




{kind=link}
By integrating domain-specific knowledge into a Large Language Model (LLM), Retrieval Augmented Generation (RAG) enables the generation of highly tailored and contextually relevant responses. For instance, leveraging product documentation and tutorials, RAG empowers chatbots to provide users with insightful and precise support on the given tool or subject matter.
Although the initial setup of a basic RAG system from a document database may seem straightforward and can produce satisfactory results, the true difficulty arises in evaluating and improving these initial outcomes.
In this article, we highlight the limitations of baseline RAG pipelines and offer strategies for overcoming these challenges. Moreover, we present a methodical approach to guide the construction and enhancement of RAG systems, paving the way for their effectiveness in real-world applications.
1. A Close Look at Baseline RAG’s Imperfections
RAG Basics: Unpacking the Fundamentals
Let’s begin our exploration of the RAG pipeline by delving into a concrete example: crafting a user-support chatbot designed specifically for Dataiku users. Illustrated below, the pipeline encompasses three key components.
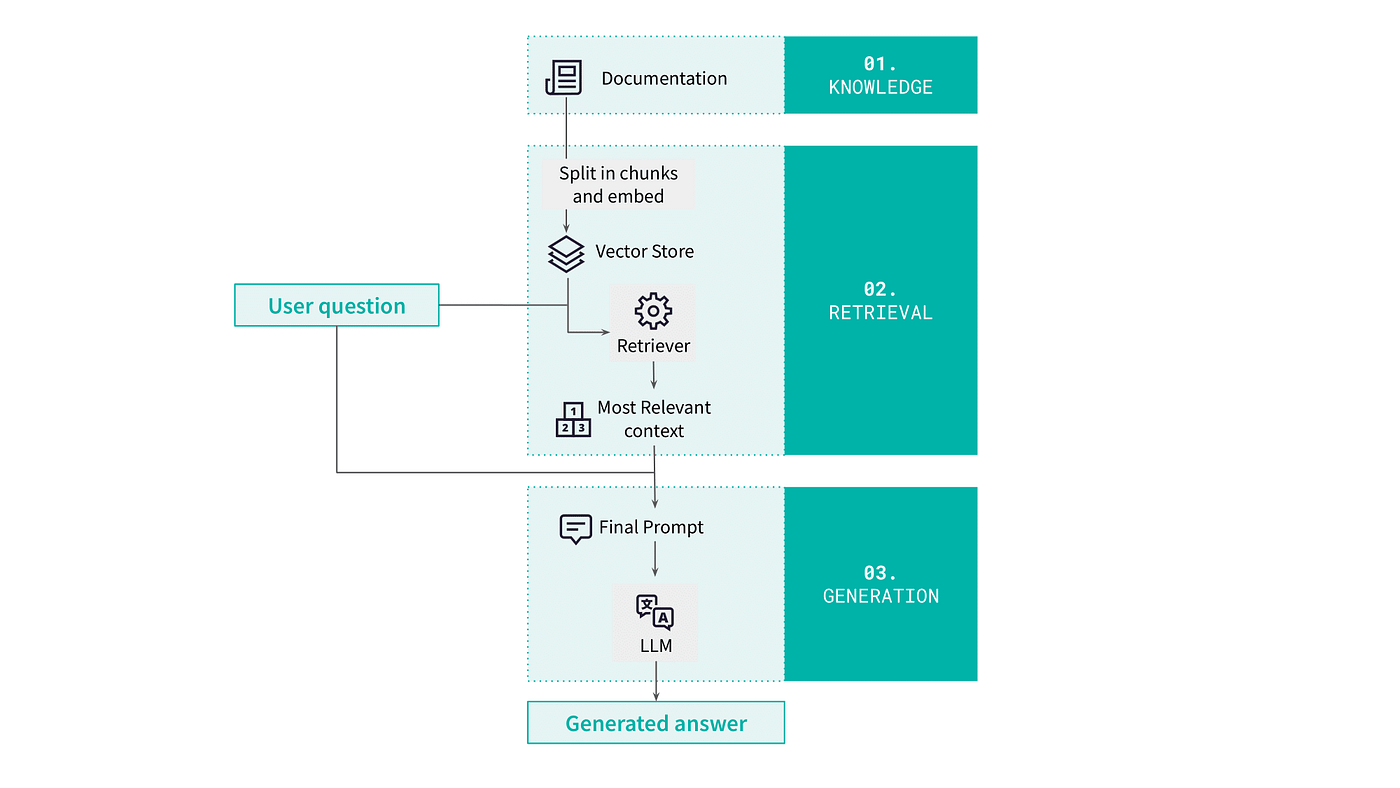
The first component of the system is a corpus of knowledge that contains all information relevant for addressing user inquiries. In our case, this includes general product documentation and user tutorials.
