




{kind=link}
If you’re running data science pipelines and machine learning model workflows to get real business value, that probably means you need to process lots and lots of data. To do this in a scalable way and to handle complex computation steps across a large amount of data (without breaking the bank), Kubernetes is becoming an increasingly popular choice for scheduling Spark jobs, compared to YARN.

Apache Spark is a framework that can quickly perform processing tasks on very large datasets, and Kubernetes is a portable, extensible, open-source platform for managing and orchestrating the execution of containerized workloads and services across a cluster of multiple machines. So what makes the two a winning combination? This blog post will unpack the top reasons (for those that want a much deeper dive and walk-through of the technology, check out the on-demand webinar How to Process Tons of Data for Cheap with Spark on Kubernetes).
Check out this helpful, 10-minute video that demystifies Spark on Kubernetes (and how to utilize it within Dataiku).
Simpler Administration
Kubernetes allows for the unification of infrastructure management under a single type of cluster for multiple workload types. You can run Spark, of course, but you can also run Python or R code, notebooks ,and even webapps. In the traditional Spark-on-YARN world, you need to have a dedicated Hadoop cluster for your Spark processing and something else for Python, R, etc.
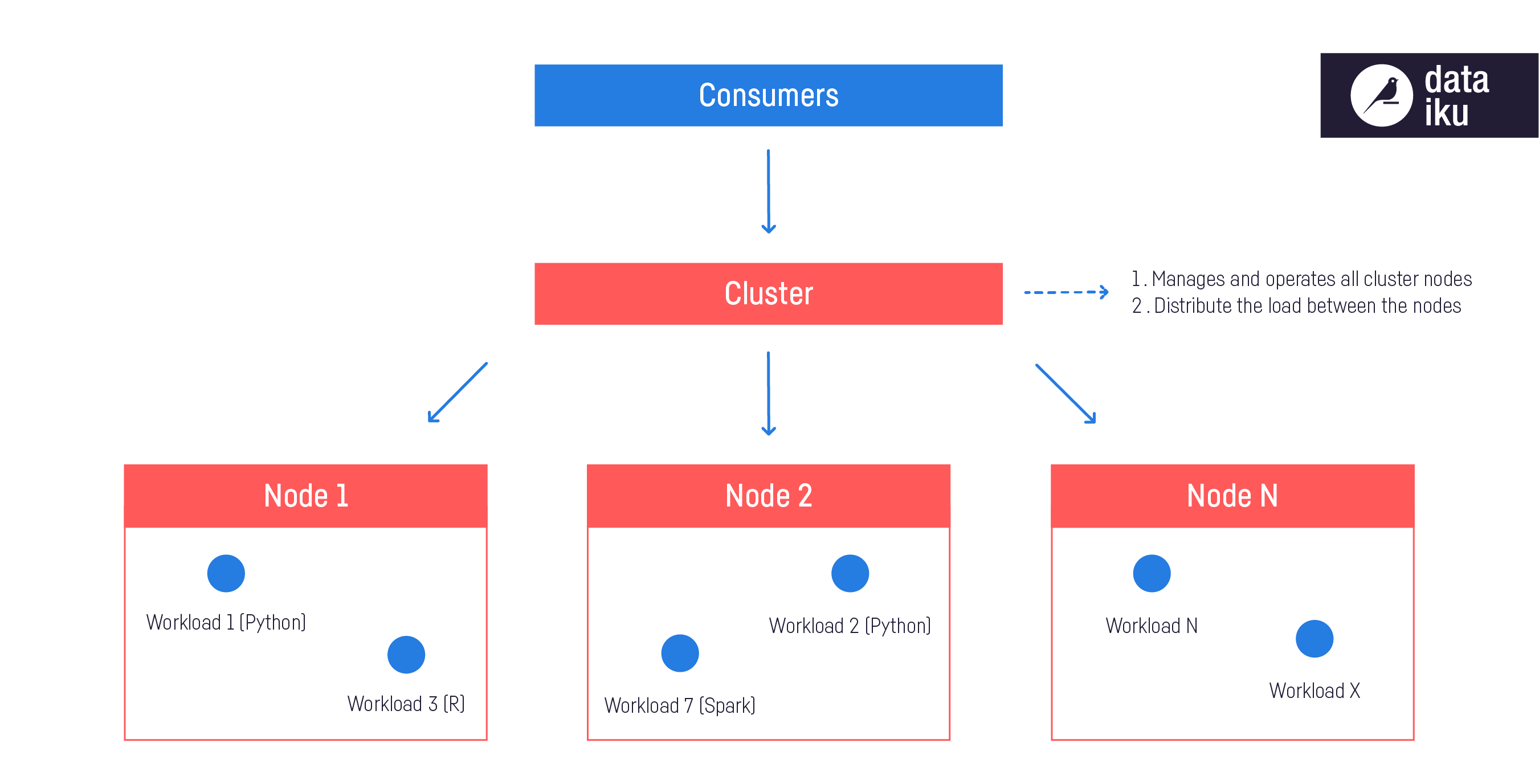
For organizations that have both Hadoop and Kubernetes clusters, running Spark on Kubernetes would mean that there is only one cluster to manage, which is obviously simpler. But even for those currently using only Hadoop, deploying Spark on Kubernetes is simpler because Kubernetes brings:
- Isolation, meaning that you can prevent workloads running in the cluster from interfering with each other because they will remain in their own "namespaces.” Security — authentication for access to the cluster itself — is handled differently than with a Hadoop cluster (it's not easier or harder; just different).
- Better resource management, as the scheduler takes care of picking which node(s) to deploy the workloads on in combination with the fact that in the cloud, scaling a cluster up/down is quick and easy because it's just a matter of adding or removing VMs to the cluster, and the managed Kubernetes offerings have helpers for that.
Easier Dependency Management
