




As practitioners of data science, we look at the inputs and outputs of an AI system regularly in order to understand how and why a given decision is made. However, for the majority of people who do not work with AI, the concepts of machine learning (ML), algorithms, and data processing is a very opaque box. When these non-transparent systems are deployed in the real world, they are confusing for users of AI to make sense of a prediction or model outcome and often difficult to challenge or respond to.
For example, a recent report in Wired describes how patients with chronic pain are being denied pain management medication because an algorithm has flagged them as drug abusers in major pharmaceutical databases. The implementation of the algorithm offered no explanation for the risk score, nor an opportunity for a patient to counter the claim made by the system. As a result, many people continue to live with pain, or go through various hoops to access the medicine they need.
So what does this mean for Responsible AI in practice? Well, sometimes, even if we check our data for biases and ensure our models are fair, they can still cause unintentional harm and consequences. Moreover, when we are dealing with highly sensitive issues, such as prescription medication, both the users and beneficiaries of the algorithm need the right information to make the best decision or counter an incorrect one. Taking AI pipelines from opaque to transparent is a crucial step to ensure that models are deployed and used in a responsible manner.
So, What Do We Do About It?
Framing the potential harms and biases in the ML pipeline can be complicated. As we can see in the image below, there are many points of contact where an AI model can be biased, whether it’s the data generation, model building, or implementation phase. In this case, we are focusing on deployment bias, where human interpretation and integration into existing systems can impact the real-world implications of a model. This kind of bias relates to consumption bias and is often the result of end users misunderstanding either the intended purpose or the meaning outputs of a model.
.png?width=618&name=image%20(4).png)
Suresh, Harini & Guttag, John (2019). A Framework for Understanding Unintended Consequences of Machine Learning
Do It With Dataiku
To better illustrate these concepts, let’s look at a common actuarial use case. When someone wants to get a life insurance policy, the insurance group will look at various parts of that person’s profile to determine the amount and cost of coverage. One way to determine this is through the use of risk scores, which actuaries build with a variety of data science techniques. For this example, let’s say the actuary or data science team that built the ML pipeline for risk scores used data and model bias detection techniques to determine they have built a fair model (according to their company or department’s definition).
Upon releasing the model to downstream processes, insurance adjusters have to take the risk recommendation at face value, without knowing how or why a potential customer’s risk was derived. This creates an opportunity for unintentional misuse. Moreover, a prospective client has the right to know why they have been assigned a given risk profile, and correct or counter the assumptions made by the model. In this way, creating better reporting systems for end users can both provide better information and offer an opportunity to give feedback from the real world.
For this use case, we are using data that is at the level of individual policyholders, with information on their health, behavior, and other aspects of their lives. Each individual has an assigned risk score — low, medium, or high — and we can model the predicted risk with attention to issues of bias in the dataset and models. So with this in mind, how can we use Dataiku to build better reporting structures?
Explainable and Interpretable Results
The terms explainable and interpretable are often used interchangeably when discussing white box models, but in the framework of Responsible AI they mean different things. Interpretability means that a user can understand which input features were most important in determining the algorithmic weights for the global model. Explainability refers to the features that are most influential in determining an individual prediction. You may have heard of concepts like ICE and Shapley.
While these explainability metrics can be used at a global model level, they are most useful when assessing the relationship between the inputs and a single prediction in the test dataset. On the other hand, variable importance for a global model helps us interpret which features were most useful in building the algorithm. Below, we can see the variable importance for our model, which is a random forest classifier.
