




Everywhere one looks in the data blogs these days, people are expounding the freedom and scalability of a data mesh, but very little is being said about how one actually builds towards having this mystical mesh. While a microservices pattern aims to expose software as a network of discoverable, secure, and scalable atomic services, a data mesh conceives of data access and data services like inference engines as a similar set of composable data services. TL;DR: a data mesh is a microservices mesh for data services.
Dataiku makes the creation and management of these services simple, allowing you to not only build batch data pipelines, but also lift those pipeline elements into the application and data network in real time. In doing so, Dataiku does the work of implementing data mesh services. For services in a mesh, however, having the service is only part of the battle. One must present the service for consumption, document its contract, secure its use, and understand how it hangs together with other services. This article aims to walk you through the creation of one of these services, document that service as an API, and control access to that service.
Building a data mesh isn’t as simple as implementing data access and transformation pipelines. One of the hallmarks of a service or a data mesh is that all services must be well documented, discoverable, and secure by design. In this article (the first of a series) I’m going to show you how you can use Dataiku to package both models and datasets into services, document those services with an eye to promoting discoverability, and secure access to those services using an API management tool like MuleSoft.
How to Create an Inference Service
For the purposes of this article, I will assume one has an existing flow of data and at least one model they want to integrate into some real-time data access pattern. Here, we can see a simple flow: a series of steps which clean, aggregate, and join customer data together on a Snowflake backend, and create an AutoML predictive model that returns if a given customer is likely a high-value customer. If this doesn’t make sense, consider our tutorials.
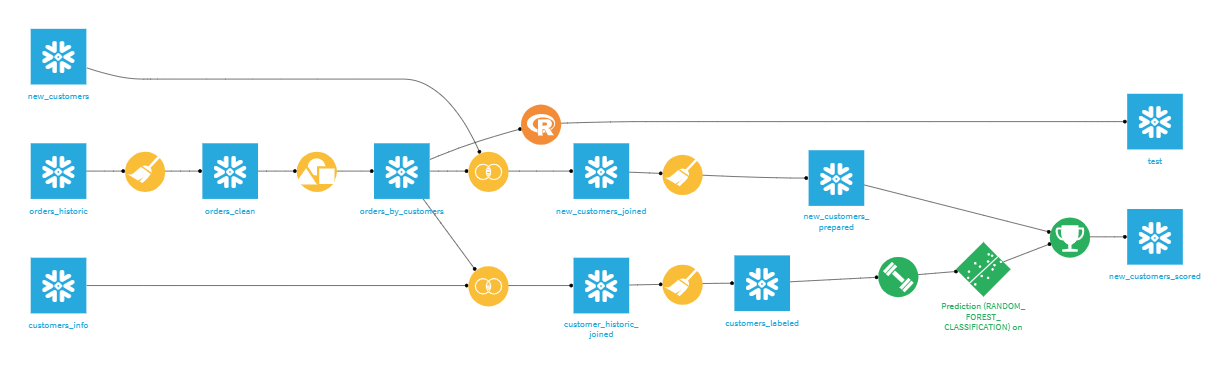
Selecting the trained model, I can generate a service implementation of that model to score data in real time:
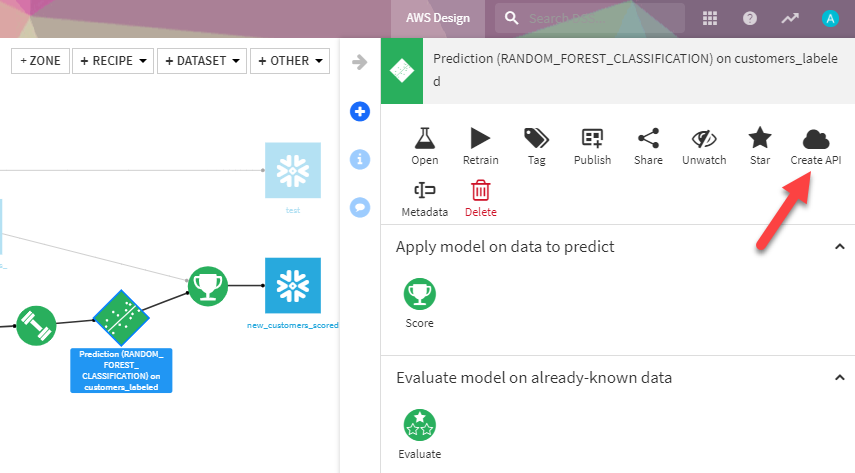

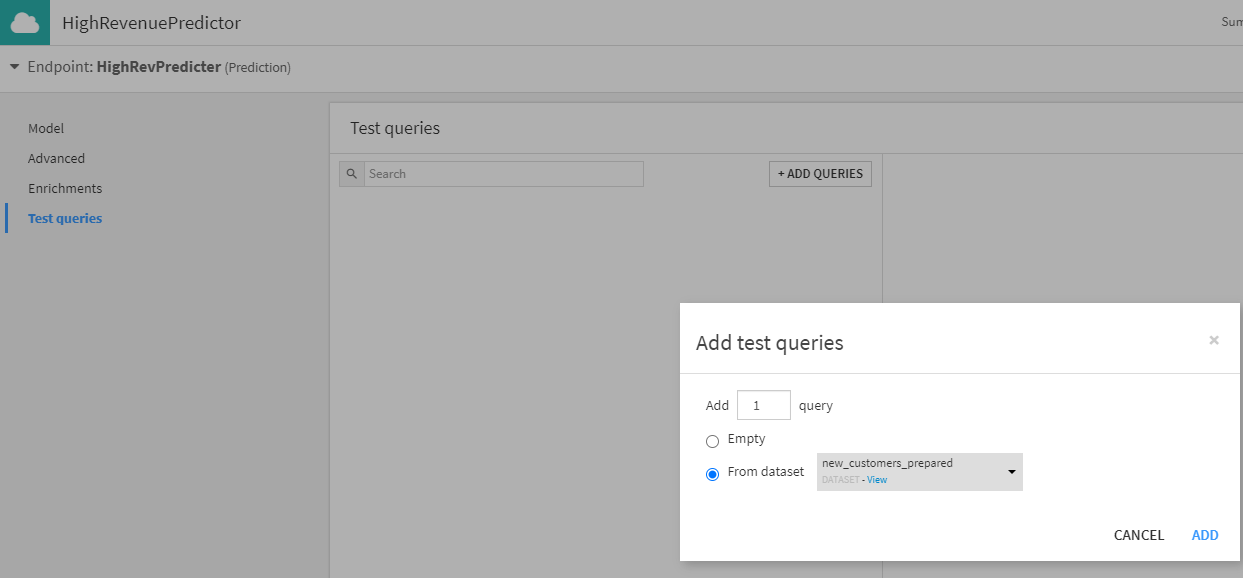
This creates a sample request which I can use to test this service; it’s useful for ensuring that the model works as intended, but also for the next steps, where I document this service for discovery and composition. With a test query created and executed, I now have a simple service defined, with a sample request that returns the prediction that I expect. Next, we’ll publish that service to our deployer and stand it up in a test environment so I can document and secure it.
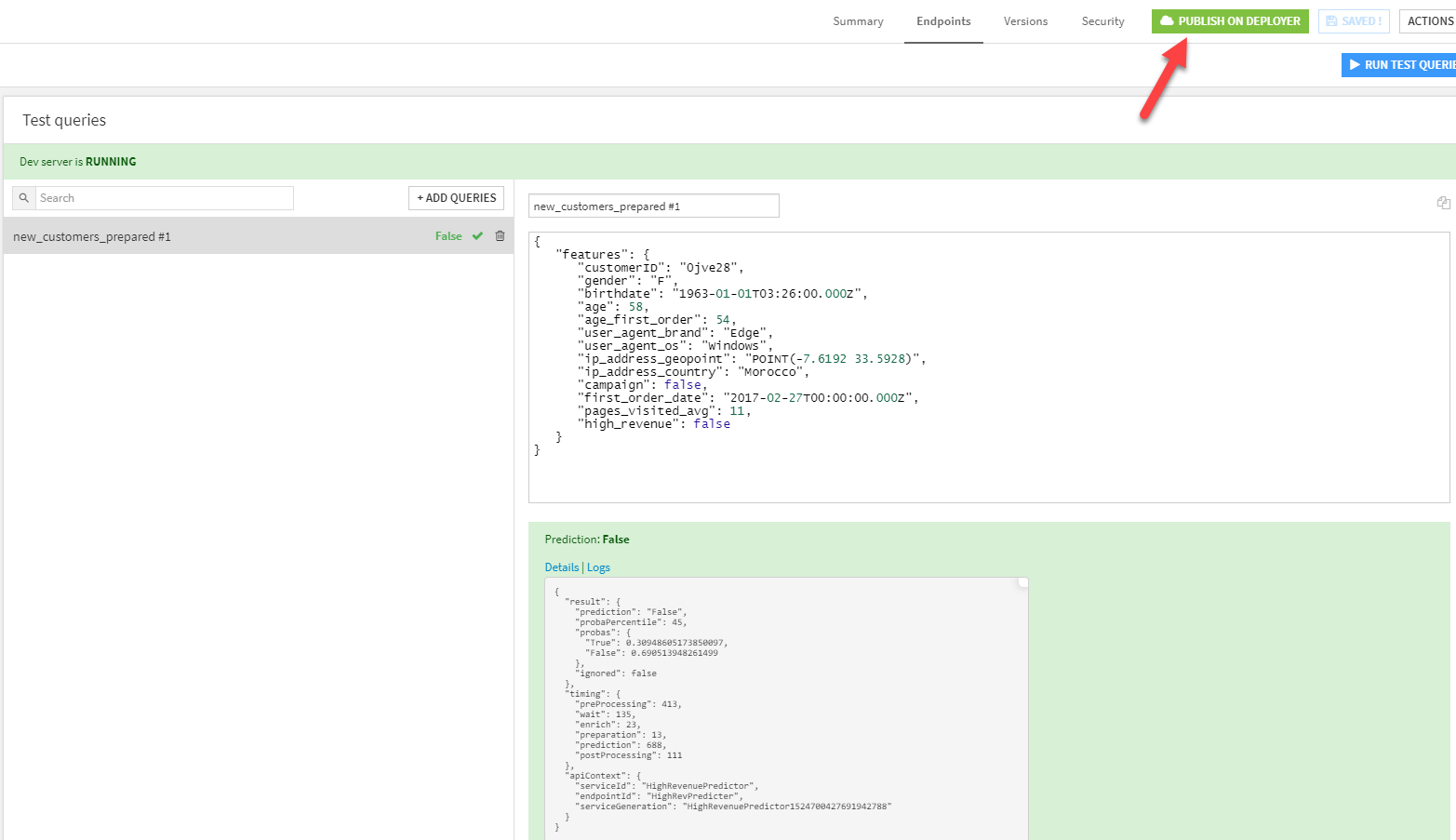
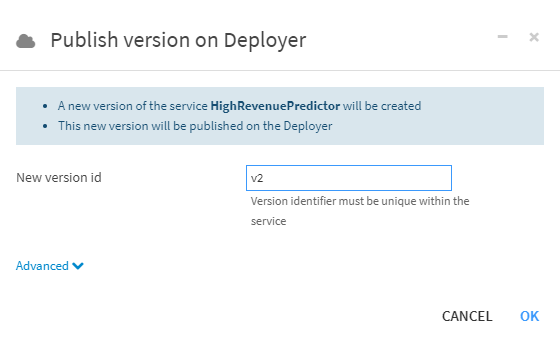
Publishing that service to the Dataiku Deployer Node lets me monitor the deployments of my new service, monitor those different versions, and sunset old versions. As this is a new service, I will deploy this service to whatever API service infrastructures (standalone API nodes or Kubernetes clusters) are available for me to run this service. In this case, I’m using a standalone API node.
