




{kind=link}
There are many libraries out there to help people build deep learning Applications, but one API stands out from the rest when it comes to using state-of-the-art models from the latest architectures with minimal code: Google’s Tensor2Tensor. I used this library to make Translators using advanced new neural net architectures, specifically the Transformer, with hardly any code.
 I can keep up with my French team and clients using T2T even though I don't speak French.
I can keep up with my French team and clients using T2T even though I don't speak French.
New neural network architectures and novel AI research papers come out every week from professors at universities, researchers at Google and other big tech firms, or even just developers with a strong interest in deep learning.
Unfortunately for individuals who don't have a Ph.D. or robust fluency in back-propagation, linear algebra, or computational math, implementing these new deep learning techniques with no high-level API (like Keras) can be challenging and time-consuming.
Thankfully, the Google Brain team recognizes these widespread problems in the AI community and subsequently created an open source library to help address these issues. Quoted from it’s Github Repo:
Tensor2Tensor, or T2T for short, is a library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research. T2T is actively used and maintained by researchers and engineers within the Google Brain team and a community of users.
Deep Learning and Tensor2Tensor
Although deep learning isn’t always the silver bullet people hope for in the data science world, it is a very useful tool for natural language processing (NLP) task. For example, the use of word embeddings has revolutionized the effectiveness of language understanding techniques.
I wanted to make an offline French to English translator for my team and our clients, using the best current techniques, which at the time was the Transformer architecture. Instead of coding and training this neural network from scratch, T2T provides a framework for quick and easy training and model production.
If you’re interested in learning more about the Transformer, how it’s Attention Layers can overcome pitfalls of RNNs, and how it enables better natural language understanding you can watch this talk:
Tensor2Tensor API Overview
The T2T library was designed to be used with a shell script, but you can easily wrap it for Python use. The API is multi-modular, which means that any of the built-in models can be used with any type of data (text, image, audio, etc). However, the authors of the API do supply suggested datasets and models for specific tasks like translation, text summarization, speech recognition, and much more.
There may be times when you want to use one of Tensor2Tensor’s precoded models, and apply it to your own datasets and hyper-parameter combinations. Or you might want to use their simple framework for experimenting with your own model architectures. It is possible to do this easily by defining some new subclasses, which I’ll elaborate on later.
The usage of the library is all documented and outlined well in their repo, but we’ll walk through the core parts of their API to give you an idea of how you can start your first project with T2T.
Define Your Tensor2Tensor Problem/Task
The first thing you’ll want to do with Tensor2Tensor (T2T) is to identify what you’re going to use it for. T2T has a concept called a problem. This defines the task you’re solving, the dataset that you’re using, and, if applicable, the vocabulary. This is independent of the model architecture and the training hyper-parameters.
You will need to pick one of the many problems available in T2T first before anything else. You can view all problems already built into the API with the command line by calling t2t-datagen, or in Python with:
The naming schemes for T2T follow the form [task-family]_[task]_[specifics]. So if you wanted to make an English to French Translator, with a 32k vocabulary size using the WMT translation dataset, you would choose the problem name: translate_enfr_wmt32k. For some of the pre-existing T2T models, you can reverse the input and output by adding the chars_rev to the end of the problem name. To train a model for French to English translation the problem name would be translate_enfr_wmt32k_rev. Examples of other problems built into Tensor2Tensor include:
summarize_cnn_dailymail32- Text Summarization Neural Net using the CNN Daily Mail dataset with a 32k vocabulary sizeimg2img_celeba- Image to Image translation with superresolution from 8x8 to 32x32sentiment_imdbSentiment analysis model suing the IMBD dataset
Generating Training Data
After selecting and naming the problem you want to solve, you’ll need to choose the right data for it. Thankfully Tensor2Tensor has scripts to automatically download and prepare the data for training if you’re using a prebuilt problem.