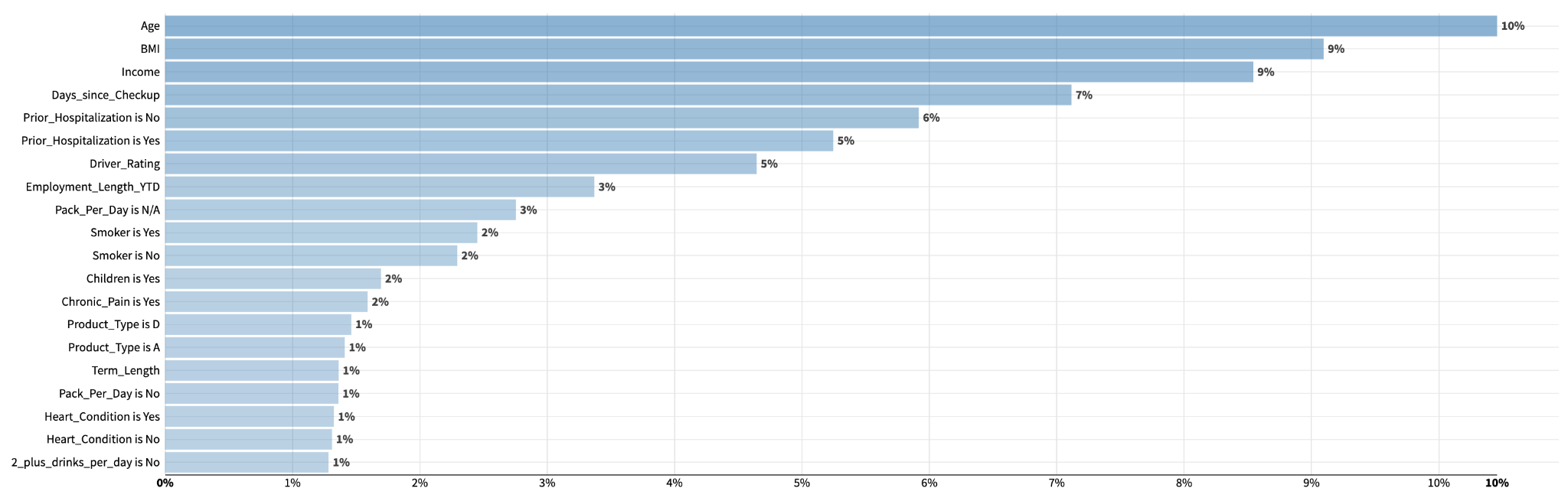
In this case, the variables of Age, BMI, and Income level are most influential in the model. These factors help us interpret how the model was built and, in the case of our random forest model, these variables have high Gini Importance. In presenting these results, the model report should offer a small explanation of what these variable importances mean and how they influence the creation of the model.
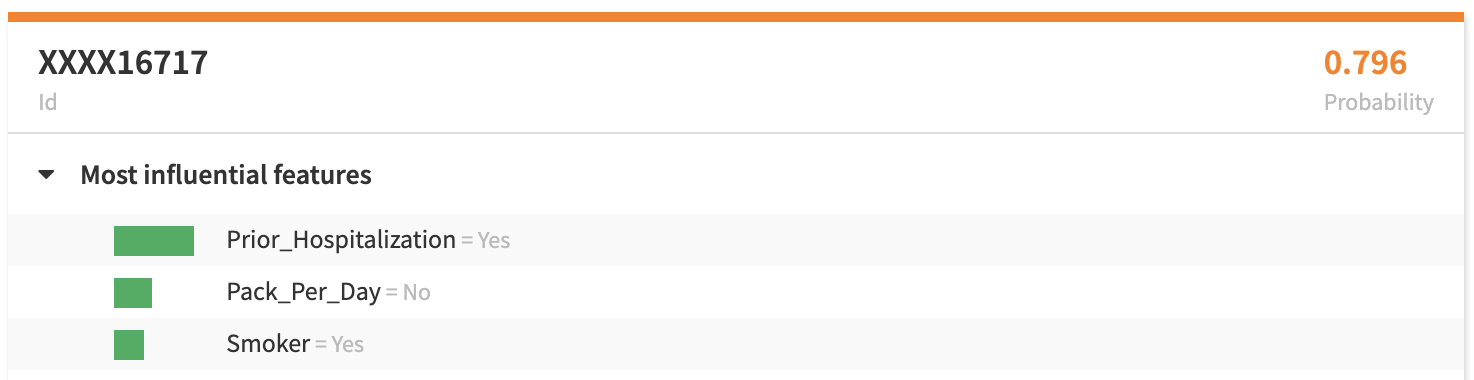
On the other hand, the explainability of the model is best viewed through Individual Prediction Explanations. These results show what features best explain a given person’s risk probability. For example, in the below record you can see the model estimates about an 80% probability that the client is ‘High Risk.’ The three most influential features for this specific person is their prior hospitalization and their smoking habits. Note that these three features are not considered the most important for the model overall — especially because the calculations used for variable importance and influential features are different.
Data Context and Documentation
A second factor that is important for reporting model outputs is clear documentation on the various inputs used in the ML pipeline. Providing information on the nature and distribution of data used to train the model, whether any bias mitigation techniques were applied to the data or models, and why those decisions were made serve the larger goal of transparency for end users. This kind of report may be potentially too technical or overwhelming for someone unfamiliar with data science, so it is important to provide information that is most relevant for a customer or potential policy holder. For instance, the report could show the relationship between prior hospitalizations and predicted risk, shown below.
