




Building on the feedback and extensive interest in my colleague Doug’s blog post, we decided to go a bit deeper into the subject and show — with real-world examples from our customers — what is possible today in a series of blog posts on digital twins.
So let’s take a step back. What is this fuzzy concept of “digital twins” the industry is talking about? At the very least, it is a representation of a real object or process. This is given the technical term of a “system.” However, when the term “digital twin” is used, we have little insights about the extent of detail, limitations, and method of creation used — the term is loosely defined and bears quite some ambiguity. So, let’s take some cases to show what could be considered a digital twin, such as:
- (Business) process or object: Do you describe a behavior or a physical “thing”?
- Chicken or egg: Is the digital twin there first or the physical object/process?
- Correlation and/or causation: Is the twin purely descriptive or does it fully capture the real system with its inherent behavior?
- Statistical or analytical: Is the twin purely built on statistical likelihood, e.g., via Bayes inference or does it depend on analytical foundations?
- Bottom-up or top-down: Is the system modeled by taking a part-by-part approach that is then stuck together or do we approach the system from an overall perspective?
Within these (non-exhaustive) categorizations, you can find plenty of things that may be defined as digital twins, which is far from a “razor sharp” definition. Your digital twin can help you to understand the real system better, or even make it possible to imagine the real system before it actually exists. This system may be very small in terms of scope, or it may encompass entire factories or even the entire planet. The insights derived can be manifold: visualizations of how it could look, KPIs on how the system acts in certain situations, optimal dimensions of how you might size it, or a suggestion of how to act in a certain scenario.
What all digital twins have are inputs, parameters, a model structure, and hyperparameters, as well as outputs — and that is independent of the type. Inputs and outputs may be simple numbers, but they can also be complex data types, images, or topologies / vertices.

Interconnection of the real system and the digital twin: In case the real system exists, you can use data/observations and, optionally, domain knowledge to derive insights. If the real system does not exist yet, you can build on existing domain knowledge to create the digital twin first.
The choices depend very much on the problem you are trying to solve — and, as often, the right choice is somewhere in between! The good news is that the access to computational resources, availability to data and tools like Dataiku give you options that were not available before.
Digital Twins Built on Engineering Principles
The concept of a “digital twin” was initially used to describe a modeled representation of a physical product (especially in the automotive and aerospace industry) to speed up the prototyping phase. In short: You could evaluate, optimize, and visually inspect the product before it was built in reality. In this case, the twin was born before the real object! It was (and still often is) based on computer-aided design (CAD) and subjected to all sorts of engineering type simulations such as strength analysis (FEM) or aerodynamics / flow field (CFD) plus, oftentimes, renderings of the final design outcome. In this case, the simulations were grounded bottom-up by well-known physical principles and solved to create the answer needed. Several industries have been building representations of real systems for years, and this methodology is taught in engineering school. One could even argue (and indeed many scholars have!) that the entire foundation of engineering is on modeling real-world systems.
In 2010, the term digital twin was coined within a NASA roadmap report to describe taking this whole method to the next level: a more general connection between real world, digital world and connections with its scope extended towards full immersion and significantly larger objects, up to entire factories or, in the case of NASA, a rocket assembly. Here the breadth of the term gets visible: You can build a digital twin of a simple motor, a complex turbine, or an entire airplane — and the levels of sophistication are quite different.
Also, depending on the question you are trying to answer, the depth of such a model can be very different: For a motor, it might not be interesting to include phenomena such as temperature or a chemical reaction, but for a turbine burning fuel, you surely need to! That also means that you of course cannot answer questions or derive insights on properties you have no data on, or have no additional domain knowledge.