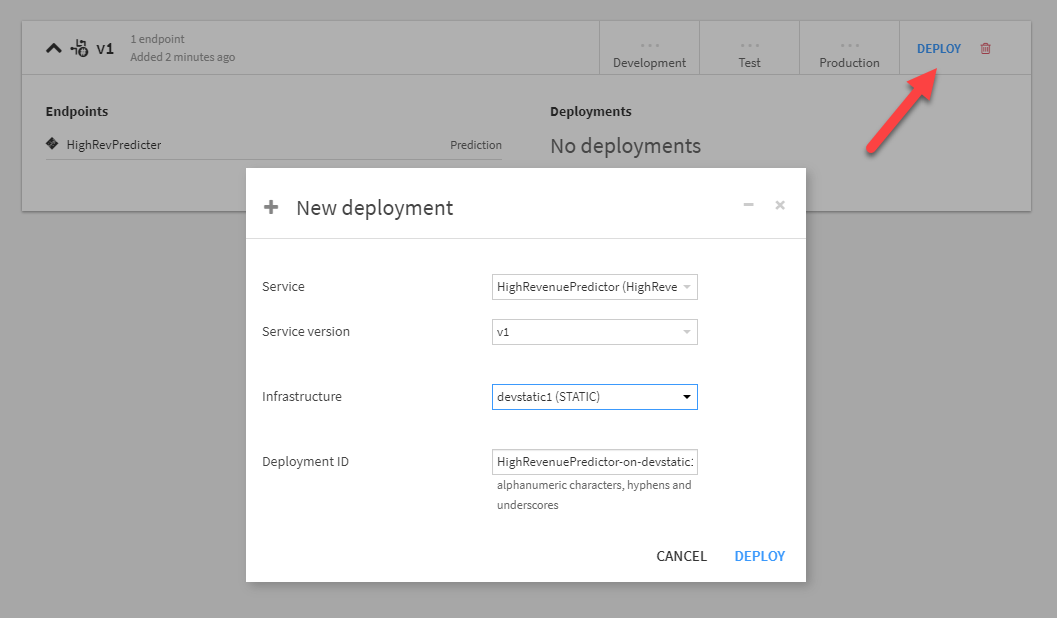
With this deployed, I have a running service which executes my model in real time via REST!
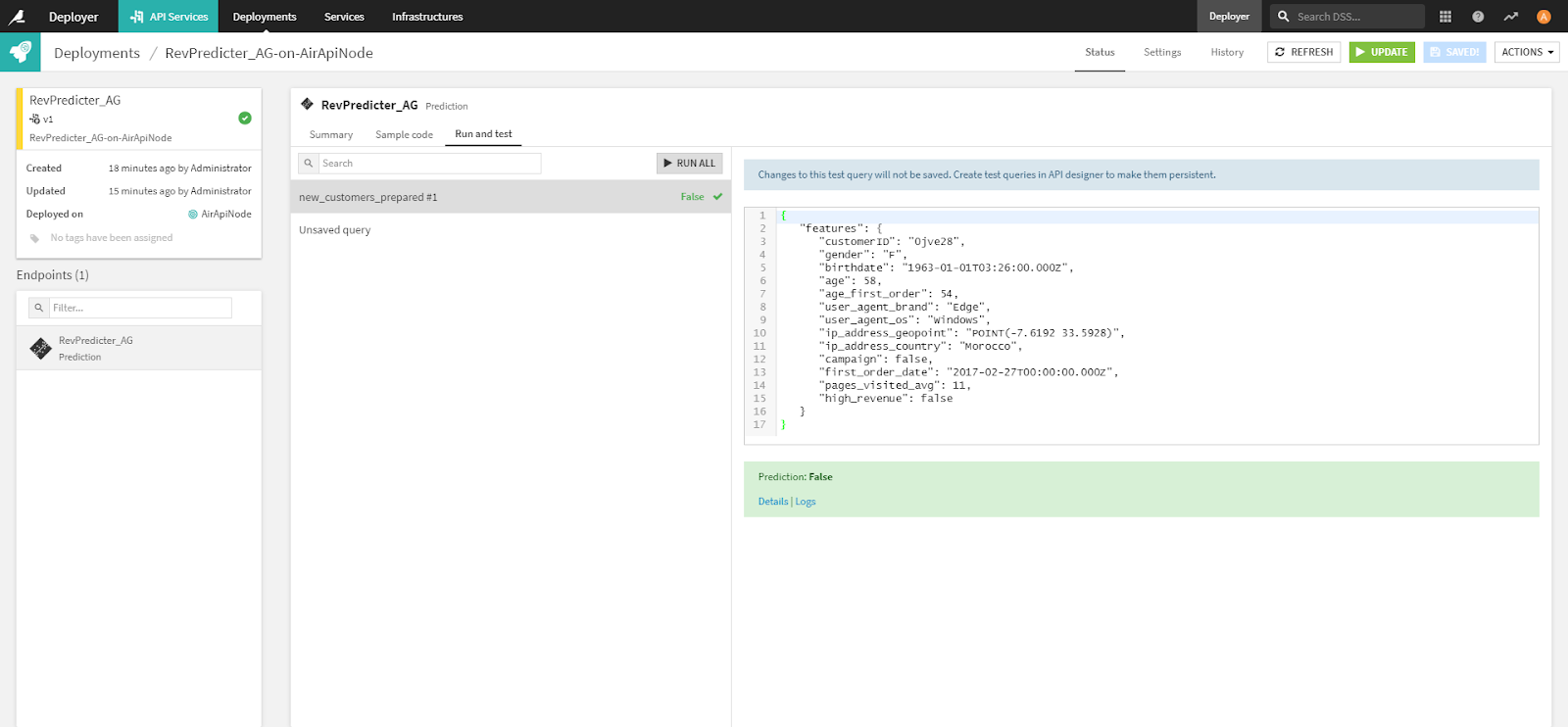
Which I can hit from my favorite service testing tool, Postman:
