




Risks of failing to implement a data quality assurance policy can be far reaching, especially when it is a reactive versus proactive approach. Imagine incorrect or broken automated reports for stakeholders, causing not only hours of rework, but loss of confidence in the value of the data. Or, in the case of deployed ML models used in business applications, potentially disastrous impact to customers from inaccurate profiling or stopped services. Ensuring that input data is valid and reliable means that downstream processes and applications run without a hitch — and data analysts and engineers don’t have to spend frustrating hours on fire drills reworking data.

However, doing QA in data science the right way can often be incredibly time consuming. One often-cited statistic says that those involved in AI projects spend 80% of their time on data preparation tasks. When data comes in from multiple sources, duplications are rampant and labels are often incorrect, so accurately profiling and cleansing data for its end use case usually involves many small tedious tasks that often include many rounds of modifications.
Dataiku Makes QA in Data Science or Analytics Projects a Breeze
Here are a few features within Dataiku that can save time for users preparing and managing data.
1. Gain a quick view of key data characteristics and preview column distributions.
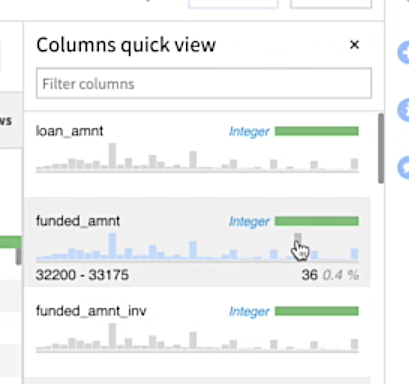
At a glance, visually profile every column in your dataset and identify potential outliers or columns that may require further processing to be useful for downstream analysis.
2. Use a visual quality bar to easily identify missing or invalid values.
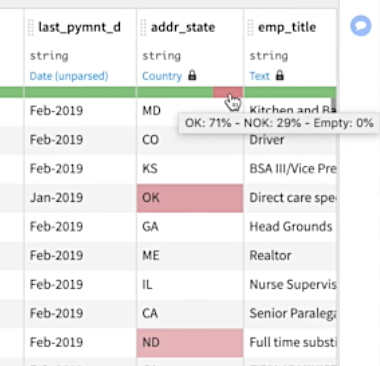
Dataiku automatically classifies data with rich semantic meanings inferred from patterns in the data. Examples of meanings include dates, email addresses, locations, and measures; you can define custom meanings as well. The quality bar indicates the proportions of records in your sample that are valid for your assigned meaning. This is a quick way to visually profile data and identify potentially invalid values. Automatic validity checks against these meanings can be set up for a single column, or even for all columns across every dataset in your project.
3. Quickly normalize text values with fuzzy matching.
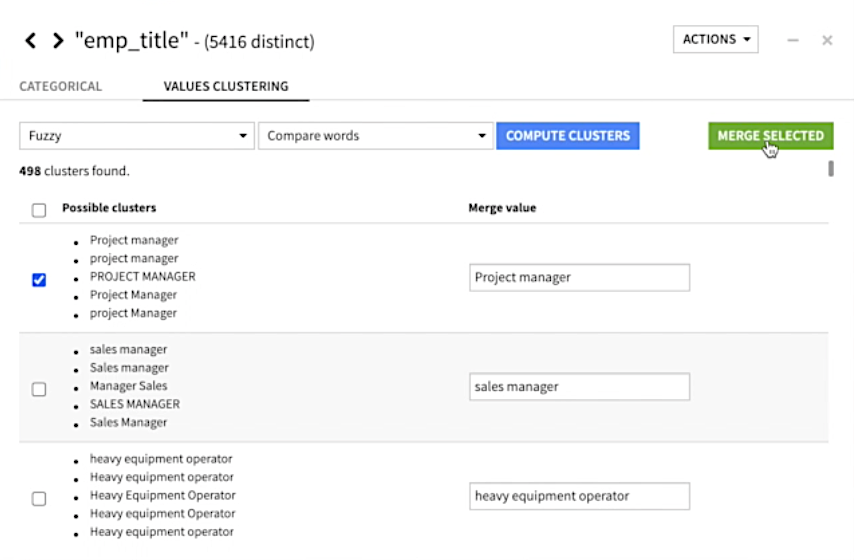
Often when people enter freeform values, there are different representations or labels of that data that ultimately should be merged into a single value (e.g.,. Registered Nurse vs. RN). With Dataiku, you can create clusters based on fuzzy matching and can automatically standardize category labels in bulk, saving a tremendous amount of manual labor.
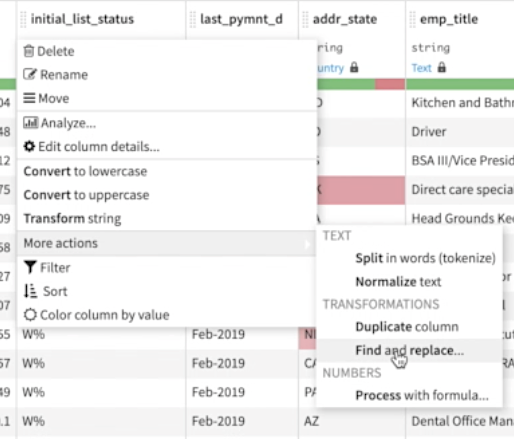
4. Remove unwanted characters with find and replace, plus dozens of other string manipulations.
{kind=link}
Dataiku comes with over 90 easy to use processors. One useful processor is find and replace, which allows you to quickly identify and replace unwanted values such as HTML markup, characters such as quotation marks, spaces with underscores to make a string filename friendly, and more. You can preview all changes before committing to be sure it’s what you expected.
5. Detect and remove outliers and duplicates.
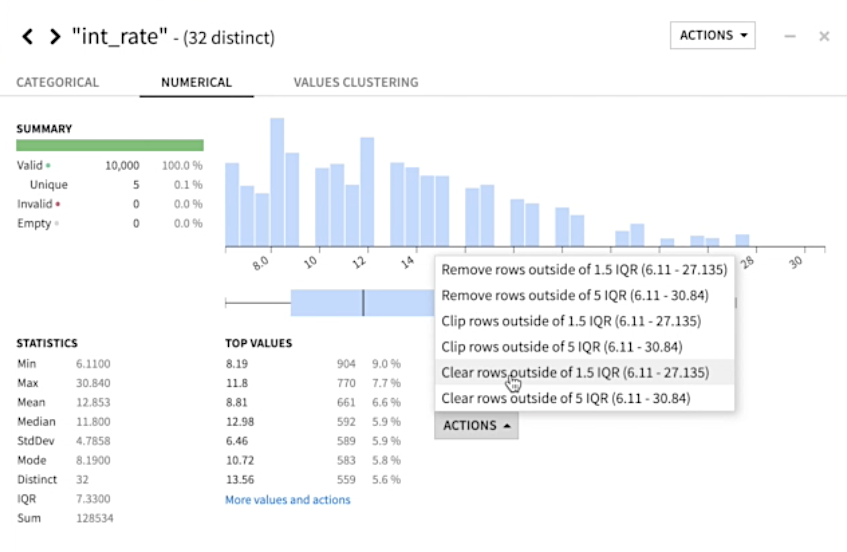
These are just a few ways Dataiku can take some of the pain out of QA and data cleansing in data science. Click below to explore some other key features designed to make data preparation less of a headache.