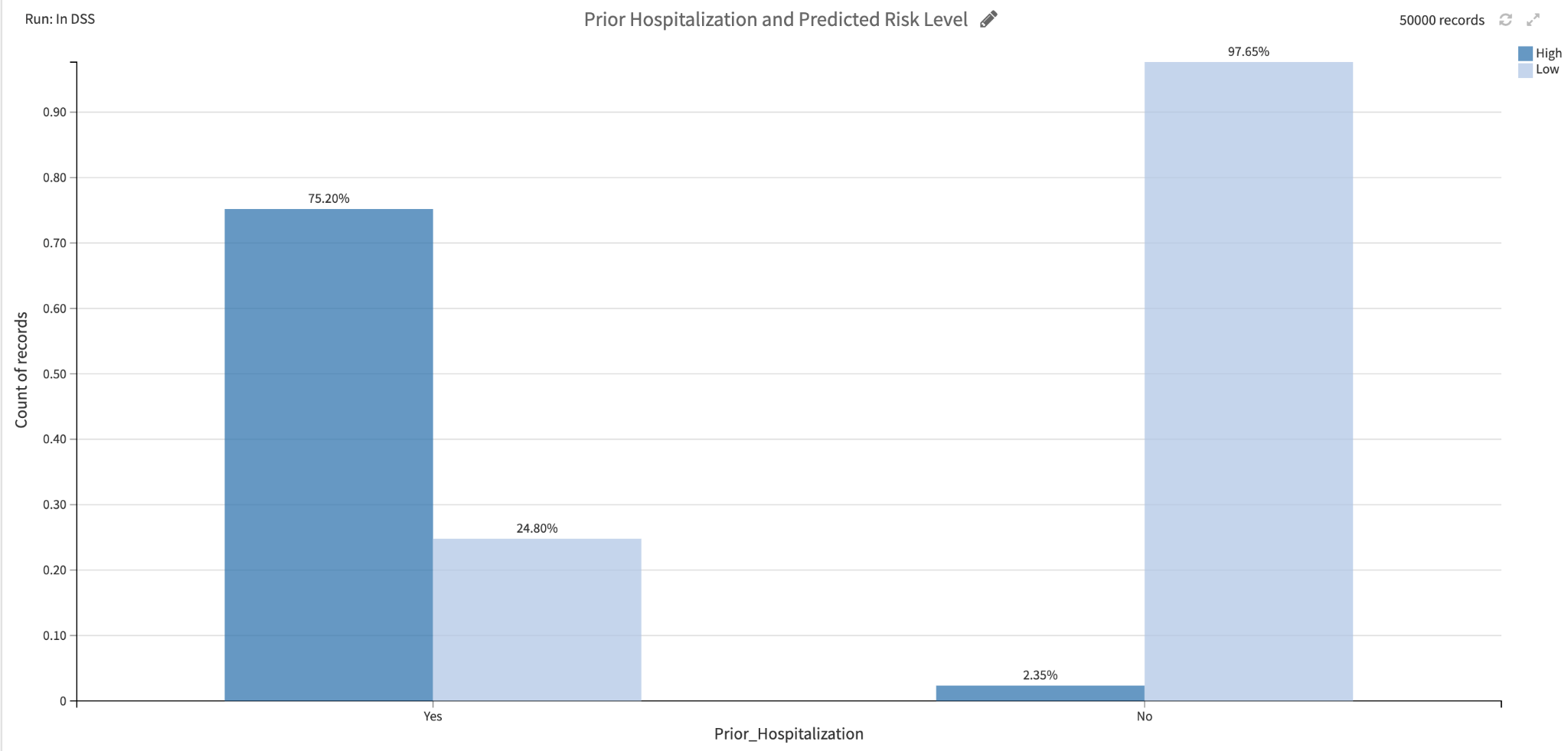
In this case, the chart could be accompanied by text describing the user’s own profile so that they can see where they fall relative to the training data. Someone without a prior hospitalization but with a ‘High Risk’ profile would know that they are in a small bucket compared to their peers and could refer back to the individual explanations to understand what else is driving their risk score.
Interactive and Responsive
The final component of an effective reporting strategy is the ability for a user to interact with the model and provide feedback. The predictions and outputs of an AI pipeline should not be one directional. Users with domain knowledge and firsthand experience should have an opportunity to provide feedback and give their thoughts on the model in order to further improve it in future iterations. This is especially important for the people directly affected by a model — think back to the woman seeking pain medication. If she had an opportunity to clarify why the model was wrong about her and provide the evidence to support that claim, the developers of the model would be able to improve their outputs for many other patients like her.