When a user asks a question, the retrieval component comes into play. Its role is to identify the most pertinent segments of the knowledge corpus given the user query. The segmentation of the corpus into chunks and the retrieval method employed are pivotal to ensuring the quality of this process.
Finally, the generation component provides a final answer based on the user query and the previously retrieved chunks. This step relies on an LLM.
RAG Weak Spots: Common Failure Modes
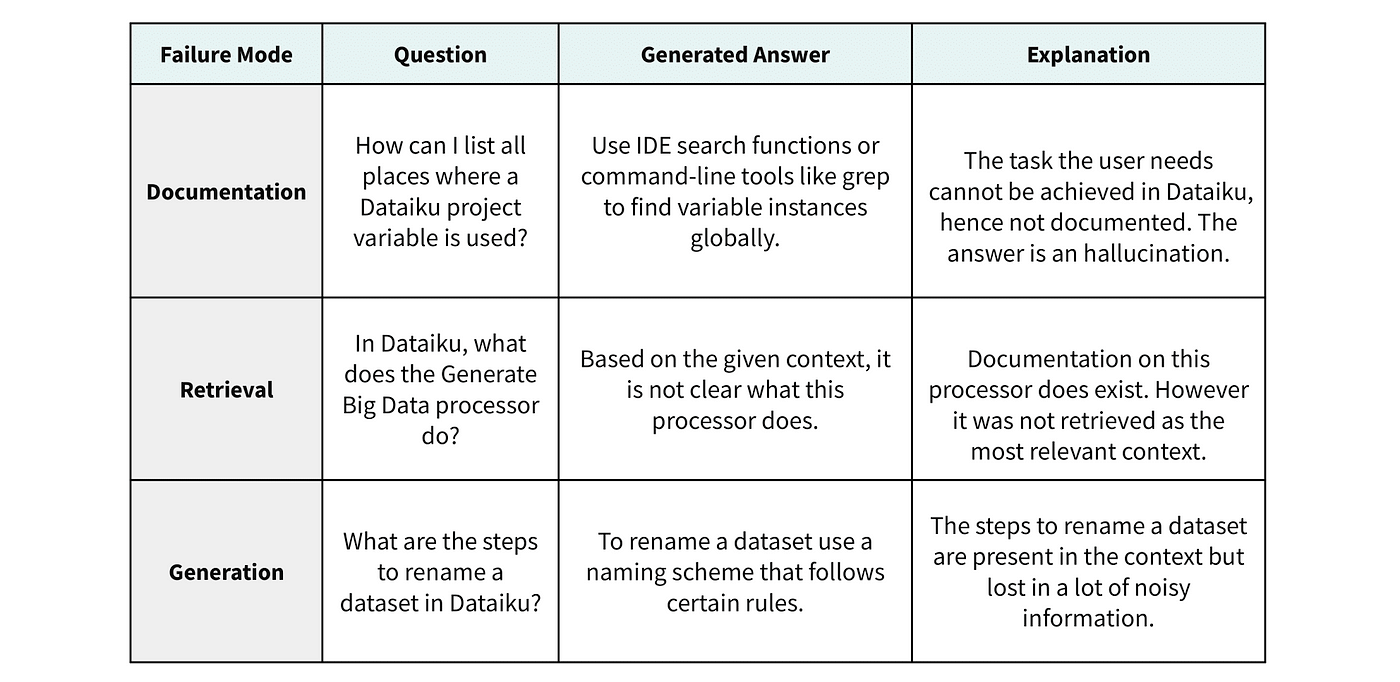
Any shortcoming in one of these three components can result in a poor answer to the user.
- Firstly, if the relevant information given the user’s query cannot be found within the corpus, the model will inevitably fail.
- Secondly, if the relevant information exists within the corpus but is not effectively retrieved, the outcome remains the same.
