




ALMA, the Atacama Large Millimeter /submillimeter Array, is currently the largest radio telescope in the world. The observatory is the result of an international association between Europe (ESO), North America (NRAO), and East Asia (NAOJ) — in collaboration with the Republic of Chile — to get it built with joint intent. The telescope is composed of 66 high precision antennas and is recognized as the “most complex astronomical observatory ever built on Earth.”
The project we are going to outline here is the latest collaboration between the ALMA Observatory and Dataiku. While ALMA has been working with Dataiku since 2017 and became an official Ikig.AI partner (Dataiku’s AI “for good” initiative) in 2019, this project is the first collaboration with Dataiku’s Research Lab.
In order to effectively plan the onsite operations at ALMA, highly accurate forecasts of local weather conditions are required, as the global forecasts available do not always correctly model the local specificities of the site. The goal of this project was to do a small-scale test to see if deep learning might be able to help improve the local weather forecasts and whether it has potential to be studied more in-depth. We would like to specifically thank Ignacio Toledo from ALMA and Juliette Ortet from the European Southern Observatory (ESO) for working with us and sharing their knowledge on this subject.
In the last few years, ALMA has been working hard to improve their data infrastructure and to apply data science to their operations to ultimately improve their efficiency. In this video, see how Ignacio Toledo, Data Science Initiative Lead at ALMA, uses Dataiku to help with data evangelization within the ALMA staff and other insights about why data science is critical for astronomical observatory operations.
Getting to Know ALMA

Four of the first ALMA antennas at the Array Operations Site (AOS), located at 5,000 meters altitude on the Chajnantor plateau, in the II Region of Chile, with the Milky Way in the background. Credit: ESO/José Francisco Salgado (josefrancisco.org)
The Science of ALMA
The ALMA observatory is located in the Atacama desert in Chile and is designed to enable astronomers to study the cold and distant universe and to understand more about the origins of life in the universe.
It is capable of observing radiation in the millimeter and submillimeter wavelength range. This part of the electromagnetic spectrum falls between infrared and radio and is one of the most challenging to observe from Earth. Radiation at these wavelengths is strongly absorbed by the water vapor in the atmosphere. That is why ALMA is located in one the highest and driest parts of the world — the Chajnantor Plateau in Chile at 5,000 meters above sea level.
The ALMA telescope is composed of 66 individual antennas all operating in unison and communicating. Using a technique called interferometry, the antennas are able to operate as one giant telescope with a 16 kilometer diameter. This offers unprecedented resolution in its images and the data from ALMA was critical in the first published images of the Black Hole by the Event Horizon Telescope collaboration in 2019.

The image of the Black Hole produced by The Event Horizon Telescope (EHT) — a collaboration of eight ground-based radio telescopes who synchronized and combined their data using novel computational techniques. Credit: EHT Collaboration
ALMA’s High Frequency Capabilities
The range of frequencies that ALMA can observe at is broken down into ten smaller ranges, termed “bands,” eight of which are currently active and two more are planned. Each band offers opportunities to study different phenomena, as objects in the sky emit radiation at different frequencies.
The highest of these frequency bands are the most challenging because they are affected the most strongly by the water vapor in the atmosphere, as taking data at these frequencies requires absolutely ideal and stable weather conditions which do not occur very frequently. Even the smallest amount of water vapor can easily overwhelm the signal. Due to its unique location and technology, ALMA is the only telescope on earth which has the capability to observe radiation at these frequencies.
ALMA: The Collaboration
The ALMA project is a large international collaboration. It is a partnership of the European Organization for Astronomical Research in the Southern Hemisphere (ESO), the U.S. National Science Foundation (NSF) and the National Institutes of Natural Sciences (NINS) of Japan, in cooperation with the Republic of Chile. It is used by scientists from all over the world.
How Does ALMA Operate?
Each year researchers submit proposals to apply for a share of the telescope time. Each proposal has specific requirements in terms of the frequency of the measurements and the area of the sky they plan to observe. The data acquisition is all handled by the operations support team onsite at ALMA who must perform dynamic scheduling based on the weather conditions at the observatory. Each run of measurements lasts from thirty minutes to six hours and requires some setup time to correctly orient the antennas.

Given that the extremely dry conditions required for certain measurements in the high frequency range are rare, when they are predicted to appear the operations team must decide whether or not to change the scheduling. If the conditions do not last for the full run of data taking, the time will be lost but if they do not change and the conditions do last, they will have missed an opportunity. In order to make this kind of decision, the availability of accurate weather forecast information is absolutely crucial.
