




{kind=link}
The Retrieval-Augmented Generation (RAG) approach enables Large Language Models (LLMs) to generate answers grounded in a knowledge base. Such a knowledge base is usually a relatively small and stable collection of corporate documents (e.g., technical documents, reports, procedures, contracts, etc.) but the RAG approach can be implemented at a much wider scale.
In this blog post, we’ll see how we can directly leverage web content in a question-answering system. More precisely, we’ll discuss:
- The limitations of the standard RAG approach;
- The main design choices for a web-based RAG pipeline;
- The practical aspects to take into consideration for such a use case;
- The lessons learned in the context of a recent project with Heraeus, a German-based technology company.

When Is Standard RAG Not Enough?
For a given user question, RAG consists in selecting extracts of a knowledge base relevant to the question, including both these extracts and the question in a prompt, and letting an LLM generate the answer based on this prompt. In this context, the retrieval of relevant extracts is generally made possible by the following pre-processing steps applied to the documents of the knowledge base:
- Extract the raw text from the documents;
- Split the text in small chunks (typically the size of one or several paragraphs);
- Compute an embedding for each chunk;
- Index the chunks and their embeddings to enable fast similarity search.
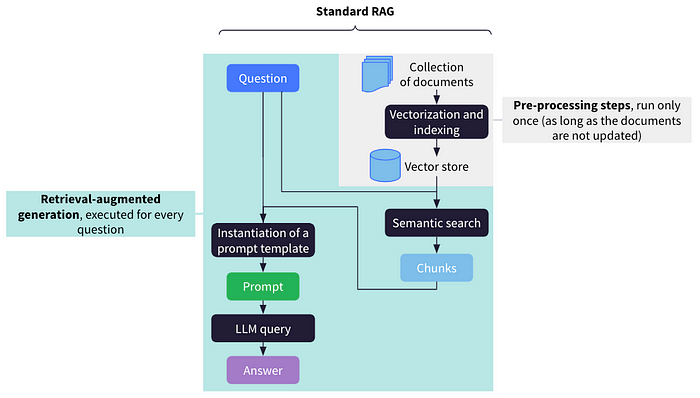
Such a RAG pipeline is easy to implement and can generate reasonably good answers. However, in certain cases, the range of potential questions may be so wide that it is not possible to a priori select and pre-process all relevant documents. If these relevant documents frequently evolve, it may also be challenging to keep our index up to date.
Fortunately, we can take advantage of the largest knowledge base ever built: the internet! Conveniently for our purpose, the internet is constantly explored and indexed by powerful search engines which make retrieving relevant information very straightforward.
Main Design Choices for a Web-Based RAG Pipeline
We now focus on the main technical questions to answer when implementing a RAG pipeline that leverages a web search engine.
What Should Be Included in the Prompt?
Let’s assume that we want to answer the following question: “What benefits does Dataiku bring for Generative AI use cases?” We can use this question as a search query and retrieve the corresponding web search results through the API made available by a search engine provider.
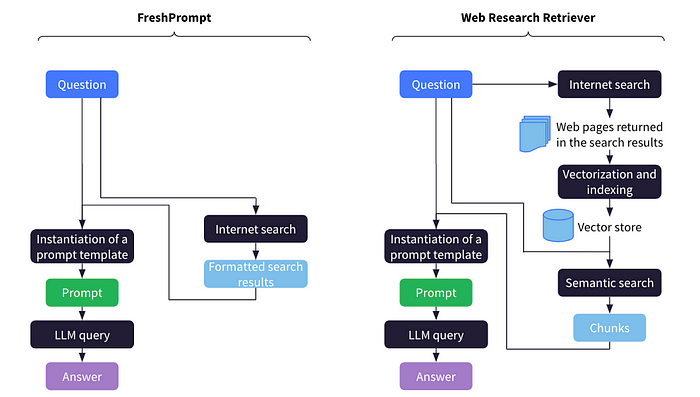
The format of these search results varies from one API to another but the results typically include a title, a snippet of text, and a URL. A first option is to directly include these search results, in particular the title and the snippet, in our prompt. A recent academic paper by Google and University of Massachusetts Amherst proposed such an approach and named it FreshPrompt.
Another method is to disregard the title and the snippet of the search results and scrape the web pages corresponding to the URLs. In this case, we can directly include this content in the prompt, provided that the cumulated length of the web pages does not exceed the size of the context window. Alternatively, as suggested in the LangChain blog post on Web Research Retriever, we can also process and search this content as in a standard RAG approach. The only difference here is that this processing takes place on-the-fly and the corresponding index does not need to persist.
These two approaches are not mutually exclusive. We can first try to quickly answer the user question, just on the basis of the search results and, if this first attempt is unsuccessful, make the additional effort to scrape, index, and query the content of the corresponding web pages.
Which Search Query?
The web search query can simply be the user question. This is the choice made in the FreshPrompt paper. However, it might be more efficient to generate search queries that differ from the user question. It can make sense in particular if answering the user question requires several web searches in parallel (e.g., “What are the populations of the Netherlands and Belgium?”). In this case, we can let the LLM first generate search queries on the basis of the user question, as in Web Search Retriever.
Static Chain or Agent?
As with standard RAG, we can either define an LLM chain that always includes the same steps and systematically uses the search engine, as in FreshPrompt and Web Search Retriever, or we can implement an LLM agent that can decide whether and when to use the search engine. The latter case is necessary in the case of multi-hop questions, i.e., questions that require several sequential retrieval steps (e.g., “What is the date of birth of the main actor in the latest Martin Scorsese movie?”).
A sample project on Dataiku’s public gallery illustrates these various design choices with three examples of web-based RAG pipelines based on either the YOU API or the Brave Search API. It can be downloaded and easily reused by Dataiku users.