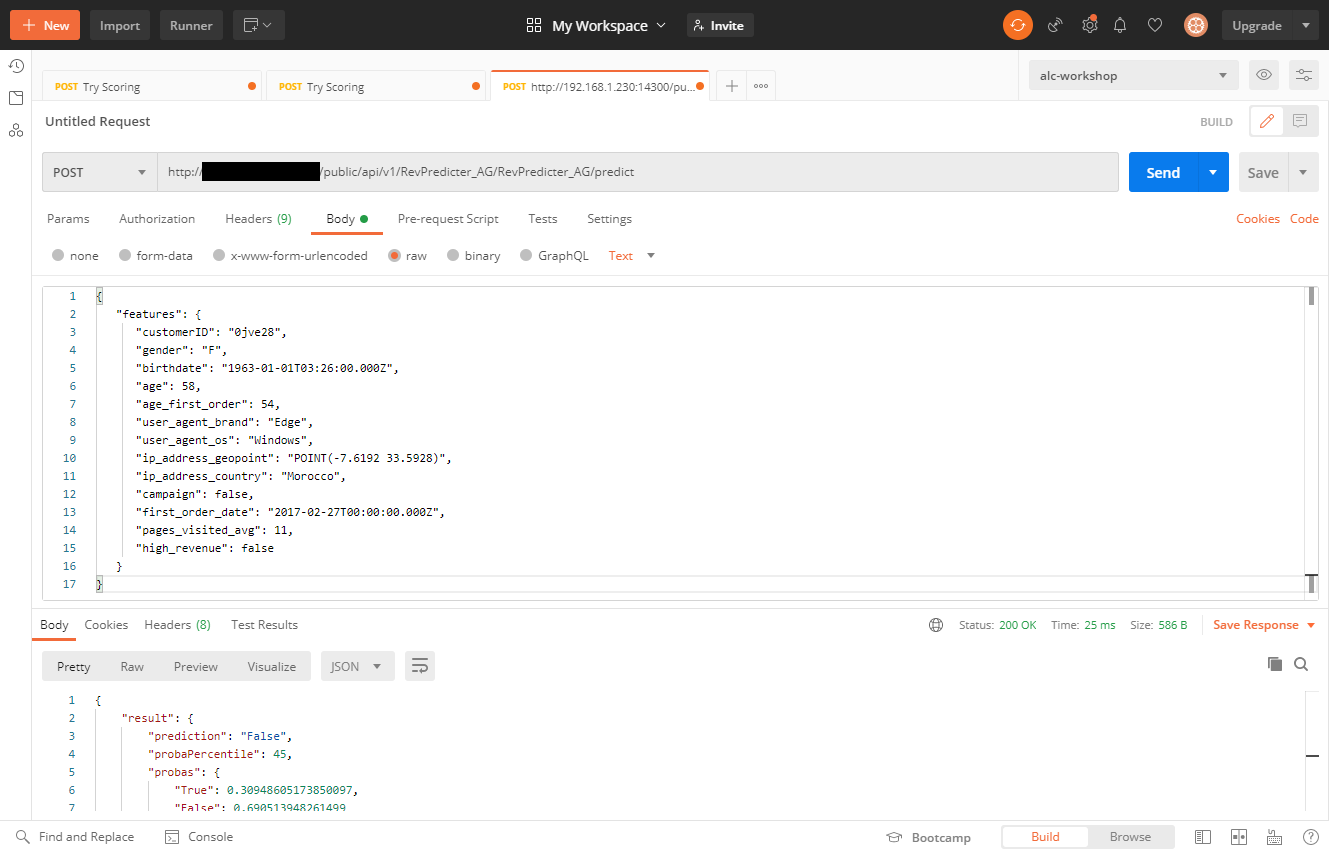
Easy enough, but as of now only I know how to find and use it, and no one knows what any of those features mean for sure. Now, it’s time to document this microservice with an API.