Managing dependencies in Hadoop is time-consuming: packages have to exist on all nodes in a cluster, which makes isolation (i.e., making different versions of the same software — like TensorFlow 1.5 and TensorFlow 2.0 — coexist on the same node) difficult and updating environments challenging.
This can, of course, be somewhat mitigated by submitting zip files with packages and building lots of virtual environments, which probably works fine for a small amount of applications. But when data science teams — and data projects — start to scale, this system becomes very challenging.
Spark on Kubernetes, and specifically Docker, makes this whole process easier. Kubernetes orchestrates Docker containers, which are used as placeholders for compute operations. These containers package the code required to execute your workload, but also all the dependencies needed to run that code, removing the hassle of maintaining a common dependency for all workloads running on a common infrastructure.
More Flexible Deployment
If you’re doing Enterprise AI and want to start moving data storage to the cloud (or have already started doing so), the idea of vendor lock-in can be very scary. That’s why today, more and more businesses are taking a cloud-agnostic approach. Running Spark on Kubernetes means building once and deploying anywhere, which makes a cloud-agnostic approach scalable.
[Bonus] It's Cheaper
The nice thing with Kubernetes (not just for Spark, but for everything else) is that all major cloud vendors offer managed services to provide Kubernetes clusters that are built on top of what makes the cloud nice — i.e., a very flexible and elastic infrastructure that can be created, destroyed, and scaled easily to match workload requirements.
This elasticity is also reflected in the cloud pricing model, where you only pay for what you use and where you can adjust the machine number and type according to your workload requirements... and your budget.
In addition, running Spark on Kubernetes also saves time. Data scientist and architect time is valuable, and bringing more productivity to those people and departments will allow for even more savings.
[Extra Bonus!] It's Even Easier With Dataiku

Though running Spark on Kubernetes is simpler in terms of administration, more flexible, and can even be cheaper, that doesn’t mean it’s foolproof to set up or use. With Dataiku, data scientists and architects can have all the benefits of using these technologies but with all of the complexity abstracted away. Dataiku enables non-admin users to quickly spin up Kubernetes clusters (on AWS, Azure, or GCP) for optimized execution of Spark or in-memory jobs to scale quickly and efficiently with on-demand elastic resources.