Practical Considerations for Web-Based RAG Use Cases
Beyond the main design choices described above, several other important aspects should be taken into account.
Factuality and Content Moderation
Web-based RAG obviously entails greater risks of errors and offensive content compared to standard RAG on a well-controlled collection of internal documents. We should then consider a variety of measures to mitigate these risks.
Privacy
A web-based RAG pipeline may include personal information in its answers. We might then inadvertently store personal information in breach of privacy regulations. To avoid this, we can prompt the LLM to refrain from answering questions on individuals or from including personal details in its answers. We can also sift the answers with a Personally Identifiable Information (PII) detector as an additional precaution.
Web Scraping Etiquette
If the web-based RAG pipeline requires web scraping, as with Web Research Retriever, we should be good internet citizens and avoid overburdening the websites. This involves complying with robots.txt instructions, locally caching scraped content, downloading only the HTML pages and not the associated resources like images, and limiting the requests’ frequency. Additionally, be mindful of legal restrictions on web scraping, in particular if your use case might harm the scraped websites or infringe on copyright regulations.
Compliance With the Search Engine’s Terms of Use
Some search engine providers offer a search API but restrict it to simple use cases in which the search results can only be directly displayed to the end user, without any additional processing. Implementing a web-based RAG pipeline would not be compliant with such limitations. When selecting the search engine for such a use case, you should involve your legal department and ask for a careful review of the terms of use of the search API.
Lessons Learned During a Recent Project
Let’s look at a concrete example of a recent project implementing a web-based RAG pipeline.
Context and Objectives
The Heraeus Group is a broadly diversified and globally leading family-owned technology company. It encompasses four business platforms (metals & recycling, healthcare, semiconductor & electronics, and industrials) and 20 operating companies. Each operating company has its own sales lead identification and qualification process, which is generally quite informal.
One of the key challenges is that potentially interesting sales leads for Heraeus are often highly specialized players and are not very visible or well referenced. In this context, Heraeus wanted to leverage LLMs to automate this process as much as possible and partnered with Dataiku to implement a proof-of-concept.
Outline of the Solution
The solution developed for this use case is outlined in the diagram below. The only user inputs are a natural language description of the selection criterion for the sales leads (e.g., businesses that are active in a specific therapeutic end-market as well as located in a defined region) and an optional list of open-ended questions on the sales leads. These inputs are then processed as follows:
- An LLM lists companies (name and homepage URL) corresponding to the selection criterion;
- The companies suggested by the LLM are looked for on Crunchbase;
- For the companies identified on Crunchbase, we double check the selection criterion thanks to Crunchbase, internet search results, and the company’s website;
- We answer complementary questions based on internet search results and the company’s website.
For steps 3 and 4, we first try to answer only with the search results (similarly to FreshPrompt) and the Crunchbase description of the company and, if this is inconclusive, we try again by leveraging the content scraped from the company’s website (similarly to Web Research Retriever). In both cases, we restrict the web search to the company’s domain name to reduce the risk of erroneous or obsolete information.
At the end of these 4 steps, end users can use a web interface to visualize the results, check the corresponding sources and citations, and validate the sales leads.
Lessons Learned
This project was instructive in several regards:
- It was possible to generate large lists of potentially interesting companies using simply GPT-4. A limited number of these companies had disappeared or changed their names (which was expected since we rely only on GPT4’s internal memory) but we have almost not seen examples of real hallucinations, i.e., companies that simply do not exist. Overall, Heraeus estimates that the time saved for the identification of sales leads is approximately 60%-70% and notes that this project led to sales leads that would not have been identified otherwise.
- Double checking with search results and web pages generally works well. The main problem is that sometimes the relevant information is not publicly available on the internet. For example, it is far easier to fact-check selection criteria on the companies’ products than on their production processes.
- A weak point of the current pipeline is how we decompose the user-provided selection criteria into a set of “atomic” selection criteria that can be independently checked. We broadly manage to perform the decomposition itself but even GPT-4 struggles to combine the results of the individual checks into a final conclusion. For example, if the selection criteria are “Being active in the robot-assisted surgery field and being active in the U.S. or Canada,” we can obtain the following “atomic” selection criteria: “Being active in the robot-assisted surgery field,” “Being active in the U.S.,” and “Being active in Canada.” However, if the assessment for these three “atomic” selection criteria is: “true,” “true,” “unknown,” the conclusion of the LLM could be “unknown” whereas it should be “true.” This is an area of improvement for a future version.
- More generally, this project also illustrated how LLMs can trigger and facilitate the collaboration between domain experts and data scientists. It was business stakeholders from Heraeus’s Commercial Excellence team that initially identified the use case idea. They were able to autonomously assess the feasibility of the use case with ChatGPT and once they got promising results, they contacted Heraeus’s data science team and then Dataiku to improve and automate this pipeline. Furthermore, during the development of the project, the fact that the core material was just text, e.g., prompts, LLM completions, and search results, made discussing results and brainstorming improvements in cooperation with these business stakeholders much easier. This shows how LLMs can be a catalyst for AI democratization in a corporate setting. You can learn more about this use case on Dataiku’s website.
Conclusion
Using web content with a RAG approach is straightforward and quick: We do not need to build and maintain a knowledge base and we can directly leverage the richness of the internet and the power of modern web search engines.
This can complement a standard RAG approach. Chunks retrieved from internal sources and the internet can be combined in the same prompt or a web-based RAG pipeline can serve as a stand-in if a RAG pipeline based on internal documents fails to provide an answer.
Of course, using web content implies less control of the information sources. Data science teams implementing web-based RAG pipelines should then carefully assess and mitigate the corresponding risks.