Forecasting Systems
There are two main global forecasting systems that ALMA could leverage:
- The Global Forecast System (GFS) is the weather forecast model produced by the National Centers for Environmental Prediction (NCEP) in the U.S.
- The Integrated Forecast System (IFS) is the global numerical weather prediction system produced by the European Centre for Medium-Range Weather Forecasts (ECMWF).
Both are global models covering a wide geographical area. The GFS forecasts are publicly available while the IFS forecasts are available via subscription.
The Chajnantor Site of ALMA
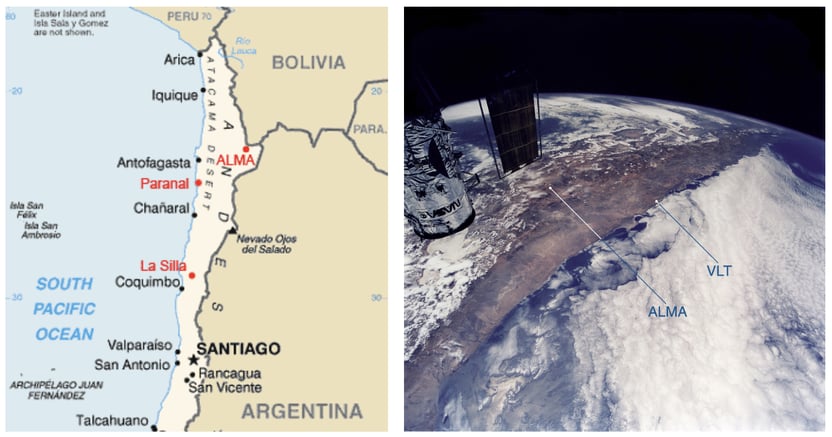 Figure 1: ALMA is located on the Chajnantor Plateau in the Atacama desert in Chile, between the Andes Mountains and the South Pacific Ocean, this is shown on the map (left) and viewed from space (right). In this photo, we can see the Andes here on the left of ALMA and the South Pacific Ocean to the right of ALMA. The influence of the cold Humboldt Stream along the Chilean Pacific coast and the high Andes mountains act as a barrier creating a unique dry corridor with little cloud cover, perfect for observing the night sky. Photo courtesy ESA astronaut Claude Nicollier. Credit: Claude Nicollier
Figure 1: ALMA is located on the Chajnantor Plateau in the Atacama desert in Chile, between the Andes Mountains and the South Pacific Ocean, this is shown on the map (left) and viewed from space (right). In this photo, we can see the Andes here on the left of ALMA and the South Pacific Ocean to the right of ALMA. The influence of the cold Humboldt Stream along the Chilean Pacific coast and the high Andes mountains act as a barrier creating a unique dry corridor with little cloud cover, perfect for observing the night sky. Photo courtesy ESA astronaut Claude Nicollier. Credit: Claude Nicollier
The Chajnantor plateau has a unique geography and its own particular local weather conditions, as shown in Figure 1. Weather systems can arrive from the Pacific Ocean or over the Andes mountains. While the GFS model can model the more impactful weather systems arriving from the Pacific Ocean, it is not as sensitive to those arriving from the Andes. The European forecasts are more sensitive to these weather patterns but were not available to us at the time of the project.
In the Figure 2 below, we can see an example of where the inaccuracies in the forecasts can cause difficulties in scheduling. For this project, we defined the threshold level for water vapor (PWV) for data taking at 0.5 millimeters, which is marked as a solid horizontal line in the figure. While in reality this is not a firm threshold, we chose to define it as such here to allow us to make simulations of decision making.
The GFS forecasts, made at six, 12, and 24 hours prior to the date are predicting that the water vapor will be lower than this threshold for more than the length of a data taking run of six hours. This means that the decision may be taken to start recording data. However, we can see from the ALMA PWV, which is the actual recorded water vapor at the site, that the forecasts have missed important rises and this would have been a false alarm.