- Lastly, despite having access to pertinent elements from the corpus, the generation step may falter, particularly if crucial information is overshadowed by irrelevant details in the retrieved context.
Examples illustrating each of these failure modes are provided in the table below.
2. Take Your RAG System to the Next Level
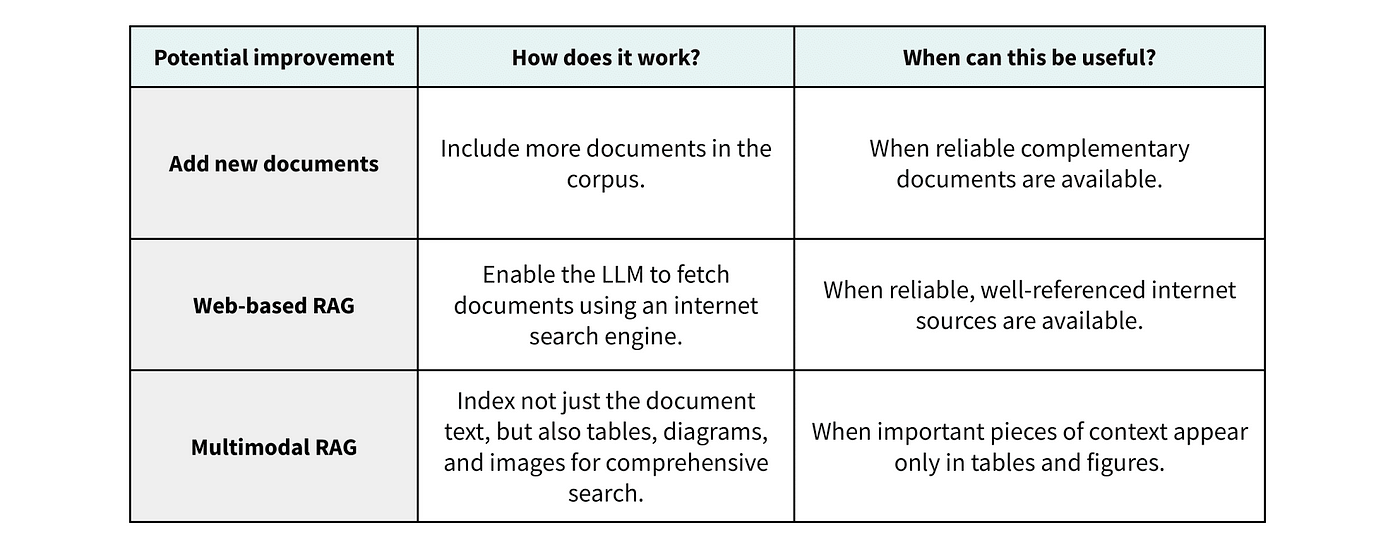
When dealing with these setbacks, we can rely on several practical methods to strengthen each of the three components of a RAG pipeline. We highlight some of these methods below.
Addressing Knowledge Corpus Challenges
If the relevant facts for a given question are absent from the knowledge corpus, we can include additional sources or better process the existing sources by taking advantage not only of their text but also their tables and figures.
