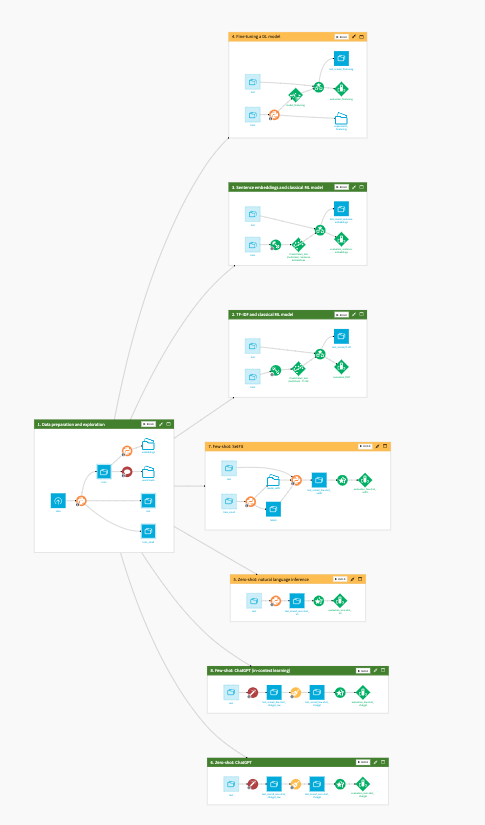 A project showcasing the diversity of technical approaches possible for language tasks
A project showcasing the diversity of technical approaches possible for language tasks
I simply mean that, without overlooking the past, one must adapt and embrace the future. When it comes to text analytics and document intelligence, the future is now, and it’s called LLMs. Let’s dive in!
Your Attention, Please
The evolution of LLMs can be traced back to early language models like Word2Vec and GloVe around 2013. However, the real breakthrough came in 2017 with the paper “Attention Is All You Need” from Google, which introduced the world to the attention mechanism, the transformer architecture, and paved the way for the emergence of pre-trained language models like BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pretrained Transformer), or T5 (Text-to-Text Transfer Transformer).
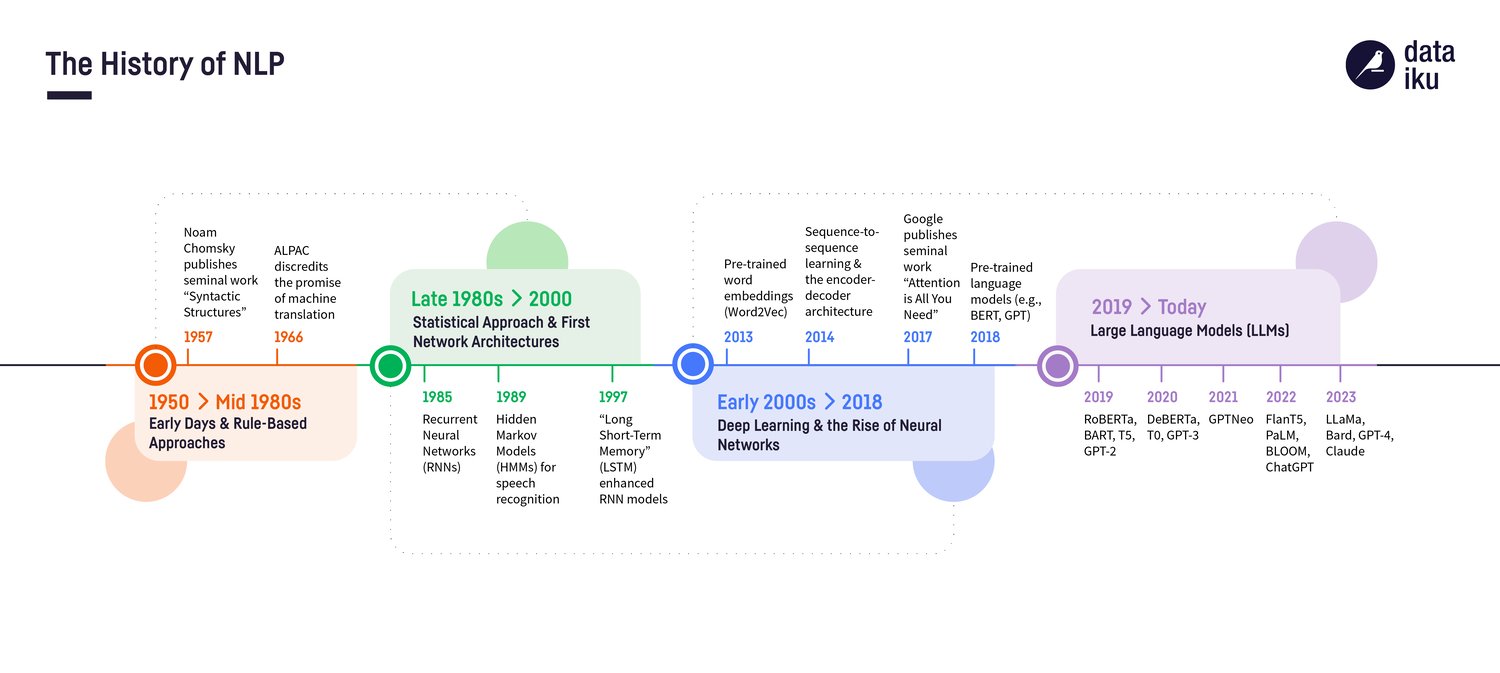
Because LLMs are trained on huge collections of diverse text, they are able to learn meaningful patterns, nuances, and intricacies of human language. On some level, we’ve basically taught these models how to read and understand all the major languages in the world!
One huge benefit to LLMs is that while copious amounts of preprocessing were essential to traditional NLP pipelines, these modern models require little to no text cleaning or preprocessing. The context-understanding nature of LLMs renders many preparation steps obsolete, not only saving significant time and resources, but also taking advantage of the full, unaltered text to deliver more meaningful results.
So what does traditional NLP’s metamorphosis into LLMs mean for your company? It means by combining traditional NLP tasks with emerging natural language understanding and generation (NLU/NLG) techniques, you can take your workflows to the next level. These powerful, multi-purpose models are the reasoning engine that serves as the missing link to help you drive better insights and business outcomes in fewer steps.