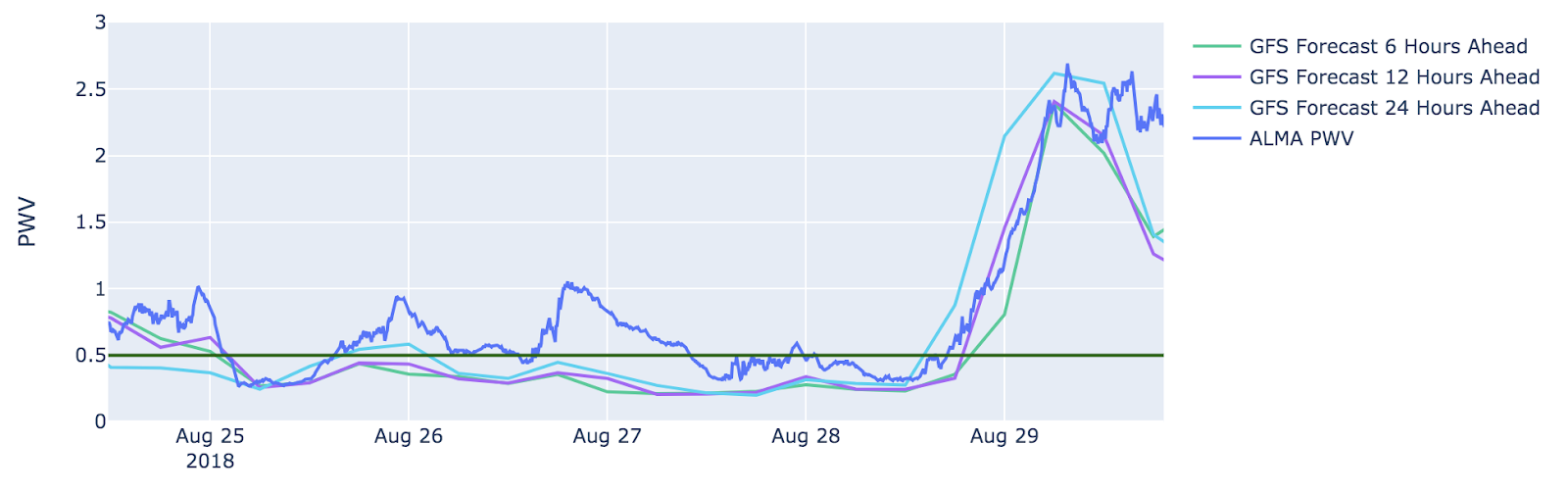
Figure 2: The GFS Forecasts at 6, 12 ,and 24 hour horizons are predicting that the water vapor will drop below 0.5 early on August 26, 2018 and remain there until the afternoon of August 28 when they correctly predict an incoming weather front. However, they underestimate an important rise towards the end of August 26.
At the Chajnantor site of ALMA, there are many weather stations to monitor local conditions. The hope is that by combining the information from these local weather stations with the forecasts, a deep learning model may be able to learn a model which is more accurate at predicting local weather conditions. This is the case especially on the time frame of six hours, which is the time frame where urgent scheduling decisions must be made, but also beyond, to allow for better planning and to minimize wasted data taking time.
The Data Sources
There were two data sources available to us for this project. The first is weather data collected at the ALMA weather stations. The data has been combined from across the eleven different weather stations to form a single dataset as complete as possible and the team at ALMA has used their domain knowledge to clean anomalous readings from the dataset.
In addition to the measurements of the precipitative water vapor (PWV) there are also measurements of the humidity, temperature, pressure, wind direction, and wind speed. The data available ranges from the beginning of 2011 to mid 2019. Once the weather data is cleaned and resampled at six-minute intervals this represents a dataset of 500,000 rows.
The second dataset is of the forecasts made by the physical weather model, the GFS forecasts. Every six hours new forecasts are released, which cover the next 120 hours at three hour intervals.
Data Exploration
In the winter in the southern hemisphere (June through August), temperature, pressure, humidity, and water vapor all tend to be lower. The peak water vapor in the year usually occurs during February and the observatory uses this period for its annual shutdown. In Figure 3, on the left, we can see how the average water vapor drops during the winter months. The image shows an average over the years 2011–2019, with variances in different years.
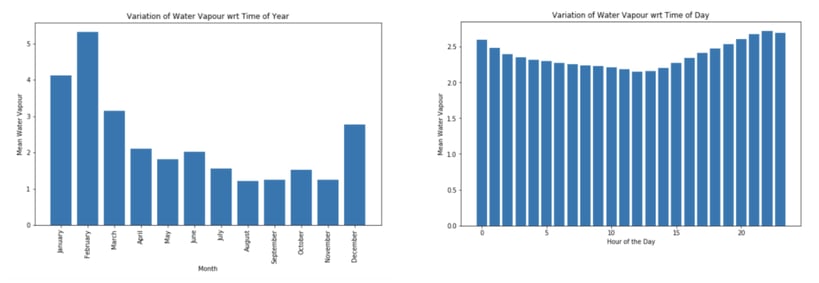
Figure 3: Plot showing how water vapor varies on average throughout the seasons of the year (left) and how water vapor varies on average throughout the day, where time is in UTC (right).
The water vapor increases during the evening, and around one to two hours after the sunset it starts to decrease. Two hours after the sunset is a range between 22:00 and 01:00 UTC, depending on the season and summer time saving hours. In Figure 3, on the right, we can see this pattern averaged over the full data period.
