




{kind=link}
Federated Learning (FL) can enable privacy-preserving distributed computation across several clients. It is used to federate knowledge from parties that do not wish to share their data. For example, project MELLODDY has applied it to drug discovery by federating models from several private laboratories to share the learning effort.
But FL faces the common challenge of dealing with large, unlabeled datasets. How can we optimize labeling under an FL setting?
This is precisely the goal of Federated Active Learning (FAL), which lets each client perform Active Learning (AL) using a federated model. Performing it locally, at the client level, is easy since sampling strategies usually rely on a mix of uncertainty estimation and diversity, which can be estimated with the data at hand. But this approach lacks a global view on all the data, as nothing prevents two clients from labeling the same sample in this setting!
Performing AL at server-level is trickier because imposing diversity usually requires to have a measure of similarity between samples. Recent advances made it possible by bringing unsupervised methods such as K-Means at the server level. Could it be useful to design FAL strategies that leverage all clients’ data?
Federated Learning and Active Learning: 2 Iterative Processes
FL is an iterative process that alternates between the independent training of each client and the federation of the model.
AL is also an iterative process that rotates between training a model and using it to select samples and labeling performed by an oracle. Both procedures can be intertwined in a FAL setting.
Federated Active Learning: An Efficient Annotation Strategy for Federated Learning
Ahn et al. have proposed two strategies for AL in a federated setting [Ahn2022]. The first one, client-level Separated Active Learning (S-AL), is a baseline where AL is performed separately by each client prior to federation.
 Pseudo-code for Ahn’s client-level separated active learning
Pseudo-code for Ahn’s client-level separated active learning
F-AL proposed by Ahn et al. blends the two iterative processes by performing AL at each step of the federated learning cycle using the federated model. It is the green pseudo-code in the algorithm below. One can see that F-AL happens after federation of the model, but sample selection still occurs independently for each client.

Pseudo-code for Ahn’s. federated active learning
We propose two other ways of performing FAL, one that builds upon S-AL and one that improves upon F-AL.
FAL-Local. Just like S-AL, FAL-Local uses the model local to each client to perform AL. However, it uses the federated model fine-tuned on local client data at each iteration. We expect it to have better performances than S-AL since it leverages the model common to all data, but also better than F-AL since the fine-tuning at the client level is supposed to make the model better on the local test set.

Pseudo-code for Local F-AL
FAL-Global. Modern AL techniques impose diversity in the batch of selected samples to explore the sample space better. This is usually done using clustering techniques in various ways. IWKMeans performs a clustering with batch_size clusters and take the samples closest to the centroid for example. This is not trivial to perform in a federated setting since the distance matrix between all samples is unknown.
However, it is possible to perform this step at the server level using the recently released federated K-Means [Kumar2020]. This may be a decisive advantage since our sampler will be aware of the whole manifold and may therefore avoid selecting similar samples. We call this method FAL-Global and is the pink pseudo-code in the algorithm below.