Still not convinced? Keep reading, and discover how Dataiku is the platform of choice to support you on your own transformation journey!
Leveling Up Your Game With LLMs and Dataiku
Whether you want to get things done in a few clicks with pre-built visual recipes, experiment with LLM prompts to get the perfect output for your task, build a powerful system to augment your prompts with an internal knowledge base, or a mix of all those, Dataiku has what you need.
As an example to illustrate the many ways to use LLMs at scale on your unstructured data, imagine you’re an insurance company looking to process claims more efficiently for improved customer experience and reduced overhead costs. A typical claims processing workflow revolves around a series of questions, including:
- Who is claiming what?
- What are the particulars of the loss?
- Is the claim genuine or suspicious?
- What coverage is applicable?
Before LLMs, those questions were tackled separately with dedicated ML workflows: a text classification model trained to identify the object of the claim, entity extraction pipeline to extract key details, anomaly detection model to spot potential insurance fraud patterns, and a heavy manual effort to cross-check the claims against your customer’s policy and terms of coverage … all of which must be run before ultimately responding to the policyholder.
Add to that countless steps of text preprocessing and multiply by several languages, and the result is a labyrinthine, brittle, and barely maintainable system. Today, a modern LLM-enhanced workflow can turbocharge many aspects of this process:
- Dataiku’s suite of AI-powered visual recipes for text extraction, classification, and summarization mean you can automatically digest documents and triage incoming correspondence, categorize the nature of each claim, and extract information like names, addresses, and damage amount. Best of all, you can do this on multilingual text collections, and all in just a few clicks!
