




{kind=link}
I recently moved to New York City, a true abundance of riches. I wanted to find “my coffee shop,” but sampling different locales is exhausting and disheartening. I cannot fathom trying a new cafe that could have watery coffee when I already know a spot that is perfectly fine. However, my current champion is two subways and a ten-minute walk from my apartment, so the utility value is low. If I would only lean on recommendation engines to help make the choice easier, I could find a closer coffee shop that wouldn’t be terrible.
Abundance Of Riches
I am not alone in my indecision. Psychologists like Sheena Iyengar and Barry Schwartz have long analyzed the emotional cost of too many options. Schwartz states that, “imagined alternatives [induce] you to regret the decision you made, and this regret subtracts from the satisfaction you get out of the decision you made, even if it was a good decision. The more options there are, the easier it is to regret anything at all that is disappointing about the option that you chose.”
“imagined alternatives [induce] you to regret the decision you made, and this regret subtracts from the satisfaction you get out of the decision you made, even if it was a good decision. The more options there are, the easier it is to regret anything at all that is disappointing about the option that you chose.”
So if I can trim down the number of options I’m choosing from, I will feel happier about my decision. Iyengar found that consumers are more likely to make a purchase when they have fewer choices. By extension, recommendation engines will make me happier and help me drink more coffee. But this also puts me at risk of siloing my choices.
Recommendation Engines
Well-wrought recommendation engines depend on a myriad of variables to generate the best advice for users. Most recommendation engines are based on some combination of collaborative filtering and content-based analysis. Content-based analysis occurs when an engine recommends items, let’s say coffee shops, based on fundamental information about the store. So if I enjoy a cafe with wifi, natural light, and lattes, the engine would recommend other cafes near me that fulfill these traits. However, this depends on a rigorous (and accurate) metadata system of tags, so that each coffee shop has flags for power outlets or ambient music. These systems are difficult to maintain for experiential purchases, but factors into movie categories on Netflix, for example.
Collaborative filtering, on the other hand, relies on similar users' consumption and purchasing habits to inform the recommendations. This way, engines can depend on the human ability to pick up on nuance of experience. So if someone else in New York likes my favorite coffee shop, and goes to another three that maybe don’t hit all of my filtering criteria, but more accurately convey the experience of the first cafe, those are pretty good bets for recommendations.
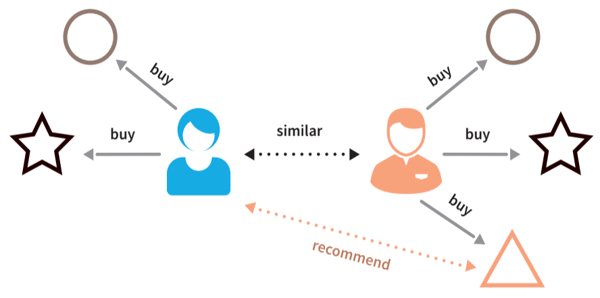
Echo Chamber
However, since collaborative filtering recommendation engines are not driven by core metrics about a coffee shop, they often become an echo chamber. If a coffee shop is ranked #1, then more people are likely to go there and perceive that it is a better coffee experience, even if the #2 spot has better coffee. And since so many more users go to the #1 cafe, negative reviews are more likely to be overpowered by positive ones, thus mitigating their impact.
When some New York-based Dataikers explored Yelp’s highest-rated coffee shop in FiDi, it was not particularly crowded. I thought the coffee was fine, but over priced. Anna Alonso claimed the latte was “not super flavorful and a little watery.” Taylor Mecham thought the espresso bore “long-lasting flavor,” but wouldn’t want to spend time in the cafe. None of us were really convinced that it was the best cafe in FiDi, and yet, it continues to receive top billing. Meanwhile, Yelp’s lowest-rated coffee shop near the Dataiku headquarters has no reviews. While we know there are other variables contributing to its ranking, it’s conceivable that the coffee is perfectly fine but no one has gotten around to reviewing it yet.
The Cold Start Problem
The term "cold start problem" got its origin from cars — when it's really cold, the engine has difficulty starting up, but once it warms up, it will run smoothly. The best recommendation engines excel at guiding us to well-received options, but have difficulty incorporating newness. While collaborative filtering enables more nuance, it is nearly impossible to know where new cafes fit into the hierarchy, or what the tastes of a new user are. The cold start problem stems from suboptimal circumstances for the recommendation engine to provide high-value results. As outlined in the infographic below, there’s no easy way to give new users recommendations beyond the generally popular, which may not suite their taste and thus dissuade them from trusting the system.