When exploring the water vapor data, we are able to see common patterns in the water vapor based on both time of day and time of the year. In order to assist the model to learn these patterns we can extract date components ‘hour’ and ‘day of the year’ and use them as features in the model.
Deep Learning for Weather Forecasting
For this problem, we want to make predictions over many time steps at once. We would like to have predictions at six-minute intervals covering a six-hour period minimum. We have multiple variables which could help in our forecasting, therefore we are in a multivariate, multi-time-step forecasting setting.
One advantage of using machine learning instead of traditional forecasting techniques is the ease with which you can include additional variables into the model, so it would make sense for us to use machine learning here.
Long-Short Term Memory (LSTM) models have been a popular choice for forecasting, as a type of Recurrent Neural Network (RNN) they take a sequence as input and use it to predict one or multiple outputs. While RNN models struggled to learn long-term dependencies, the LSTM model was specially designed for it.
Modeling Setup
For this project, since our goal was to do a proof of concept that deep learning could be useful for this application, we chose a simple architecture and did not spend time tuning the architecture or training parameters. We chose a simple single layer LSTM with 200 hidden neurons.
The LSTM requires as input a three-dimensional array, (batch size x number of time steps x number of features). Given that the water vapor has a pattern that depends on the time of day and that we are looking to predict the next six hours, we decided to use a window of 12 hours of historical readings as input to the model. We hope that this is sufficient context for the model to learn how the weather is currently changing. Since we are using six-minute intervals this gives us an input sequence of 120 timesteps. Our output sequence of six hours is 60 steps. For the loss, we used Mean Squared Error (MSE), which is averaged over all output time steps.
As in all modeling, we would like to have a baseline model to compare to. In forecasting, a common baseline is the naive model where you take the last observed value and predict that value for all future time steps. We would also like to see how our model compares to the Physical Forecasts, GFS.
Using Local Historical Weather Measurements
For our first model we used all six weather variables, plus the hour and the day of the year. The model was able to capture the general patterns and had a lower MSE than the GFS forecasts, because it often has more recent data. Despite this, it did not yet consistently beat the naive forecasts for this relatively short six-hour horizon. In Figure 4, we see an example forecast made at the time of the dotted line. We can see how in this case it is able to predict the general rise and fall pattern of the water vapor over the six-hour period.
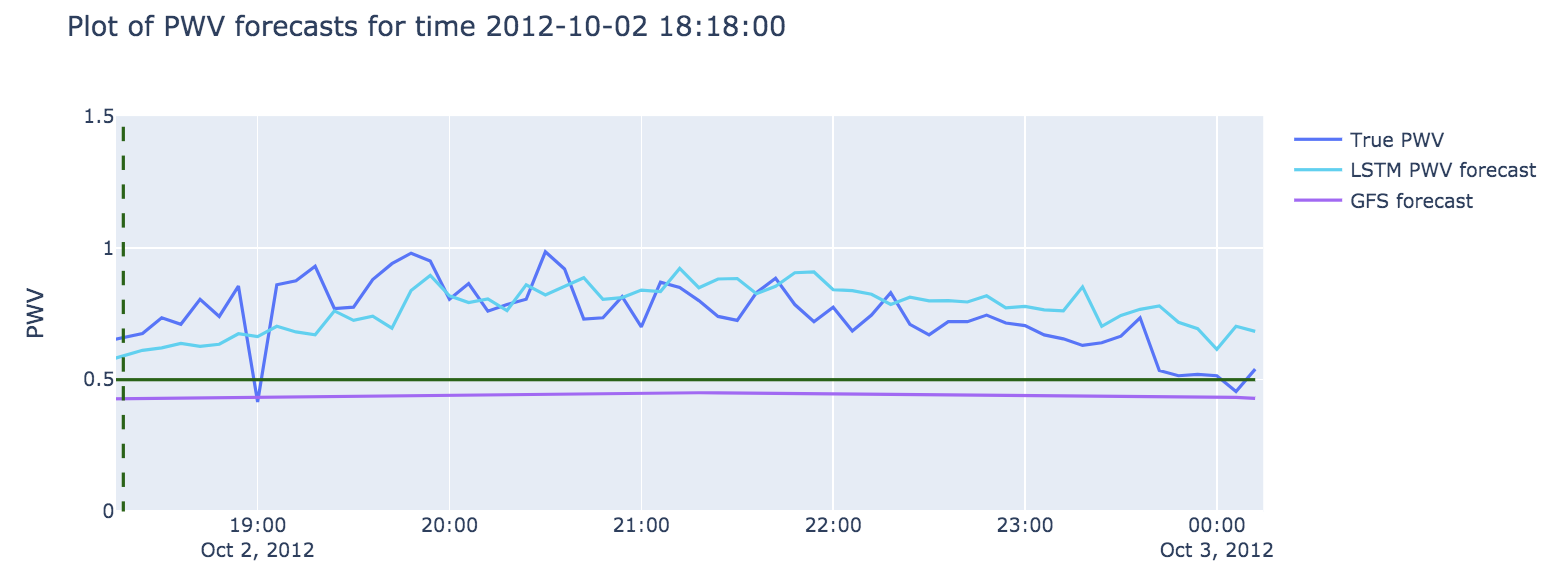
Figure 4: Example of a six-hour forecast made by a single LSTM model using only historical weather data for input. In this example of a forecast made at 18:18 on February 10, 2012, we can see an example where the physical forecasts predict the water vapor will drop below the 0.5 threshold and remain there, but the model predicts that the water vapor will rise and remain higher. Note that this example was handpicked to illustrate this case and there are obviously cases where the LSTM model does not get it right. There is still room for improvement.