.png?width=736&height=511&name=GenAI_NLP_Recipes%20(1).png)
Visual components for LLM-powered NLP tasks in Dataiku
2. For more customized tasks, utilize Prompt Studios in Dataiku to develop the optimal set of instructions to extract all the necessary pieces of information you need to process the claim, or to generate personalized email responses back to the policyholder summarizing a status update.
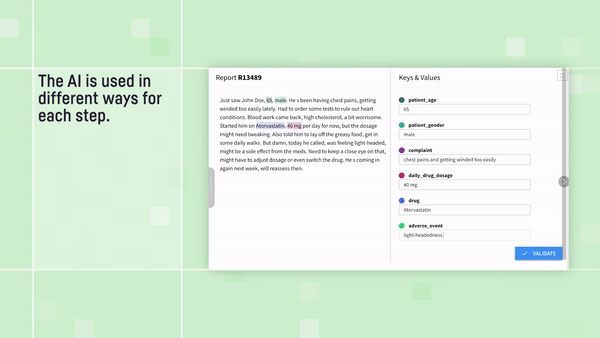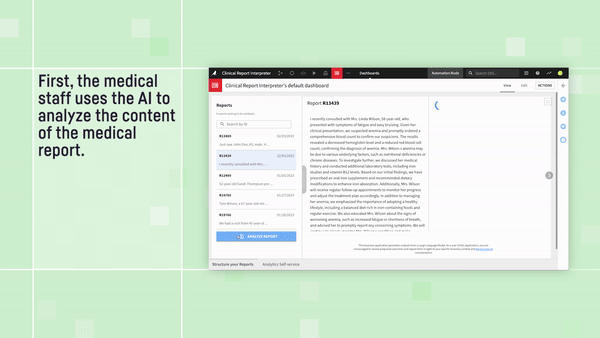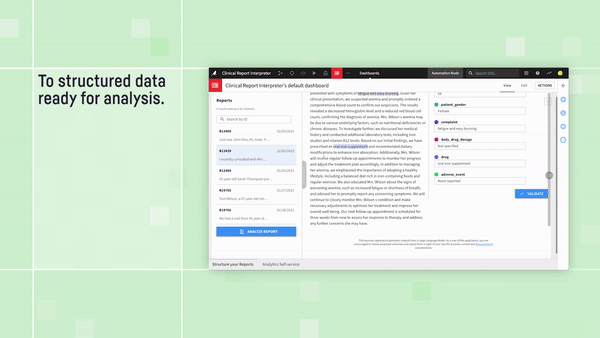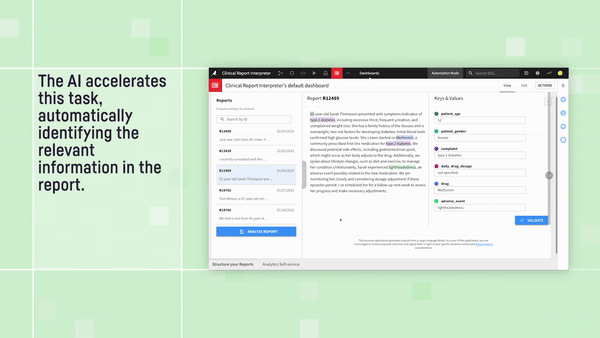
Check out the full video for this example application: Medical Report Analyzer
3. Want to level up your LLM application even more? By augmenting the model’s responses with information from your own knowledge base of policy documents, you can recoup the hours your claims handlers spend today looking up answers and terms of coverage for each specific claim.
This technique, known as Retrieval Augmented Generation (RAG), involves encoding and indexing the information in your source documents so that you can quickly retrieve the closest matches for a specific inquiry. In Dataiku, we make RAG easy by providing visual components to numerically encode and then store the information in your document collection, perform similarity searches to retrieve the most relevant bits for the inquiry at hand, and even a front-end Q&A application for your knowledge workers to use in daily operations.