You’ll first need to choose a directory to store the unprocessed data that T2T will download for you. This is known as the tmp_dir. A lot of the same problems download the same data, so it may be possible to reuse this directory for multiple problems in T2T, especially if they’re within the same task/problem family.
Before generating the final training data, you’ll need to also decide on the directory to store the pre-processed data. This is known as the data_dir in Tensor2Tensor. Again, you can reuse directories when appropriate.
The tmp_dir can be thought of where the zip files from the internet get stored, and the data_dir is where after reading the data from the tmp_dir it is properly preprocessed for the specific T2T problem. For example, if doing NLP, during preprocessing T2T will encode each word with a digit, split train plus test sets, create a vocabulary, and more.
If you want to use your own dataset and train a model with one of T2T’s precoded neural nets, you’ll need to make a new problem subclass.
Once you have initialized these directories you can generate data with the command line like below:
t2t-datagen \
--data_dir=$DATA_DIR \
--tmp_dir=$TMP_DIR \
--problem=$PROBLEM
Or in Python with:
Model Choice and Hyper-Parameters
You can see all available models by calling t2t-trainer in the command line, or in Python with:
For instance, the Transformer model works best for translation.
Of course, you can always customize the multiple hyper-parameter sets in the model. For example at the bottom of the Transformer python file, you can see all the hyper-parameters that are adjustable for training (see photo below). But it’s often best to start off with the base parameter sets, and then adjust as needed.
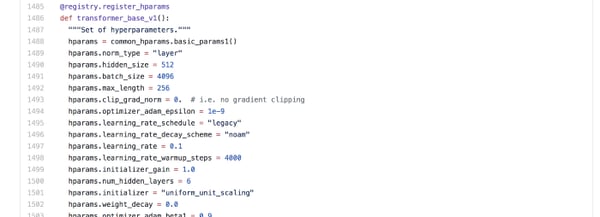
It’s important to note that the hparams used for Tensor2Tensor define training parameters along with model parameters. This means you can very easily adjust the size of your network along with things like the batch size, learning rate, type of optimizer, and more when testing new models.
Training Your State of the Art Neural Net
Now, you are ready to train your neural network with only a few lines of code.
Using the command line all you’ll need to do is execute the following script by setting the respective variables:
t2t-trainer \
--data_dir=$DATA_DIR \
--problem=$PROBLEM \
--model=$MODEL \
--hparams_set=$HPARAMS \
--output_dir=$TRAIN_DIR
The output_dir parameter is where the model file checkpoints will get stored for this model run so that you can pick up training where you previously left, by preloading the model files in that directory.
You have the ability to change any of the hyper-parameters by adding an extra flag to the shell script above.
To set up the training in Python, it takes a bit more effort, but it is feasible.
Using a Reversed Engineered Notebook to Build a Translator
First, you have to set the needed T2T variables, the directory, the location of the preprocessed data, and the model file storage location.
Next, you need to initialize the hparam object and reset some of its variables. If you have limited VRAM, you will need to reduce the batch size—say, from 4096 to 1024—so that it can fit in memory while training. You will subsequently need to adjust the learning rate and learning rate warm-up steps to optimize the model converge for the modified batch size. Next, you can play around with the hidden layers to determine if that will help improve model performance for your specific case.
To start training a model, you’ll then need to initialize the TensorFlow run_config and experiment objects. Finally, call tensorflow_exp_fn.train_and_evaluate()to do the training.
Tracking Model Training and Performance
Now that your model‘s training has started, you can enjoy the evolution of the loss and accuracy metrics:
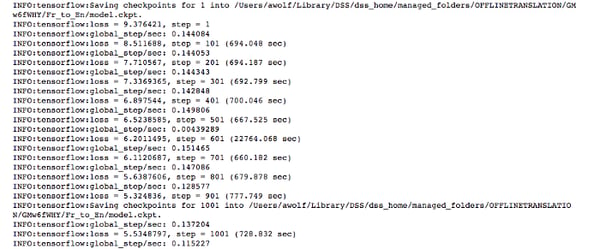
The parameter train_steps is set when you initialize the TensorFlow Experiment object. This is the number of steps to train before stopping. You control how often to perform the evaluation with the save_checkpoints_steps(defaults to 1000). This is set as an optional hypermeter when you initialize the run_config object.
