




{kind=link}
In this three-part series, we’ll unpack several technical topics that have made their way into the spotlight as a result of the increased usage and exploration of Large Language Models (LLMs). This way, technical practitioners can receive helpful context and discover the implications for their models in 2024. In this first article, we’ll explore one of the research avenues from the field: parameter-efficient tuning. Be sure to lookout for the following two articles in the series which will touch on quantization for LLMs and quantum ML.
Recently, there has been a substantial surge in the popularity of LLMs across industries. However, training LLMs can be resource-intensive in terms of data and computational power, making it a costly and time-consuming process. Consequently, a significant research focus has been made on achieving efficient training, fine-tuning, inference, or deployment of these models with reduced computational demands and time investment.
Parameter-efficient tuning enables fine-tuning an LLM on a new task without retraining all its parameters, often counted in billions. Instead, a small subset of the model’s parameters or additional parameters are fine-tuned while the rest remain frozen. This “delta tuning” [1] approach can be seen as a refined version of retraining specific layers or appending a classifier to a pre-trained model, aiming for comparable performance as fine-tuning the entire model.
Following [1]’s nomenclature, parameter-efficient fine-tuning (PEFT) methods fall into three categories: addition-based methods that introduce extra tunable parameters to the model, specification or selective methods [2] that choose specific parameters for tuning, and reparametrization methods that simplify parameters through low-rank approximations.
In this blog post, we focus on the most widely employed PEFT methods, primarily addition and reparametrization.
Prompt-Based Tuning
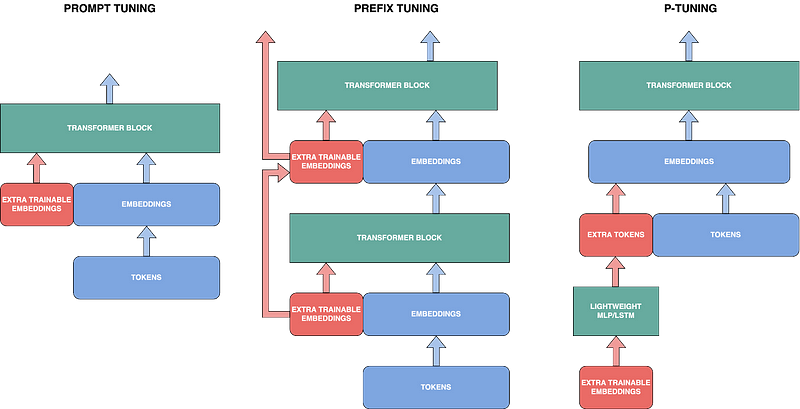
Prompt-based tuning designates addition methods that add extra trainable parameters to the original tokens of context fed into the model. These methods are also called “soft prompting” as opposed to “hard prompting” (prompt engineering) to get the best performance on a new task. For instance, in prompt-tuning [3], extra trainable embeddings are simply prepended to the model’s input, with only these parameters being retrained during fine-tuning.
Prefix-tuning [4], published at almost the same time, can be simplified as prompt tuning but applied at every attention layer of the model. Lastly, P-tuning [5] directly prepends tokens to the input instead of embedding. To achieve that, it uses a lightweight LSTM or MLP to predict the tokens from the trainable embedding parameters.
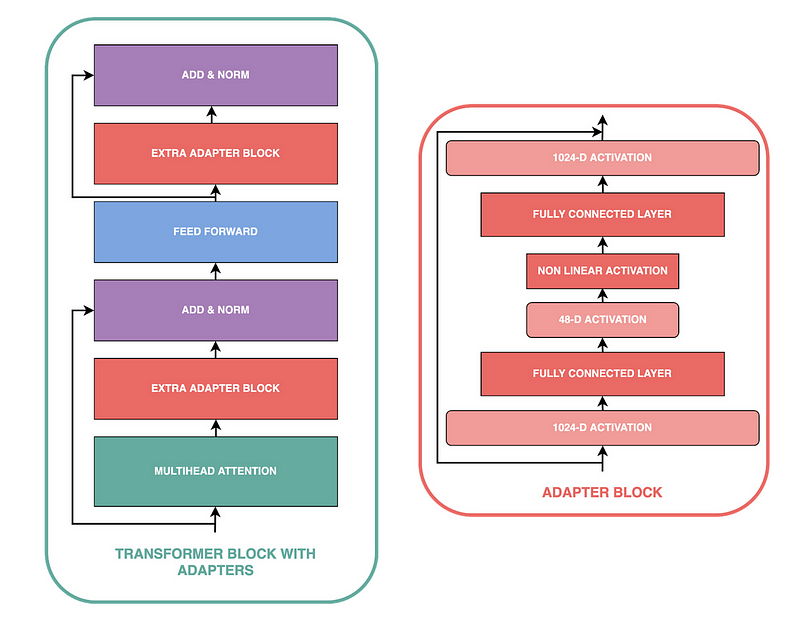
Adapters
Adapter [5] is another addition-based method often used to fine-tune LLMs. It is related to prefix tuning as it will add trainable weights in the sublayers of the model. However, it adds small, fully connected networks at two distinct locations in each sublayer of every transformer block instead of only prepending on the embeddings.
Low-Rank Adaptation
Low-Rank Adaptation (LoRA) [7] is probably the most used reparametrization-based method. The idea behind reparametrization methods is to leverage low-rank approximation methods that aim to approximate large matrices by smaller matrices. Hence, traditional dimension reduction methods such as PCA are examples of low-rank approximations.
In LoRA, the focus is on approximating not the weights directly but the weight updates, which are decomposed into two matrices of smaller dimensions. Only these matrices are modified through backpropagation during fine-tuning, while the pretrained model remains frozen. Post-fine-tuning, the weight updates can be merged with the frozen pretrained model to get the final fine-tuned model. To dive into LoRA details, I recommend this excellent blog post.
The table below (data from [1]) compares different PEFT methods over 100 different NLP tasks using the T5-base model [8]. It also shows the performance of prompt-tuning on T5-large to highlight the power of scale of this method [3]. P-tuning isn’t explored here but yields better results than prompt-tuning [5].
![Comparison of PEFT methods (data from [1])](https://cdn-images-1.medium.com/max/800/0*SSeWJDrBcD1vJO-y)
Research on parameter-efficient fine-tuning has substantially increased recently, with various new methods emerging. Some approaches, like Compacter [9], combine ideas from different paradigms (both addition and reparametrization-based).
Similarly, different methods presented here can be combined, for instance, fine-tuning with both LoRA and prompt-tuning. For those considering these techniques, you can have a look at the HuggingFace PEFT library, which offers off-the-shelf implementations compatible with most HuggingFace models.
[1] Ding et al. (2022). Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models.
[2] Lialin et al. (2023). Scaling down to scale up: A guide to parameter-efficient fine-tuning.
[3] Lester et al. (2021). The power of scale for parameter-efficient prompt tuning
[4] Li, X. L., & Liang, P. (2021). Prefix-tuning: Optimizing continuous prompts for generation.
[5] Liu et al. (2023). GPT understands, too.
[6] Houlsby et al. (2019). Parameter-efficient transfer learning for NLP.
[7] Hu et al. (2021). Lora: Low-rank adaptation of large language models.
[8] Raffel et al. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer.
[9] Karimi et al. (2021). Compacter: Efficient low-rank hypercomplex adapter layers.