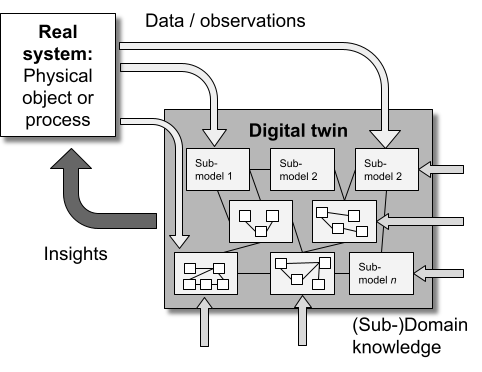
{kind=link}
An imaginary, bottom-up digital twin built of many (cascading) sub-models or models — each of which can be linked / fed with data / observations or (sub-domain) knowledge. If you do not have the data yet, as the real system does not exist yet, you can build bottom-up based on physico-chemical / engineering knowledge to derive insights before the real thing exists.
So it is by no means new to model systems bottom-up, fitting parameters and using this for designing, understanding, and optimizing systems. Indeed such complex models, built bottom-up consisting of physico (chemical) relations/correlations put together by specialist tools are digital twins. You basically put knowledge in, and get “measurements” out as you would get by taking the same property from the real-world object. Being able to forecast behavior, even outside of the initial scope is an advantage of such model-driven digital twins — and indeed the reason why they are used in engineering to design things (e.g., bridges, airplanes, chemical reactors, or cars). But building such accurate models requires significant know-how, extensive resources, and the right tools.
Once you have such a “full representation” of the real object, it can be used and extended towards new uses. For example, a CAD model of a car could be rendered for an augmented reality case and be subjected to a virtual crash test. Altogether, it is a “solved problem” — but sometimes it may not be the smartest choice to go this route, as this can be costly, time consuming, and very resource intensive and it might not be required after all to answer a specific question.
Going the Reverse Way: A Digital Twin Born From Data
One can also go the reverse way and take measurements of a real object to infer the digital twin from it! Take your cell phone and take pictures of a teacup on a saucer from all sides… You can now reconstruct a 3D model of this cup — a simple digital twin was created. However, without additional data, you could not say for sure that the saucer underneath and the cup itself are two different objects. This simple example shows the limitations of the reverse approach: You do not need a lot of data, but you need the right data to describe the object to furnish this digital twin. Altogether, data-driven digital twins are also not that new — and, again, they come in all different flavors and complexities.
If you think a step further, you could even come to the conclusion that Newton’s first law on gravity (and most other “First principle” laws) may be the simplest form of a digital twin. It is based on the observation of the apple falling down from a tree — plus of course a good number of measurements on the proportionality of mass and gravity until it was accepted and “codified.”
In this way, many sciences infer relationships from observations to create a model, which subsequently can be used as a digital twin, or as part of a bottom-up model. Of course we would not want to go down the road of proposing another “First principle” law — and we do not need to in order to get the benefits! Given the right data, you can get significantly more complex relationships and get high-quality answers rather quickly.
However, building such models based on observations, one has to be quite careful on the limitations on where the digital twin is applicable: The smaller the range of observation is, the more limited the scope will be, as these digital twins are purely descriptive to begin with. Surely the amount of data available to sustain data-driven models has significantly increased and new computational methods are available, plus tools and workflows in Dataiku can help you spot such issues.

Philosophically speaking, all the neural networks out there form some type of descriptive digital twin of the observations fed to them — and, subsequently, mimic the real system they are modeled after. Here, you may build a digital twin of a “customer,” to understand customer behavior or do even a whole cityscape and use enormous amounts of data to segment, describe, and predict the choices a customer will make in a given situation. Once you use such a digital twin with new data it was previously not exposed to, the outcome may be inaccurate as we can only describe situations we have previously seen by this “descriptive” approach. Here, a specialized software solution like Dataiku can help you keep an eye on it.
Also, such a digital twin is limited — you can most likely only use it for the purpose it was built. For example, the digital twin of a municipal water grid may be used to learn about consumption and utilization in certain pipes, but surely you would not use it to find out where a certain pipe is buried within which street and have a virtual view of the whole grid on a map. It might be limited in scope, but it can deliver tremendous performance on a certain, specific task where the “whole deal” is not even required Here, data-driven models can solve tasks hundreds of million times faster than running a full simulation, saving tremendous cost and speeding up the development cycle.