Adding Future Forecasts
Next, we included the GFS forecasts as an additional feature to try to give the model information about the weather predictions over the next twelve hours. For the 120 timesteps as input features, we used the next 120 forecasts at six-minute intervals made at the last time of forecast. This could be experimented with, perhaps changing the intervals for the forecasts to hourly and using the 120 timesteps as 120 hours could include more information for the model about approaching weather systems. This reduced the MSE of the forecasts and meant that this type of model was able to consistently beat the naive forecasts as the horizon increased.
Deep Ensembles
When training deep learning models, the loss function is complex and may have many equivalent minima, although equally as performant they will result in different predictions. One way to address this is to use a committee of models to create an ensemble of neural networks or deep ensemble. By averaging the predictions from different models, we can obtain a more robust model.
To ensure decorrelation of errors between models one technique is to randomize the input data using bootstrapping. However, it has been shown that using random initializations of the model and the full data can lead to improved predictive accuracy and uncertainty estimation.
We retrained the model using ten different seeds to initialize the models and this enabled us to create a deep ensemble model. In Figure 5, we can see the smoothing effect this has on the predictions — it captures the trends but does not mimic the noise as in earlier models. This yielded the model with the lowest MSE so far.
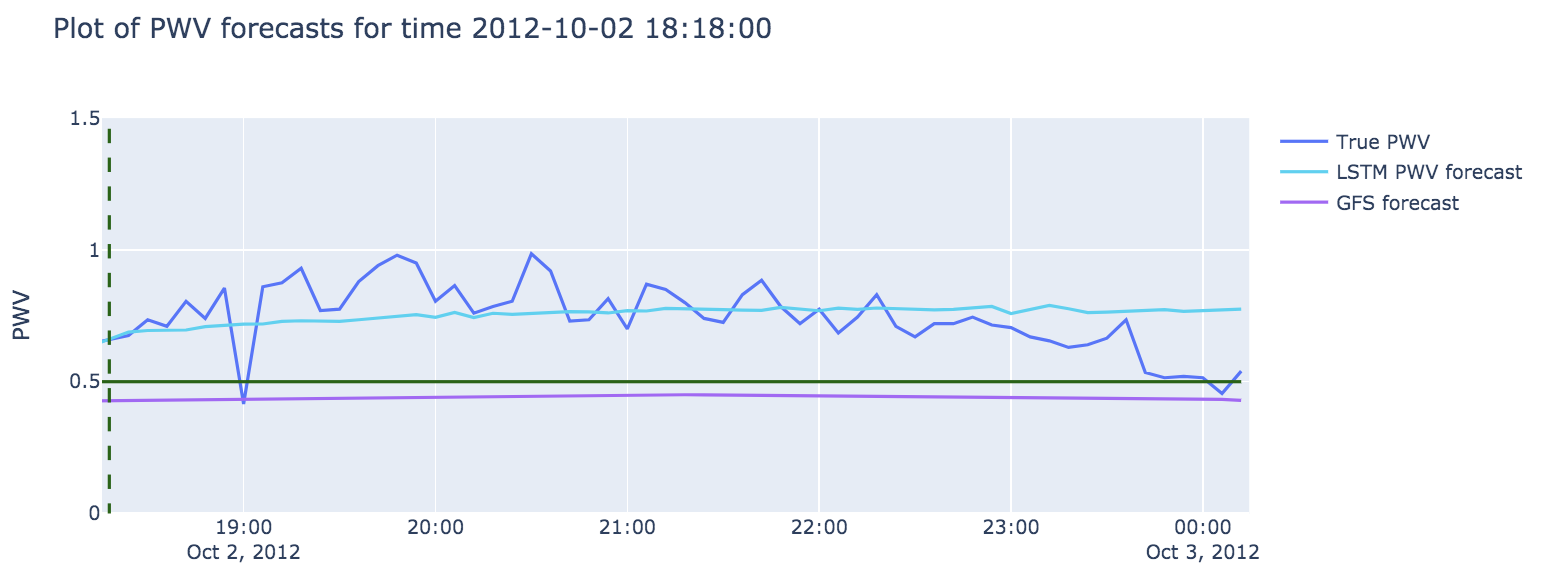
Figure 5: Showing the smoothing effect on the forecasts of the deep ensemble of the ten GFS models each trained with a different random initialization.