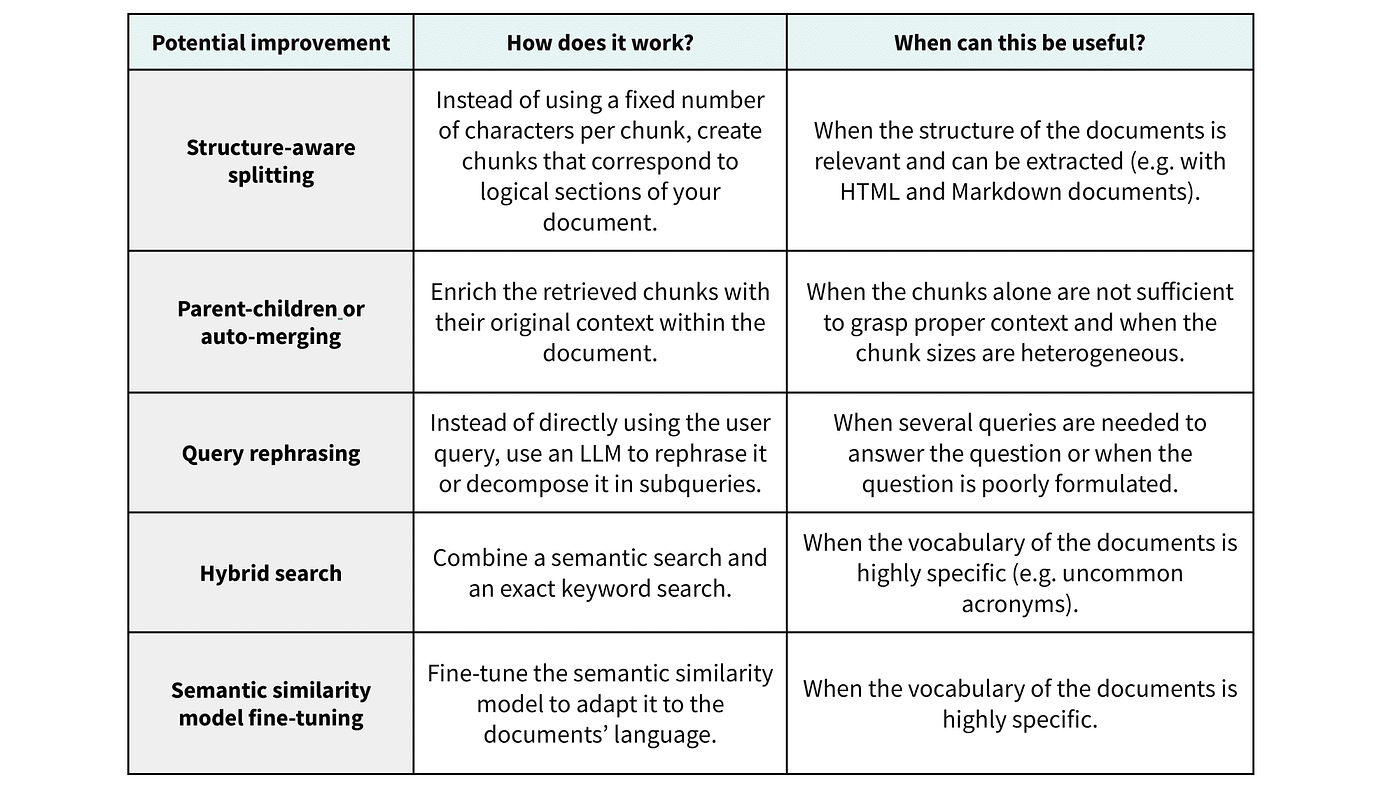
Optimizing Retrieval Performance
A frequent situation is when the knowledge corpus includes the relevant facts but the retrieval step fails to identify them. In this case, we can try to make the individual chunks more relevant and self-contained, modify the search query or use a different retrieval strategy.
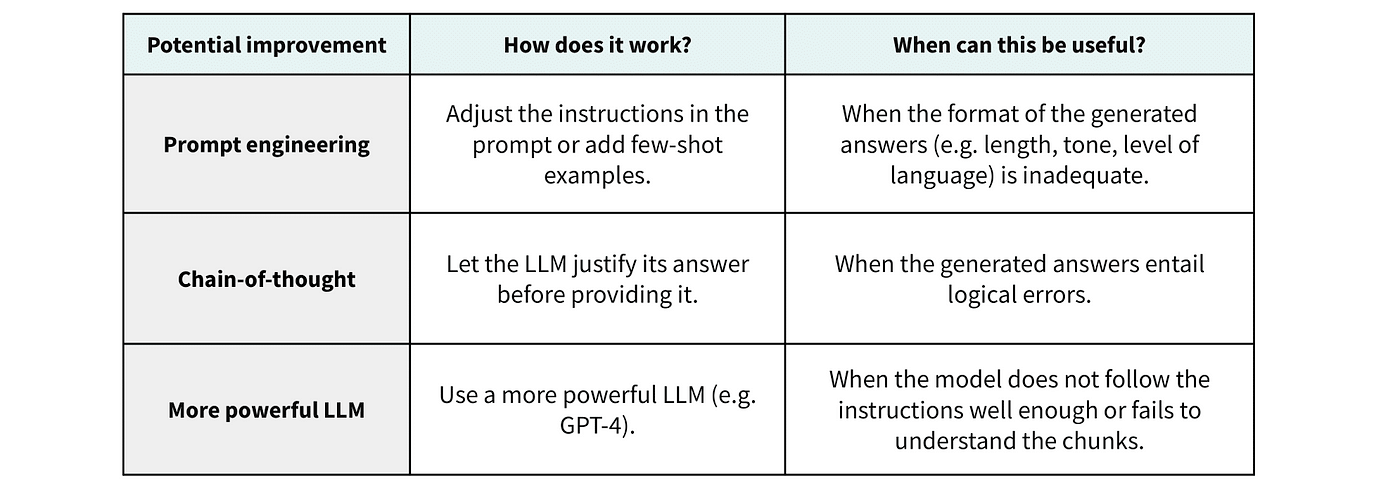
Boosting Generation Quality
Finally, even when the right pieces of context have been retrieved and included in the prompt, the LLM can still fail to generate a proper answer. In this case, we can use prompt engineering techniques or a more powerful model.