Pseudo-code for Global F-AL
Why Global Diversity Is Important
The motivation for global diversity comes from a simple situation: If two clients hold the same (or very similar) data, client-level AL strategies can select the same (or very similar) samples for two different clients, wasting half of the budget on unnecessary labeling.
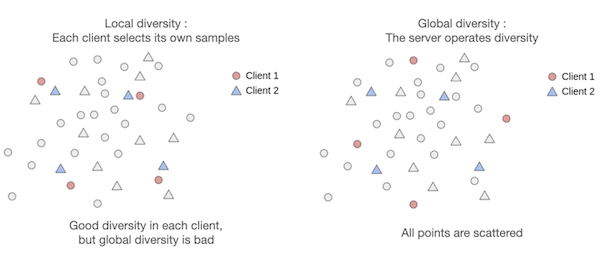
A toy example on how similar data can lead to labelling budget waste
Establishing global diversity requires adapting AL strategies to account for the budget available per client; we call this variant FAL-Global with quota or FAL-Global for short.
If the labeling budget is common to all clients, we can lift this constraint for even better performance. We call this variant FAL-Global without quota. The drawback of this variant is that it could select all samples from one client, which might be unfair since this client is not benefiting from the other’s data.
In a study performed on MNIST, we observed that imposing the quota does not affect IWKMeans, the most performant sampler, while it worsens the performance of BADGE.
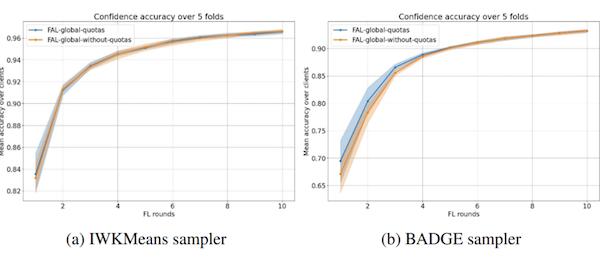
Comparing FAL-Local and FAL-Global
As mentioned above, we expect global diversity to be particularly valuable when data across clients is similar. But, in practice, we have no guarantee that the split is homogeneous among clients. To simulate potential harmful data split among clients, we have tested the following settings:
- Homogeneous: A stratified shuffle split among clients.
- K-Means: A setting where 20% of the data is split homogeneously to ensure the presence of a common support across clients, and the remaining 80% is split among clients using a K-Means clustering.
- Task-specific: On CIFAR-10, we use corrupted data for one client.
The FL is run with 20 clients, and the AL procedure is made to simulate labeling of 1% of the data over 10 iterations.
MNIST Homogeneous vs. K-Means
For this problem, we have explored a wide variety of settings including two configurations that aim at providing upper and lower bounds to our problem:
- Centralized corresponds to a regular learning without FL. It is supposed to be an upper bound on the performance.
- Client alone is the average performance of all clients when no FL is performed. This is considered the top performance a client can get by himself, so a lower bound for our problem.
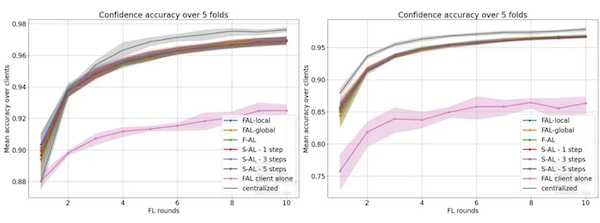
Accuracy of the best sampler IWKMeans. Left: Homogeneous, Right: K-Means
In both data splits, we observe no significant difference between our FL settings. Overall, performance is worse with the K-Means split because this is an inherently more complex problem.
A larger study on this dataset reveals that using an AL sampler improves performance compared to random, but changing the nature of sampler, the FAL strategy, or the data split has no significant impact.
CIFAR-10 Corrupted
CIFAR-10 corrupted is a setting where the data of one client among the 20 is corrupted by strong shot noise. In this setting, we expect each method to be favored in its own way:
- FAL-Local should be favored by the local fine-tuning of each model: Since one client is corrupted, each sane client can fine-tune on a sane basis before performing uncertainty estimation.
- FAL-Global should be less impacted by corruption.
There is no way to know which effect will be the best one; only practice!
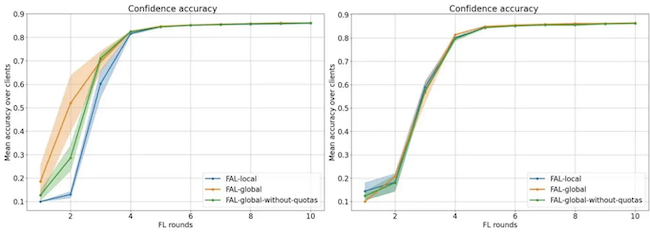
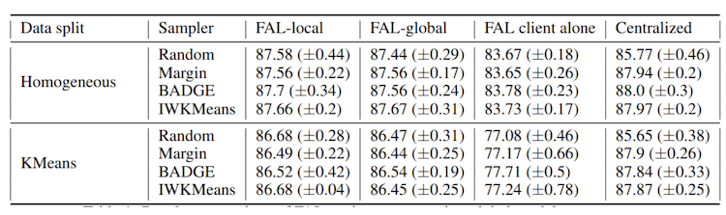
Accuracy on CIFAR corrupted. Left: Margin, Right: IWKMeans
The results on this task are pretty surprising. All settings have similar performances with IWKMeans but FAL-Global with margin sampling outperforms clearly the others.
The difference between FAL-Global with and without quota is due to noisy samples, a phenomenon already identified in our previous work [Abraham2021]. In fact, without quotas, Margin focuses on corrupted samples, because the model is uncertain about them, but gets little information from them. As IWKMeans was designed to deal with noisy samples, we still do not understand why it is less performant than Margin in this context. Further study is required to fully understand these results!
Conclusion
Unfortunately, in most cases, FAL-Global does not bring any improvement, as observed with the federated tasks simulated on MNIST. On CIFAR-10 corrupted though, FAL-Global used with Margin sampling significantly outperforms the other methods. Understanding this phenomenon may open the path to improving Federated Active Learning in cases where one client has data of lesser quality than the others.
References
[Kumar2020] Kumar, H. H., Karthik, V. R., & Nair, M. K. (2020, November). Federated k-means clustering: A novel edge AI based approach for privacy preservation. In 2020 IEEE International Conference on Cloud Computing in Emerging Markets (CCEM) (pp. 52–56). IEEE.
[Abraham2021] Abraham, A., & Dreyfus-Schmidt, L. (2021). Sample Noise Impact on Active Learning. 5th International Workshop on Interactive Adaptive Learning (IAL2021), co-Located With ECML PKDD 2021.
[Ahn2022] Ahn, J. H., Kim, K., Koh, J., & Li, Q. (2022). Federated Active Learning (F-AL): an Efficient Annotation Strategy for Federated Learning. arXiv preprint arXiv:2202.00195.