




{kind=link}
The process of converting a trained machine learning (ML) model into actual large-scale business and operational impact (known as operationalization) is one that can only happen once model deployment takes place. It means bridging the massive gap between the exploratory work of designing ML models and the industrial effort (not to mention precision) required for model deployment within production systems and processes. The process includes, but is not limited to: testing, IT performance tuning, setting up a data monitoring strategy, and monitoring operations.
For example, a recommendation engine on a website, a fraud detection system for customers, or a real-time churn prediction model that are at the heart of a company’s operations cannot just be APIs exposed from a data scientist’s notebook — they require full operationalization after their initial design (and hinge on model deployment going smoothly).
An ML model is considered in production once it’s been successfully deployed and being used by end users to realize business value. This article will shed more light on what exactly model deployment means and how Dataiku’s end-to-end platform makes the model deployment process seamless.
Why Is Model Deployment So Important (and So Hard)?
Let’s imagine you’ve done everything leading up to model deployment. You’ve defined your business goal, collected your data, cleaned your data, and explored and deeply analyzed it (which usually involves some data visualizations). During the ML part of the project, teams build, train, and test several models to determine which one is the most efficient and likely to produce accurate predictions.
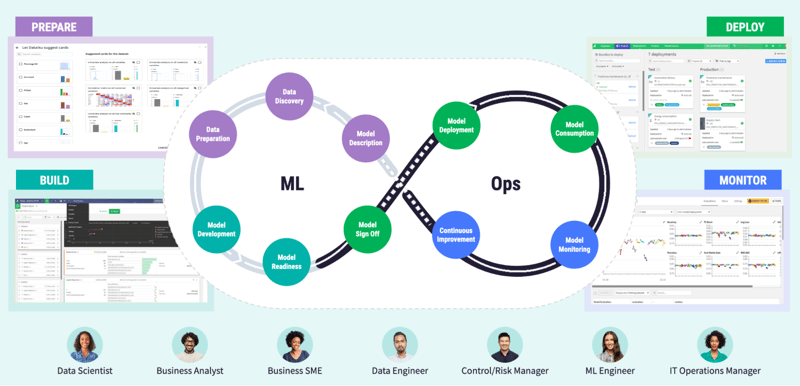
When you’ve tested, iterated, tested and iterated some more, and arrived at a model that is fit for production, you might think this is where the journey ends. But it’s not — model deployment is a lot more complicated than that. In order to drive real business value from the project, the model can’t just sit on the shelf, it needs to be deployed for use across the organization.
When it comes to model deployment, a challenge organizations commonly face is how to bridge the gap between prototyping and production environments in a timely manner. As the infrastructures and technical requirements between the two are not identical and the people working on them have a different set of concerns and skill sets, these environments often diverge in meaningful ways (accepted programming languages, code library versions, individual vs. system accounts, sandbox vs. production databases, etc.).
This disconnect means putting a model in production sometimes requires the production team (usually data engineers in IT) to recode the entire pipeline in another language, with different dependencies … a cumbersome process that can take months or even years. In many cases, this is the phase where a project stalls out and often dies, rendering all the work leading up to this point wasted.
Another issue data experts have when putting their models into production is recomputing. Because they’re operating on data (which isn’t frozen in time and is constantly refreshed and enriched), results from data need to be frequently updated as well. So, if data scientists want to have valuable and current data-generated insights, they need to regularly rebuild datasets, retrain models, and so on.
Once a model is developed and actually deployed into a production environment, the challenge then shifts to regularly monitoring and refreshing it to ensure it continues to perform well as conditions or data change (read: MLOps). It is a significant time burden for data teams to have to perform period spot checks when monitoring dozens, hundreds, or even thousands of live models. We’ll dive deeper into how Dataiku streamlines MLOps in the next section.
Ease Model Deployment With Dataiku
Packaging, release, and operationalization of analytics and AI projects can be complex, time consuming, and error prone. Without a way to do it consistently, costs are tied up across person hours and revenue lost for the amount of time the model is not deployed into a production environment and able to drive tangible cost savings for the business. Further, if the model in production is critical, downtime can be really costly (both operational and reputational risk at stake), so strategies for fallback and reversion to a prior model are very important.
When it comes to project and model deployment in Dataiku, the deployer acts as a central place where operators can manage versions of Dataiku projects and API deployments across their individual lifecycles. Teams can manage code environment and infrastructure dependencies for both batch and real-time scoring. They can also deploy bundles and API services across dev, test, and prod environments for a robust approach to updates. For a quick, two-minute overview of the project deployer, check out the video below.
Dataiku project deployer in action
Finally, in order for a model to remain useful and accurate once it has been deployed, it needs to be constantly reevaluated, retrained, and inclusive of new features. That’s where MLOps comes in. Once a project is up and running in production, Dataiku monitors the pipeline to ensure all processes execute as planned and alerts operators if there are issues.
To give ML operators more context for model deployment decisions, Dataiku has a model evaluation store that automatically captures historical performance snapshots all in one place. With pre-built charts to visualize metrics over time and automated drift analyses to investigate changes to data or prediction patterns, it’s easier than ever for operators to spot emerging trends and assess model health. Because ML models reflect the conditions under which they’re trained, all models begin to decay the moment they’re live — it’s just a matter of when and how much.
At the end of the day, model deployment (and eventually operationalization) can be immensely difficult for enterprises to execute on because it requires tight coordination and collaboration at both the organizational level and the system architecture and deployment/IT levels as well. In order to excel with data analytics, you need a robust platform for data access, exploration, and visualization. But you won't maximize the value from your data if that platform isn't the same one where you can also do ML modeling and deployment into production. Having this all under one roof is critical for a thriving deployment and post-deployment environment.