How to Create and Secure an API Definition for my New Inference Engine
Best practice for building APIs is to establish the API contract based on what data my consumers have and need. We’ll revisit that in a future article, but, for now, I’m going to generate an API contract from this service. For that I’ll turn to Swaggerhub and the Swagger Inspector. Swagger (or the Open API Specification) is a tool-agnostic way of describing services both to API management tools and to developers who are trying to use your API.
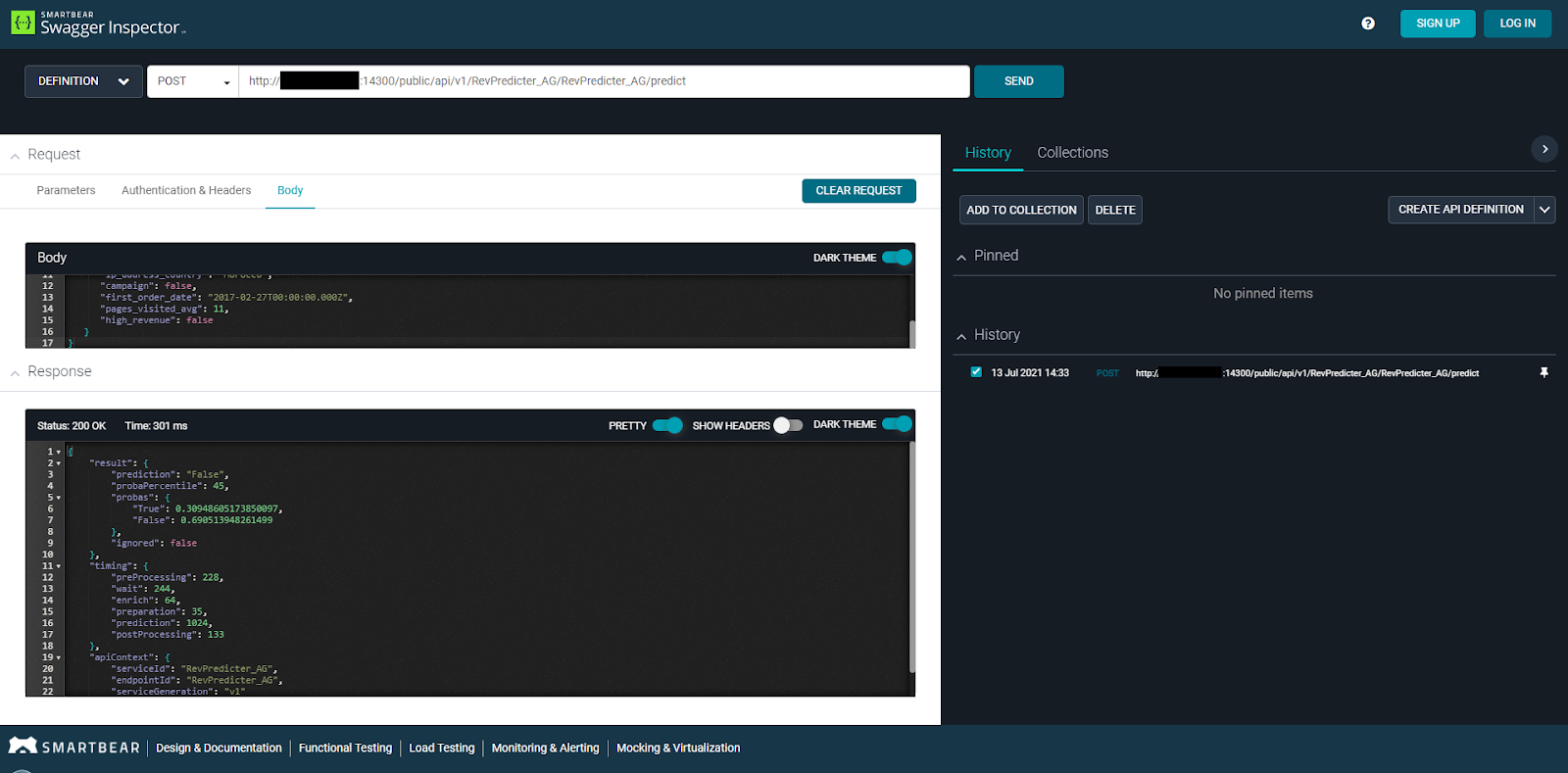
Dropping the URL of my service and the test query in from Dataiku allows me to generate an API definition from the request and response of my service. I can then edit and annotate it to describe my service to anyone who might need it!