In Figure 6, we can see how the MSE varies over the individual horizons in the six-hour range. Each horizon represents an additional six minutes up to a total of six hours, with the MSE calculated independently at each horizon. As is expected, the naive forecast error grows throughout the horizons. Since the GFS forecasts are made less frequently only every six hours for three-hour intervals, the error rate is fairly flat and higher than the other models at low horizons, as it tends to have less recent information.
The strength of the GFS forecasts is in being able to forecast at much longer horizons (up to five days), which enables longer term planning. They are shown here just for comparison. The LSTM ensemble model error does increase over the full horizon but significantly less than the naive forecast.
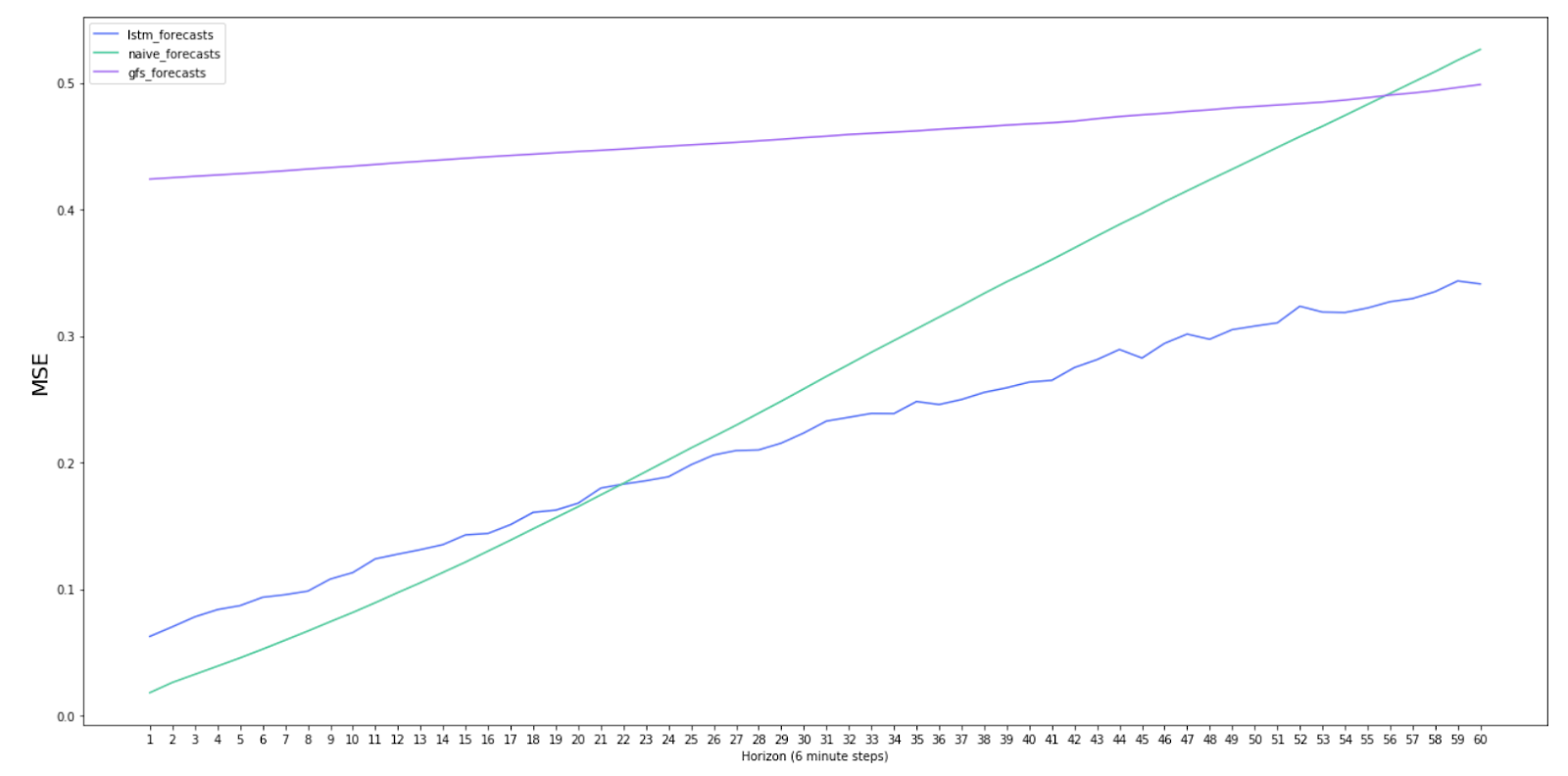
Figure 6: Graph comparing how the MSE varies for each model as the forecasting horizon increases.