3. Zero to One: Crafting the Ideal RAG Model Through Methodical Exploration
Optimizing Baseline Models via Continuous Improvement
As discussed in the previous section, there are countless strategies to improve each one of the three components of a RAG pipeline. In order to methodically explore and choose from the available options, an iterative approach is needed. We suggest adopting the methodology depicted in the figure below.
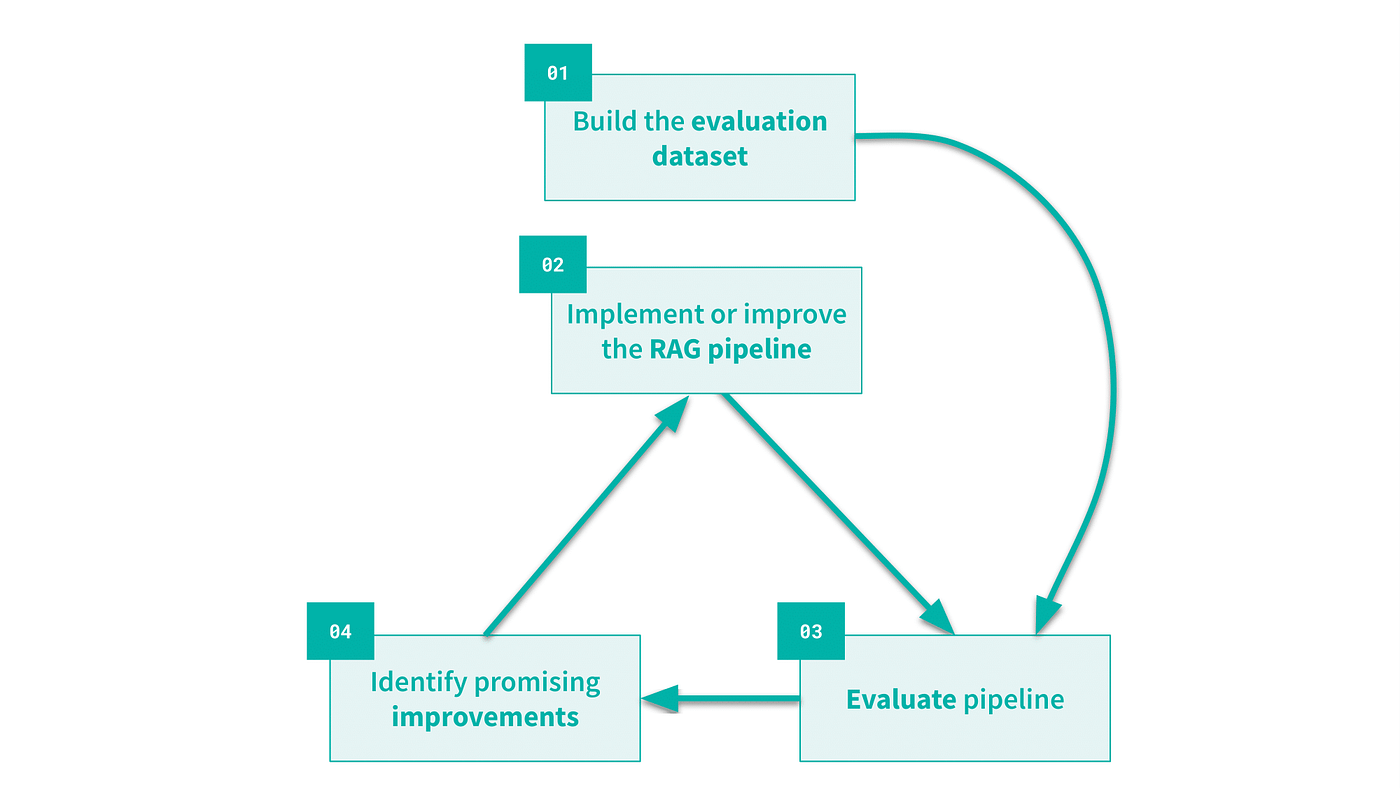
- We start by building an evaluation dataset. It should include questions and their corresponding reference answers. This dataset can be curated manually or automatically generated using an LLM. When opting for the automated approach, it is important to check the relevance of the generated queries.