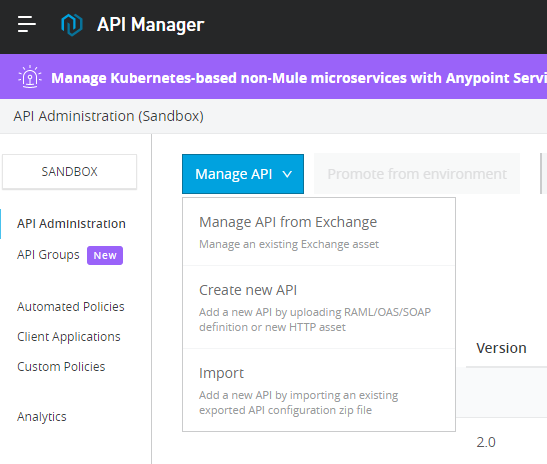
Logging into the MuleSoft Anypoint platform, I can publish this service for my integration architects to use this new service however they see fit. For this exercise, I’ll go right to the API Manager and create a new API.
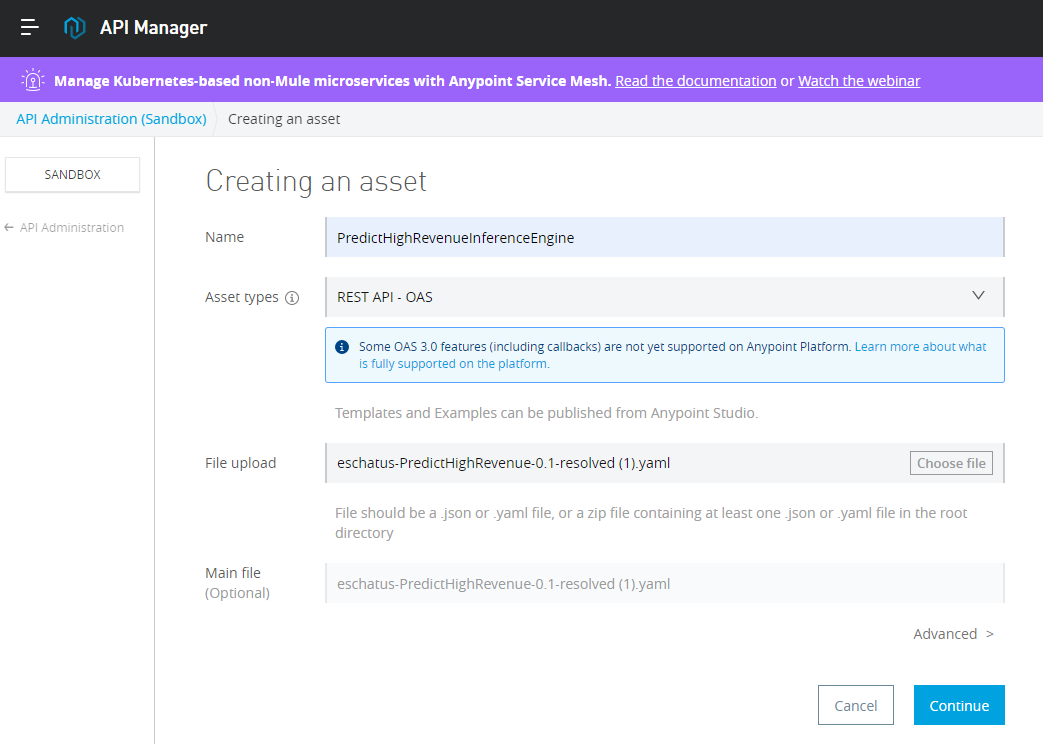
And create a proxy service, pointing it at the running Dataiku API node hosting the inference engine service:
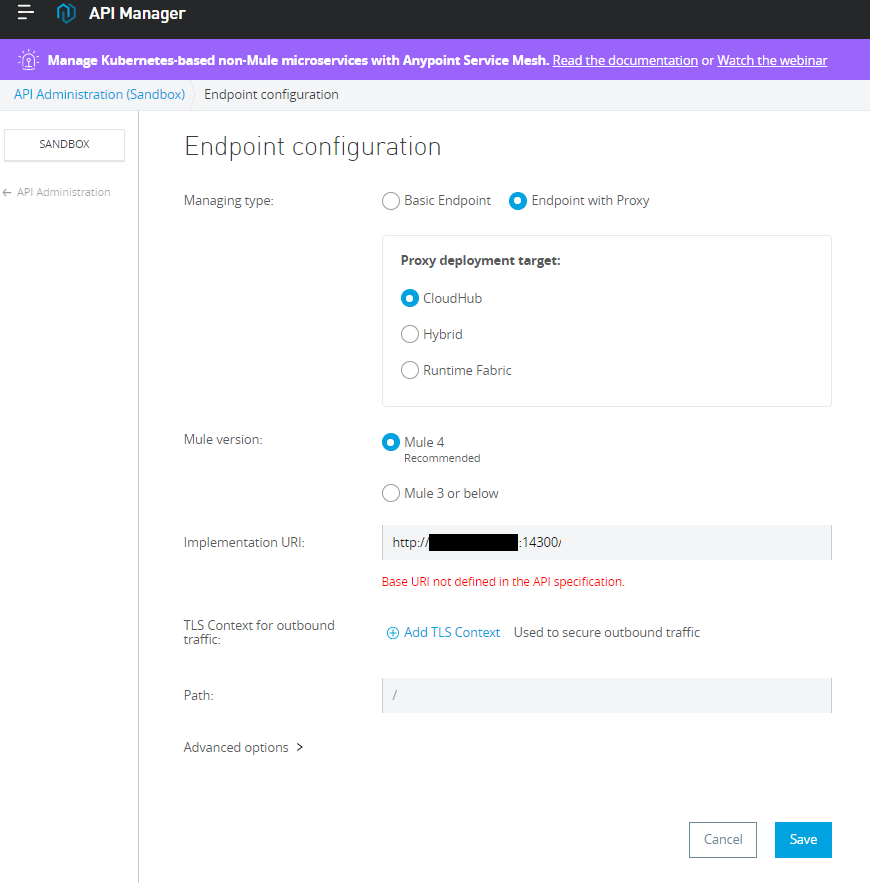
Deploying that service into the Anypoint CloudHub lets me name it something friendly:
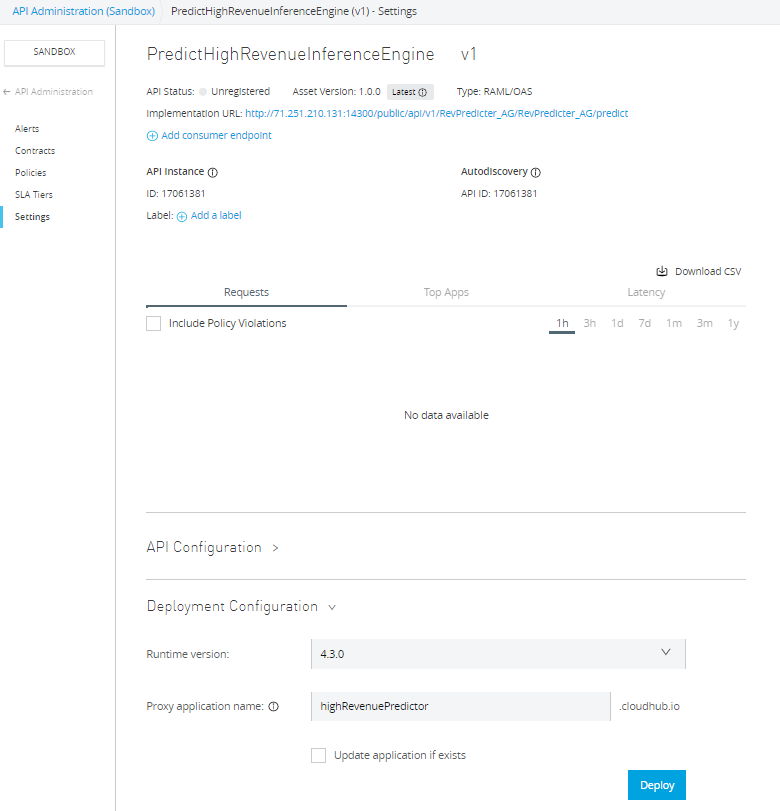
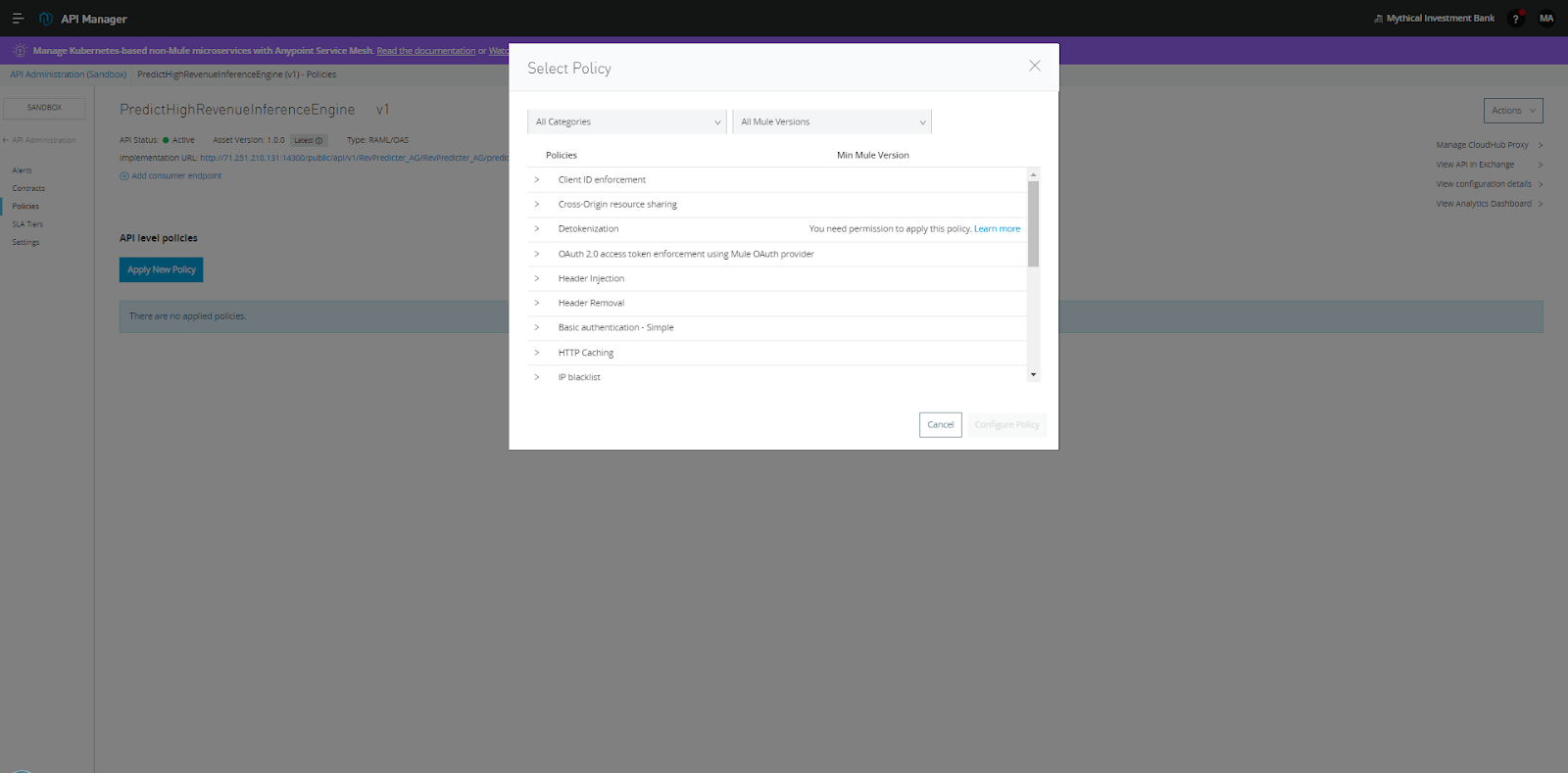
Applying the default client id enforcement policy means that users have to request client id/secret pairs to access this service now, and when I fail to send them to the service via Postman, I get denied access as expected.