Results
MSE
We have measured the MSE for the different models we created and compared these to the GFS forecasts and the naive forecasts over the entire six-hour period of 60 forecasts. We trained ten iterations of each model each with a different initialization, which allowed us to calculate the mean and standard deviation of the MSE for a single model. These are shown in Table 1. We can see that the addition of the GFS forecasts as features reduces the MSE of the models.
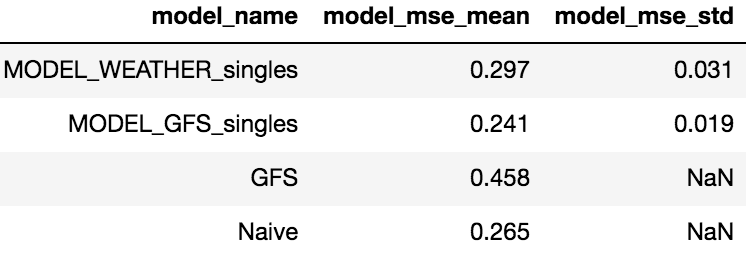
Table 1: Table showing the mean and standard deviation of the MSE for the single LSTM model forecasts, where MODEL_WEATHER is the model with only weather variables and MODEL_GFS is the model which also includes the forecasts as features, the naive forecasts, and the GFS forecasts. Since there is only one set of forecasts from GFS and the naive method, there is no standard deviation.
Using these ten models, we created two deep ensemble models, one with only the weather and date data as features, the other with the GFS forecasts as additional input. We can see in Table 2 that this improves the model and our ensemble including the GFS forecasts is able to outperform both of our baseline models, the naive forecasts, and the physical GFS forecasts.
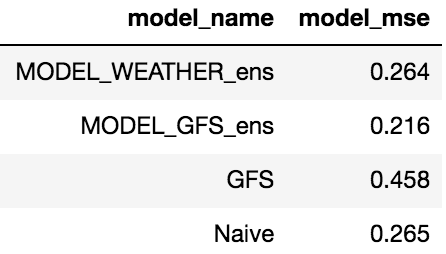
Table 2: Table showing the MSE from the LSTM Deep Ensemble models, the GFS, and naive forecasts.
We have also calculated the MSE at each individual horizon, which allows us to visualize at what point the model begins to improve upon the naive model in particular, which is around two hours, shown in Figure 6.
Data Taking Simulation
Although MSE can give us a good idea of how accurate our forecasts are generally, we would now like to understand how these forecasts could help with the operations in practice. That means being able to accurately predict when the water vapor will go low and stay low long enough to take a full run of data so that data taking time is not wasted if the decision is made to record data in a high frequency band. In order to assess this, we made a simplified simulation of the decision making process.
In this simulation, if at any given point, the forecast says that the next six hours will be good and the actual water vapor is below 0.5, we begin recording data. We record data until the true water vapor rises above threshold. If we have less than six continuous hours, we must discard the data, which counts as wasted hours. Otherwise, we can count the number of hours recorded. In the example in Figure 7, we can see that the GFS would predict six good hours of data, as the true water vapor is low. We would begin to take data, at around 13:40 the water vapor goes above threshold and we would stop the run. At less than six continuous hours, the data would be counted as wasted hours.