- We build or improve a RAG pipeline.
- We run this pipeline on the evaluation dataset and assess the performance of the model. This requires both the computation of specific metrics, which are described in the next section, and a qualitative analysis of erroneous answers.
- Based on the analysis run at step 3, we identify the likely performance bottlenecks. This helps decide on the most promising possible improvements. We go back to step 2 to implement such improvements.
While this general approach sounds straightforward, it poses difficulties in the realm of RAG, notably in defining evaluation metrics. Let’s explore how we can address this challenge.
Quantifying Success: Metrics for RAG Systems
In traditional machine learning scenarios, the comparison between a model’s answer and a reference answer is a common practice. This holds true for RAG applications where the objective is to generate an answer that closely aligns with an expected answer. To illustrate, consider the following example:

In this scenario, the generated answer is correct but does not precisely match the wording of the reference answer. This means the evaluation metric should be sensitive to language subtleties to assess the answer correctness. Several evaluation approaches exist for this purpose.
- Initially, human reviewers can manually inspect the results and provide feedback. This qualitative assessment is valuable to uncover patterns, but also challenging to scale and susceptible to human bias.
- Alternatively, statistical methods like the BERT score measure the similarity between a candidate and a reference answer.
- Lastly, modules such as RAGAS, Trulens, and Deepeval automate evaluation using the “LLM-as-a-judge” framework. In this setup, an LLM is provided with the question, the reference answer and the generated answer and it is prompted to grade the generated answer. While this approach offers scalability, it suffers from drawbacks such as cost and a lack of transparency. In particular, LLMs have been identified as biased evaluators with ongoing research focused on discovering methods to mitigate these biases.
However, relying solely on an accuracy metric is insufficient. Consider a different scenario:

In this case, the generated answer is clearly incorrect, highlighting the need for further investigation. It prompts questions such as whether the answer was present in the retrieved context, or if the model provided a response that was not grounded in the documentation. These inquiries underscore the importance of specific metrics tailored to RAG, as summarized in the figure below.
As mentioned earlier regarding the answer’s correctness, evaluation of these metrics can be conducted either manually or through an “LLM-as-a-judge” approach. The only thing that varies is what we use as inputs for the metrics.
For instance, the Faithfulness metric evaluates whether the generated answer is suitably aligned with the retrieved context. A poor performance in this metric suggests that the model produces responses disconnected from the provided context.
Conclusion
With a robust iterative method and a set of metrics to guide us, we are set to create and improve a RAG system that fits our needs. Here are key points to remember:
- RAG pipelines offer numerous avenues for enhancement. Even minor adjustments can yield substantial improvements. The good news is that open-source packages like LangChain or LlamaIndex provide accessible means to implement advanced RAG techniques.
- RAG solutions are not one-size-fits-all. The optimal approach varies depending on the specific use case and requires a serious benchmark.
- Establishing such a benchmark for RAG poses unique challenges, primarily due to the intricate nature and opacity of generative models. Employing a comprehensive evaluation framework is imperative.
- Automated metrics should be used carefully, following thorough validation to ensure they align with human evaluation standards. It is also important to recognize that success in RAG goes beyond just accuracy. Factors like latency, costs, and maintainability play significant roles in overall effectiveness.
If you are using Dataiku, you can jumpstart your RAG projects with the reusable Dataiku demo highlighted throughout this article. Dataiku allows you to swiftly establish a comprehensive baseline RAG pipeline using no-code tools for chunking, embedding, and crafting customizable chat bot interfaces. Advanced users can leverage coding capabilities to tailor the baseline approach and explore further customization options.