Moreover, the benefits of LLMs don’t end with an internal employee knowing the right answer; with the power of Generative AI, you can even automatically quote a resolution & prepare the formal customer response!
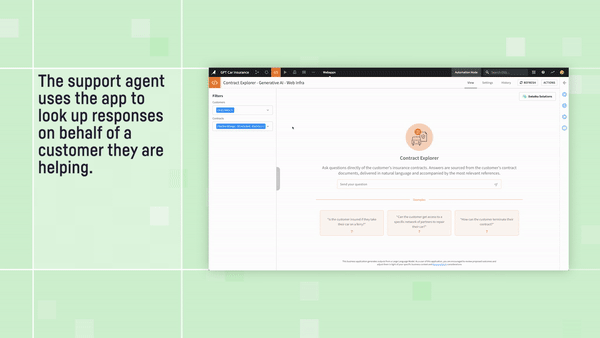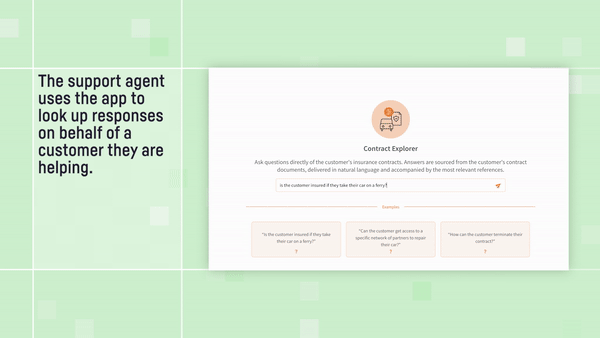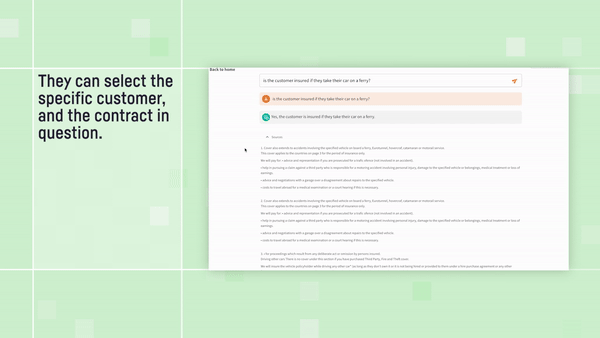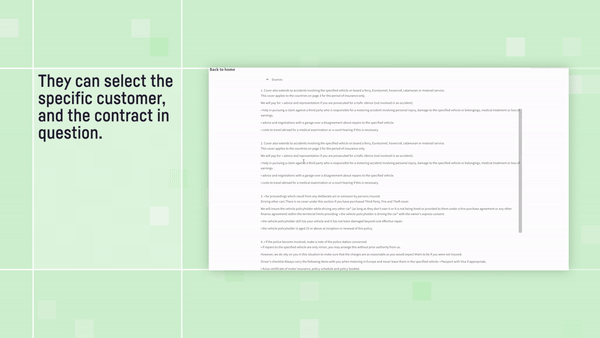
Check out the full video for this example application: Insurance Contract Explorer
Worried about letting an LLM respond autonomously? We couldn’t agree more! Having a human in the loop at various checkpoints is an important aspect of AI Governance, which is why Dataiku’s labeling capabilities let your operators verify that all details look correct and the policy has been applied correctly — keeping people not just in the loop, but also in control.
To learn more about how to adapt generic LLMs to your domain & use case and effectively combine them with other purpose-built models and tools, check out this blog on how to customize LLMs for your own applications. Remember, the claims processing scenario we explored is just one example; the possibilities for modernizing your traditional NLP or ML pipelines with LLMs are endless. We have a full catalog of Generative AI solutions to help you get inspired. We can’t wait to see what you build!