Even less than two decades ago, the use of purely data-driven digital twins was left to experts, based on the sheer amounts of data, the computational resources required, and the complexity of algorithms required (often code in Fortran and C, to be executed on high-performance computers). Nowadays, building a data-driven digital twin is democratized — you can do it with tools like Dataiku, which provides access to scalable computational resources, storage, and ready-to-use ML stacks, even in a low-/no-code fashion if you like that.
Practical Approaches in Between
Development of such a data-driven digital twin is in many cases faster. Sometimes it is not good enough for the questions to be answered, but sometimes it is the only choice, as the underlying system is not well enough understood to enable building a full physical model. A practical example is descriptions of social systems, like behavioral models of citizens in a city — measurable data is too sparse to sustain a full model, and the inherent behavior is surely not understood!
Here, a descriptive, data-driven model is now an approach of choice. Examples are natural language processing or optical character recognition — here, the data-driven solution vastly outperforms the purely analytical systems approach. What is often done is a hybrid approach when building digital twins: You combine the best of both worlds, and you get a great compromise that combines the benefits!
The more knowledge you put into a data-driven model, the more it gets into a full representation of all effects in the system. That also means that complexity increases and some of the benefits vanish. Based on experience, the key question is to clearly specify the challenge (or business problem!) you are trying to solve. Then, get a feeling of what is really required in terms of precision and accuracy. Often you will find yourself in a situation where the amount of data available is not sufficient to answer the question directly, but with domain knowledge, feature engineering, and the right assumptions, you can often get a sufficiently accurate solution. When using purely data-driven models for safety critical applications, you have to be careful as well. However, for many situations this is less of a concern.
Another approach frequently taken is adapting an existing model by “fitting of parameters.” This is by the something you likely have done in spreadsheet tools before: when doing a simple linear regression Behind the scenes it means determining slope and intersection based on a given set of data by applying least squares of error minimization — a method that has been available since the early 1800s (cf. Gauss & Legendre). Back in the day manual calculation of this was tedious, and so before the arrival of computers, it was very limited. More advanced techniques like the statistical “maximum likelihood” would surely not be possible within reasonable times. In the same way, one can adapt an existing engineering model to account for inaccuracies of a model or incorporate behaviors where observation and reality differ.
So, in order to make the twin more like reality, we use data from the real system to adapt “parameters” based on the observations. This has been a standard practice for decades, but with traditional tools and methods, it has quite some limitations. The amount of data is limited, and you can surely not fit several thousand sensors into a model within the foreseeable time. Here again data-driven digital twins are an option we can employ—- especially when there is no standard model we can fit the data to. When it comes to building twins of complex real-world business processes, like a supply chain or legal contract evaluation, it is a purely descriptive and often arbitrary model that is the only one to provide insights.
After All the Theory, Time for Some Real-World Examples
No matter how you scope your digital twin, whether it is a full system representation as in the original NASA sense, or a purpose-built data-driven one, what matters is the value that you can leverage: Your digital twin can help you understand an underlying process and give you the opportunity to optimize it. Especially with data-driven methods as available today, and enabled by Dataiku, this representation can save you time and effort or can yield a solution for the first time. Similarly to the “3-V’s” that Doug Laney used in 2001 to describe big data, let’s build on that for digital twins in 2022, and what has changed in the past years:
- Volume - The amount of data that can be used successfully are unprecedented
- Variety - The types of data we can use and the resulting processes / things we can describe
- Velocity - The iteration cycles of fitting parameters (=training) and time of development is
And we add:
- Volatility - Unlikely rigid models, our data-driven models have the chance to adapt to changes and learn from it
- Vastness - Democratizing access to methods, data & platform is significantly removing friction and makes it happen
In the forthcoming blog posts of this series, we'll dig into some real-world examples for our customers. They vastly vary in scope, amounts of data, and the methods used, but one thing is sure: They are all digital twins and help bring business to the next level.