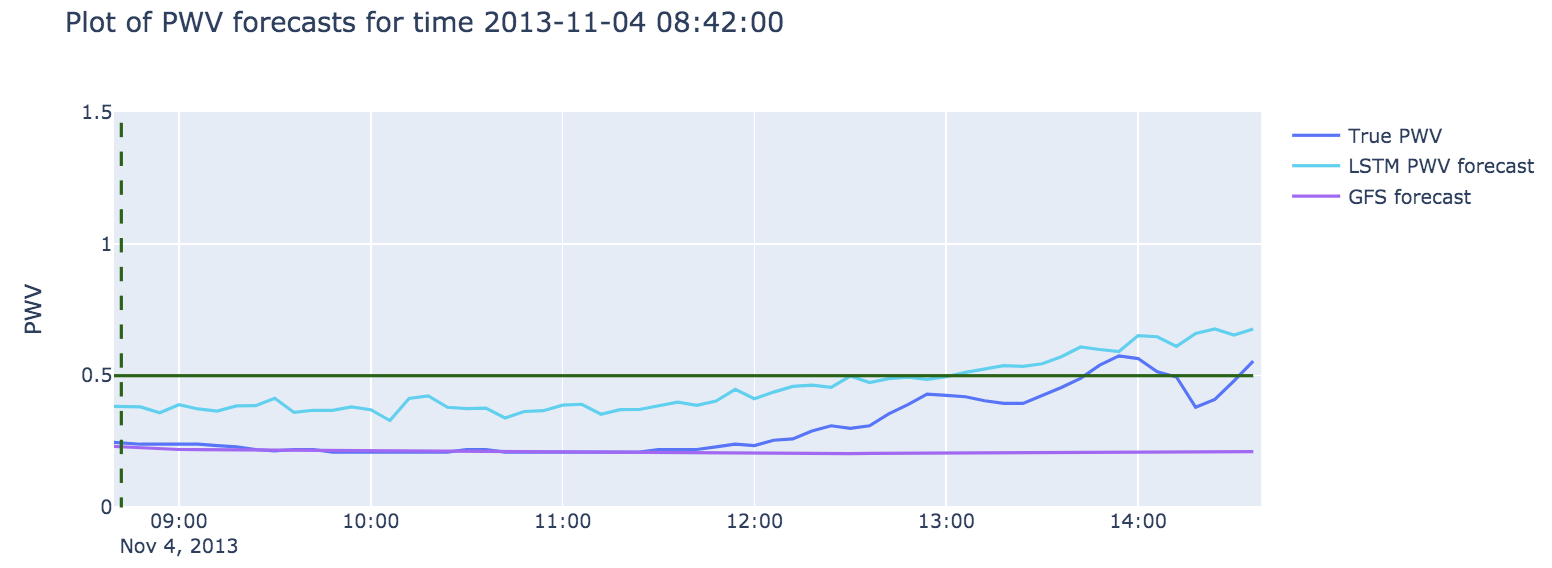
Figure 7: An example showing a situation where data taking would commence and result in wasted hours as it would be discarded before reaching a full six hours.
We ran this simulation for the LSTM ensembles and the GFS models. The tradeoff here is that if you frequently predict the water vapor will go low and stay low, you will record more data. Resultantly, you will miss less periods, but you will waste more data. If you miss a data taking period for the high frequency band, you will still be able to record data in a lower frequency band, so wasted hours is considered a worse error. For comparison, the true number of hours in blocks greater than six hours is shown as valid hours. The results are shown in Table 3.

{kind=link}
Table 3: Table showing the number of hours recorded and wasted in this simple simulation by each of the LSTM ensembles and the GFS and naive forecasts.
We can see that our ensemble method including the GFS forecasts leads to a reduction in the number of wasted hours by 12%.
Our conclusion is that this approach is promising. Using only a very simple model we are able to be competitive with the current forecasts and this early study indicates that deep learning can help to tune the local accuracy of these global forecasts. We have identified some avenues to explore ways in which this simple model could be improved.
Possible Next Steps
Improving the Architecture
These models have a very simple architecture and have not been extensively tuned. Testing simple variations such as additional layers and tuning parameters such as the number of neurons per layer may bring improvements. Different, more complex architectures could be tried. For example, the attention mechanism brings improvements to long dependency learning and could be more powerful as we increase the length of the history sequence.
Extending the Forecast Horizon
Currently the GFS physical model forecasts for the next 120 hours, although for this practical application, the key factor is to improve the accuracy of the forecast for the immediate future. If the model can offer the same improvements over the longer horizon, that would allow for better planning.
Updating the Forecasts Used
The European IFS forecasts are considered to be more accurate than the GFS forecasts. Once available, these could be added to the model or used to replace the GFS ones. This would be expected to increase the accuracy of the predictions.
Custom Loss Function
In this particular context, there is one region where the accuracy of the forecasts matters most, the region of low water vapor. A custom loss function could be used which gives greater weight to the errors in the region of low water vapor that we are interested in.
Uncertainty Estimations
In order to be useful for decision making, it will be necessary to calculate the prediction intervals of the forecasts for the final model.
Once the final model is chosen with its prediction intervals, the model could be deployed as a web app to be used by the teams handling the operations and the predictions could also be used as inputs to a decision making model targeted at optimizing the schedule.