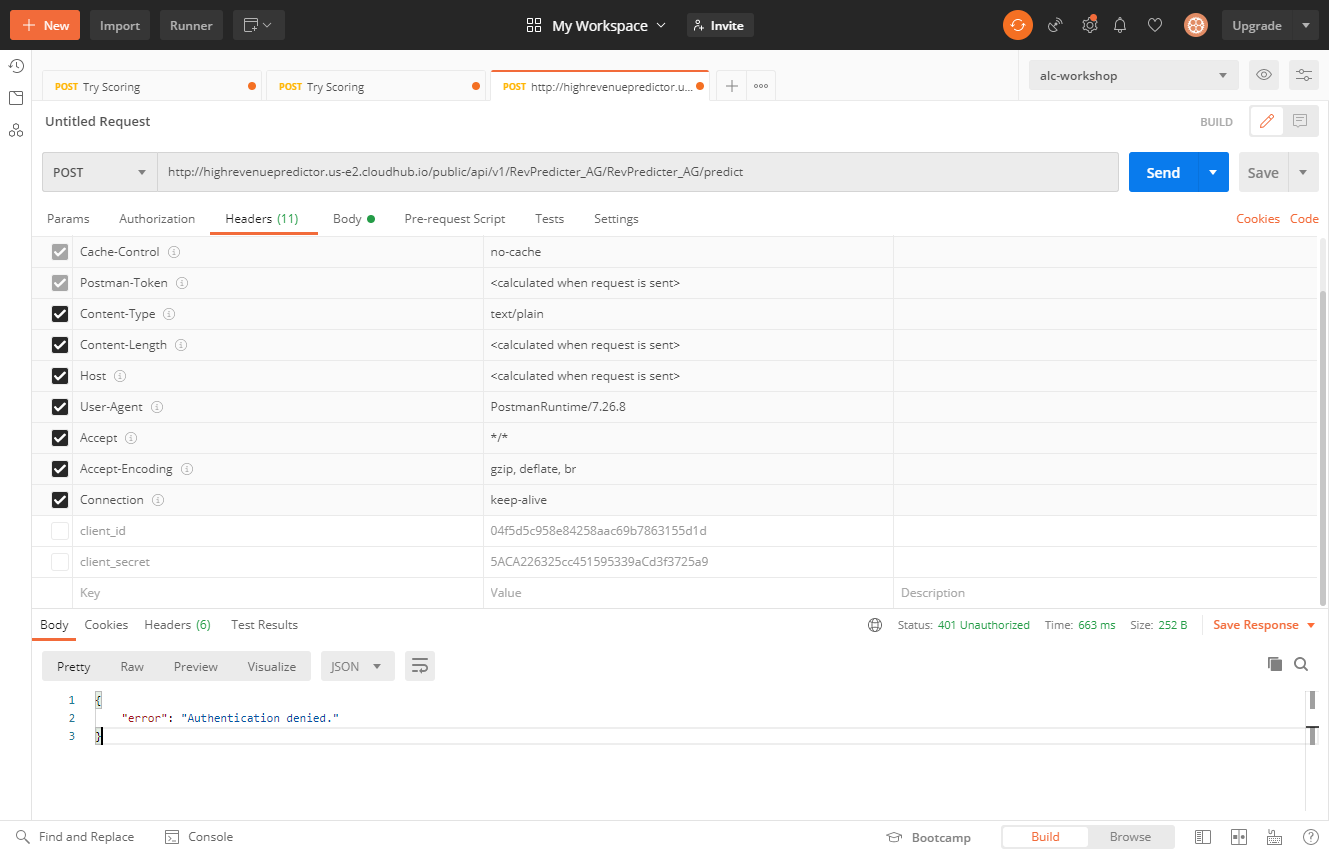
{kind=link}
But after requesting these from the Anypoint Exchange, I get through to the service in a measured, access controlled, and governed way. My inference engine is ready to join the application network and is the first node in my data mesh!
In the next of a series of articles, I’ll expand on this to expose some of the lookups for features of my training and testing data pipeline into an API for inclusion in the data mesh, discover and secure those services in my Kubernetes cluster via a service mesh, and eventually compose all of those together into a real-time data flow using the data mesh!