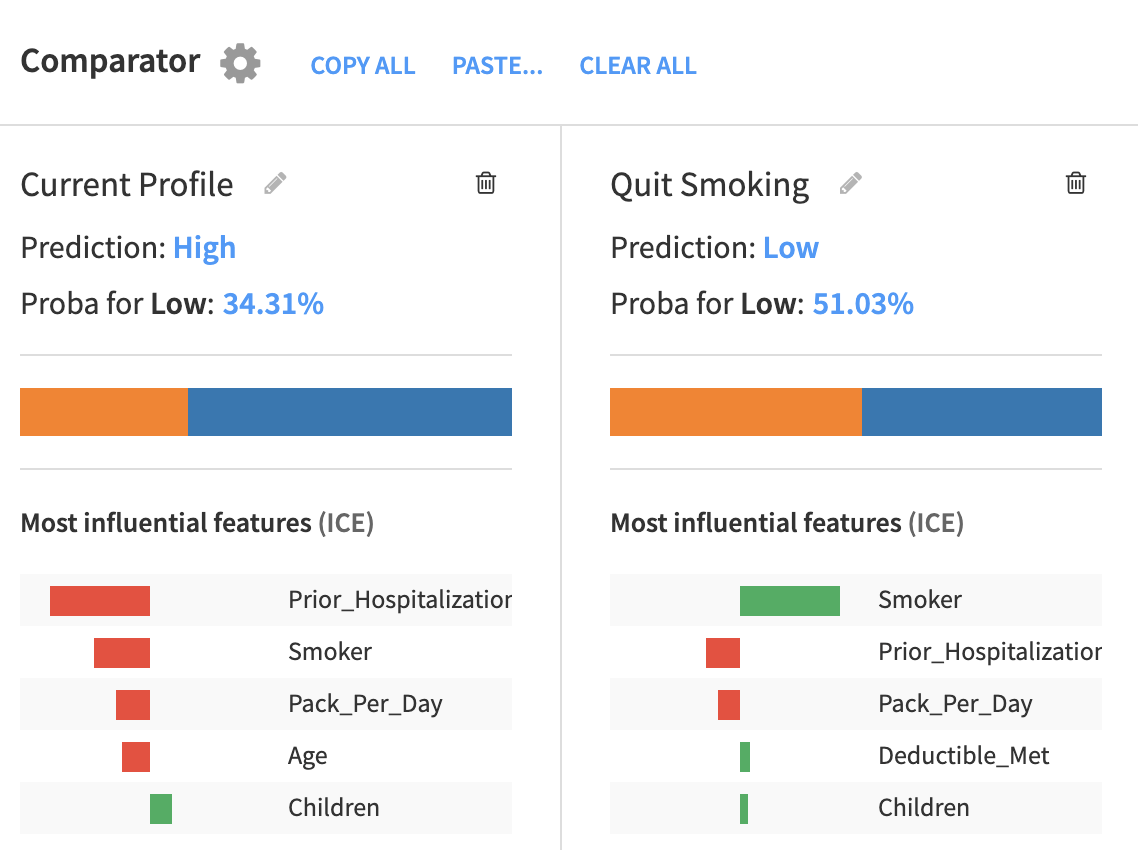
Another aspect of the interactive report is ‘what-if’ analysis, which allows a user to alter some inputs in a model and see how that might change the outcome. For example, a customer rated as ‘High Risk’ by our model may want to know what action they can take to lower their risk score. In the example below, we use the Interactive Scoring feature of Dataiku to see the difference in predicted risk if a customer stops smoking. In their current profile, the probability of being a low risk to the insurance company is 34%. This prediction can be directly compared to a ‘what-if’ case where all features of the customer’s profile are the same, except that they are not a smoker. In this case, the prediction changes to low risk and the individual explanations even change slightly. This gives an opportunity for the customer to change their behavior towards a positive outcome and easily quantifies the impact of that change.
{kind=link}
Key Takeaways
Building and testing fair ML pipelines is the basis for Responsible AI. However, in order to reduce unintended consequences and potential misuse down the line, data practitioners need to provide transparent and explainable reports with the outputs of their models. These steps are important for both vetting a model before deployment and reinforcing the practice of transparent model reporting. In the use case highlighted above, various tools and methodologies give end users an opportunity to dive into the specifics of a prediction and understand how and why a certain outcome came to be. Providing this information can help build trust in AI systems, and support the fair use of a model once it is out in the world.