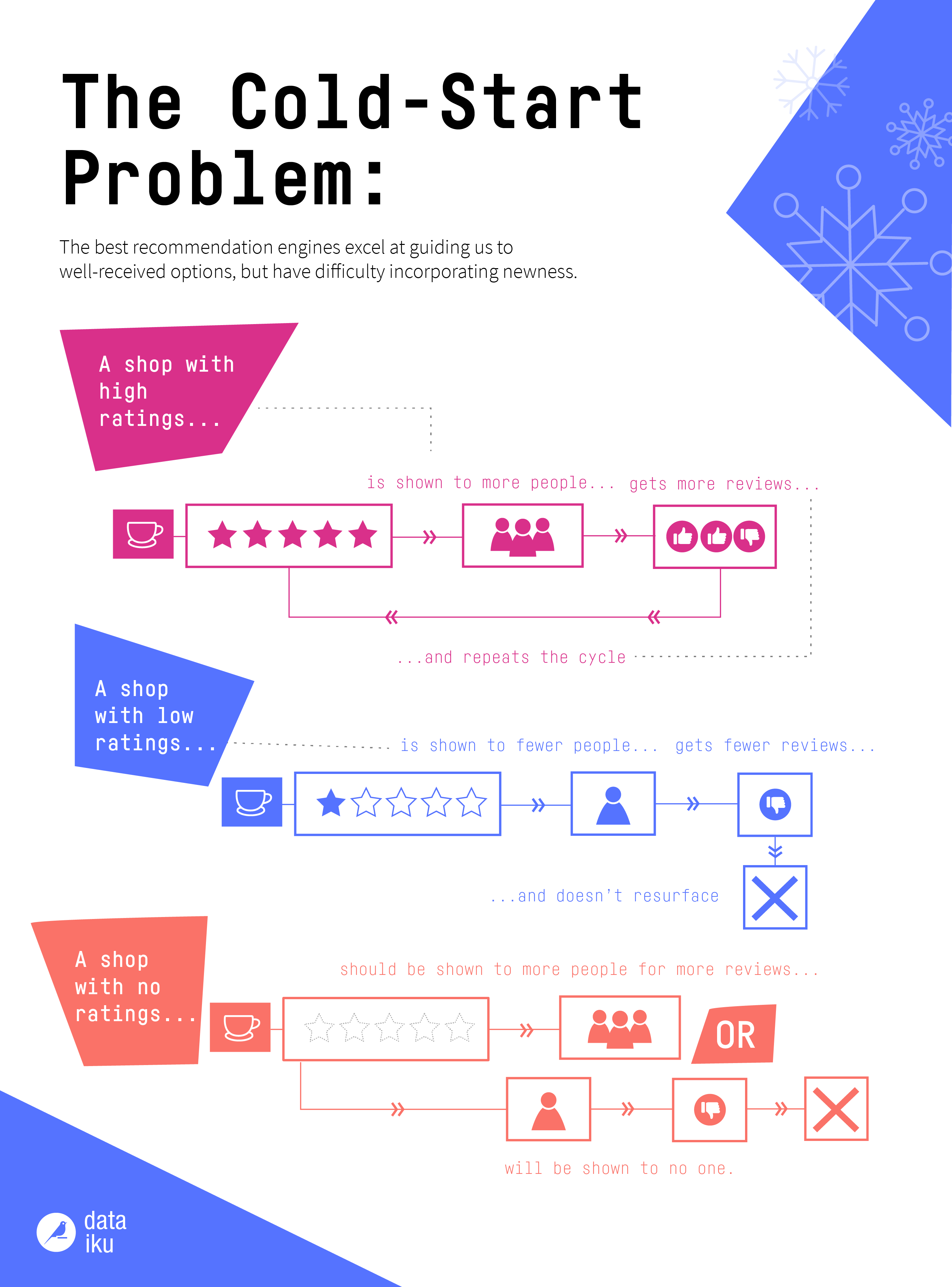
Yet new cafes suffer a worse fate. Either the engine forcibly recommends it to users in order to garner reviews, thus requiring users to perform labor that is against their best interests, or they let the first random review decide its fate. If the first review is bad, whether due to the location or the user’s tastes, it will likely not be recommended to others regardless of its actual value.
One possibility is for systems like Yelp or Google Reviews to offer incentives for users to review new locations, however incorporating direct monetary reward for reviews skews the validity of that information. However, there’s no easy solution to the cold start problem that won’t feed into an echo chamber.
Net Gains
While recommendation engines may not be perfect, they will lean on other variables besides reviews to offer recommendations when they don’t know me (or the nearest cafe) very well. This enables decision-makers to rely on both facts, like price point, and anecdotal evidence so that we can maximize our choices and decrease FOMO.![]()
However, recommendation engines only work if users trust them enough to allow them to limit their options. The cold start problem is a major obstacle to user trust. Since we know that transparency improves user trust, it is critical for recommendation engines to reveal the factors that contribute to their conclusions; in the case of Yelp it’s the review system, but other models may operate on different variable import.