While Tensor2Tensor is fully functioning with CPUs, there are also a lot of options for GPUs and distributed training too; like which to use, how much memory to limit in each GPU, and more. If you’re interested in learning how to integrate GPUs for training T2T model’s you can read more about in this link within their documentation.
Tensorboard Integration
To activate Tensorboard, you’ll first need to go to the command line and enter the command- tensorboard — logdir /{path_to_train_dir}. To get direct access to the Tensorboard binary, you may first want to activate the python environment containing TensorFlow in your bash shell. See how to do it here.
Once activated, you’ll be able to track model performance in real-time at http://{host_ip}:6006 /. Tensorboard can be used to compare train and eval metrics over epochs, see the TensorFlow model graph, and much more.
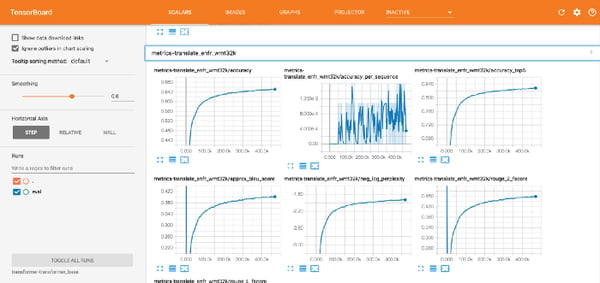
The accuracy metric most commonly used for this task is the BLEU score. This model achieved a BLEU score to around 28 for French to English translation, which is considered state of the art. One of my coworkers also made translators for the German language using Tensor2Tensor. This ended up being useful for travel to Munich in October 2018 :)
Using Your Tensor2Tensor Model for Scoring
To score with your newly trained model, you can use the t2t-decoder binary:
t2t-decoder \
--data_dir=$DATA_DIR \
--problem=$PROBLEM \
--model=$MODEL \
--hparams_set=$HPARAMS \
--output_dir=$TRAIN_DIR \
--decode_hparams="beam_size=$BEAM_SIZE,alpha=$ALPHA" \
--decode_from_file=$DECODE_FILE \
--decode_to_file=translation.en
However, this can only read a text file, and outputs results to a text file, which is not always what you might need. So I’ve ported that for easier model access in Python. Check out the documented code below to see how it’s done.
You may have seen that there are two functions in the code above named encode() and decode(). These are for taking things like regular text data and encoding it to the proper format for the model. Similarly for decoding the model output in the respective output format.
This means that they can take in a number of input sequences up the batch size (1024) and translate long passages a lot quicker, instead of having to make 1024 translate calls to the model to translate 1024 sentences.
Getting My Tensor2Tensor Model Into Production
One of the main reasons I wanted to make a French translator was because I work for a French company. Many people speak French in the team chat. Unfortunately for me, I have no idea what they’re saying.
I ended up creating REST API endpoints with Dataiku to perform translations with the TensorFlow models I made. I connected the REST endpoints to our company chat on Hipchat using a chatbot API called Errbot.
Now each time my coworker says something, I can easily translate what they said.

Concluding Remarks
Tensor2Tensor is a fabulous API, and it’s great that the Google brain team decided to open source this library. It is very easy to use and saves people a lot of time/work to create state of the art neural nets. They are constantly improving their API and adding new architectures.
Next time, I’ll probably build a text summarization model, and utilize the Universal Transformer which is a newer version of the architecture I used to train my translator. If you’d like a more complete demo, I’ve posted the project publicly on my GitHub profile for those of you who would like to use it. It’s documented for translation, but can be used for any T2T model/problem.