




{kind=link}
Want to take execution of AI initiatives across the organization on Snowflake to the next level? Some of the latest updates from Snowflake make it easier to leverage Dataiku to do just that.
For example, with the availability of Snowflake Java UDFs comes the availability of a series of new pushed-down data preparation functions in Dataiku. Plus, coders in Dataiku will soon be able to contribute to AI projects with code that will be executed in Snowflake, therefore enabling them to fully operate their Dataiku projects in Snowflake. This blog post will dive further into these two use cases.
In order to understand the significance of Snowflake’s ability to handle Java User-Defined Functions (UDF), we have to go back to one of the founding principles and key differentiators of Dataiku: the delegation of compute.
From its conception, Dataiku was architected to address two challenges often faced with enterprise software:
- The ever-changing technology stack — There’s always the next big thing.
- The ever-increasing volume of data — Moving it around is not fun.
Consequently, Dataiku was designed at its core to push the workload down to the data platform as well as adapt to its compute capabilities.
And for Snowflake, until now, it meant visual pipelines that could be expressed in SQL — i.e., data preparation and scoring of predictive models were executed in Snowflake.
Enter: The Snowflake Java UDF
Java UDFs allow workloads expressed in Java to execute in Snowflake and therefore benefit from the virtually unlimited performance and scalability of the Data Cloud.
Coincidentally, the core of Dataiku’s own engine is Java, making it convenient for Dataiku to repackage data preparation functions —and more notably, machine learning models — so they can be executed directly in Snowflake.
Since the capability was made available, our engineering team has been hard at work on it, and we’re happy to announce that Dataiku has delivered a series of new pushed-down data preparation functions in Dataiku.
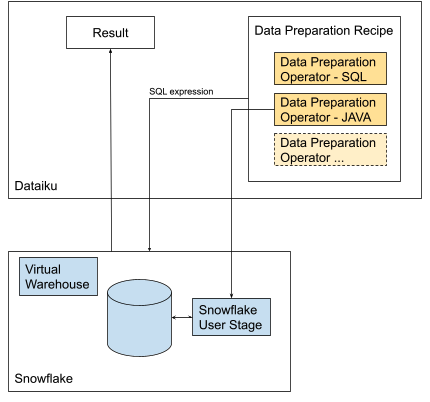
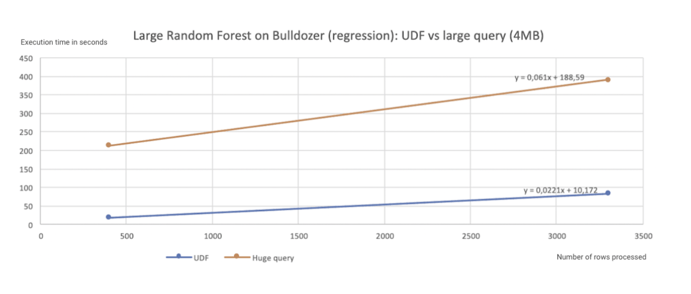
In addition, Dataiku can now deploy Dataiku models as Java UDFs in Snowflake for batch scoring. The result is performance gains comparing a model expressed in SQL to a model deployed as a Java UDF:
But Wait… What about Snowpark Client Libraries?
Dataiku provides a unique collaborative experience for users of various skills (coders and non-coders) to work together on analytic and data science projects. As part of this experience, coders may use their preferred language and familiar notebook experience to develop pieces of code that will be executed as part of the Dataiku Flow.
Again, until now, for this code to be executed in Snowflake (close to the data) it needed to be SQL. With the introduction of Snowpark, the new developer experience for Snowflake, coders in Dataiku will soon be able to contribute to AI projects with code that will be executed in Snowflake, therefore enabling them to fully operate their Dataiku projects in Snowflake.