




{kind=link}
Have a question about AutoML and Dataiku? We have you covered. Thanks to our two-part webinar series about AutoML (including both a higher-level look at the value of AutoML and an in-depth, end-to-end demo of the AutoML features in Dataiku), we have a list of questions — and answers! — to share.
But first, a quick step back for an overview of Dataiku and AutoML. Dataiku is the platform democratizing access to data and enabling enterprises to build their own path to AI. To make this a reality, Dataiku provides one simple UI for data wrangling, mining, visualization, machine learning, and deployment based on a collaborative and team-based user interface accessible to anyone on a data team, from data scientist to beginner analyst.
Since the early days of the product (the company was founded in 2013), Dataiku has proposed a visual machine learning suite — also known as AutoML — that guides the user through all of the machine learning steps: train-test split, features handling, metrics to optimize, and different templates of preset algorithms.
The interface offers a one-button option, simply called "Train" — but of course, it's still up to the user to tune those parameters and select the best possible settings based on their experience. This will automatically infer the feature handling, preselect a collection of algorithms, and return the best performing one.
Does Dataiku have capabilities for NLP preprocessing and NLP models?
Yes, while we didn’t get to show you everything that AutoML can do because we wanted to show you how to use it properly instead. In the design section under features handling, you can choose text, and then when you choose text, know that it has to be a text column. You have several ways to enter your text column such as TF/IDF vectorization; tokenize and hash which is the default; tokenize, hash, and apply SVD; counts vectorization, and customs preprocessing.
Dataiku supports text data if you have text in some columns. For image-like data, you will have to go to the deep learning workbench, which looks similar to the AutoML, so the UI is the same. You will have the features handling, but it uses Keras, so you will have to code the architecture of your neural network. Everything around this piece of code with the architecture of your network UI will be almost exactly as it is in the AutoML tool.
Are there any versioning models of the model created in the Dataiku AutoML demo?
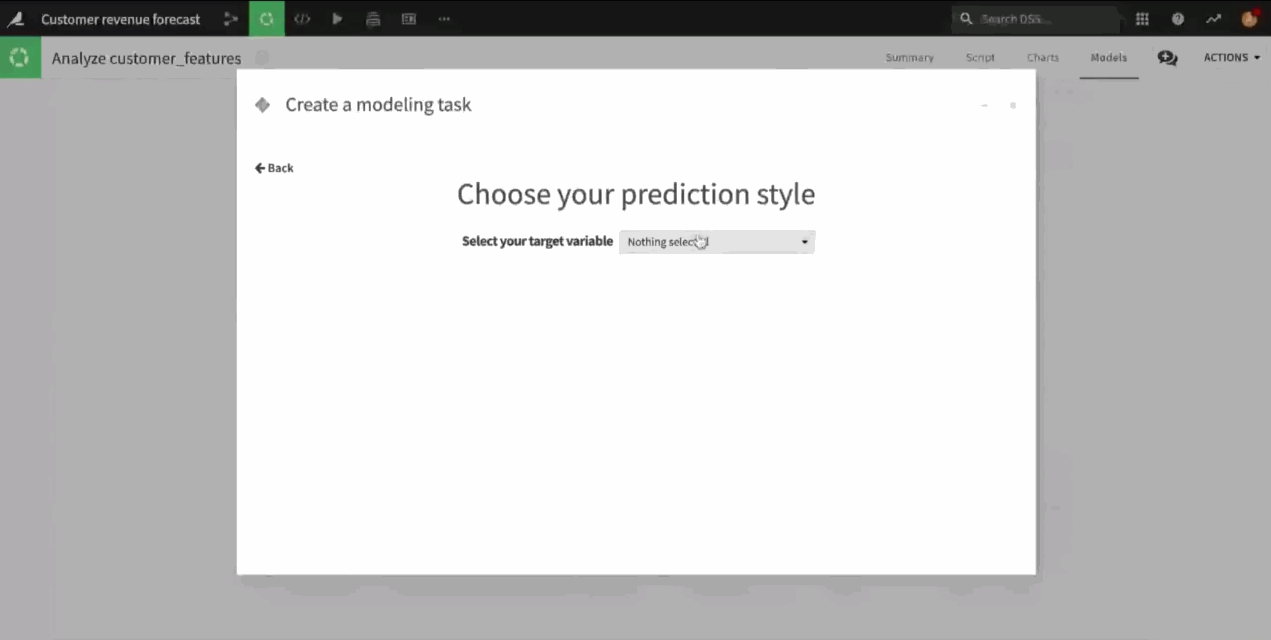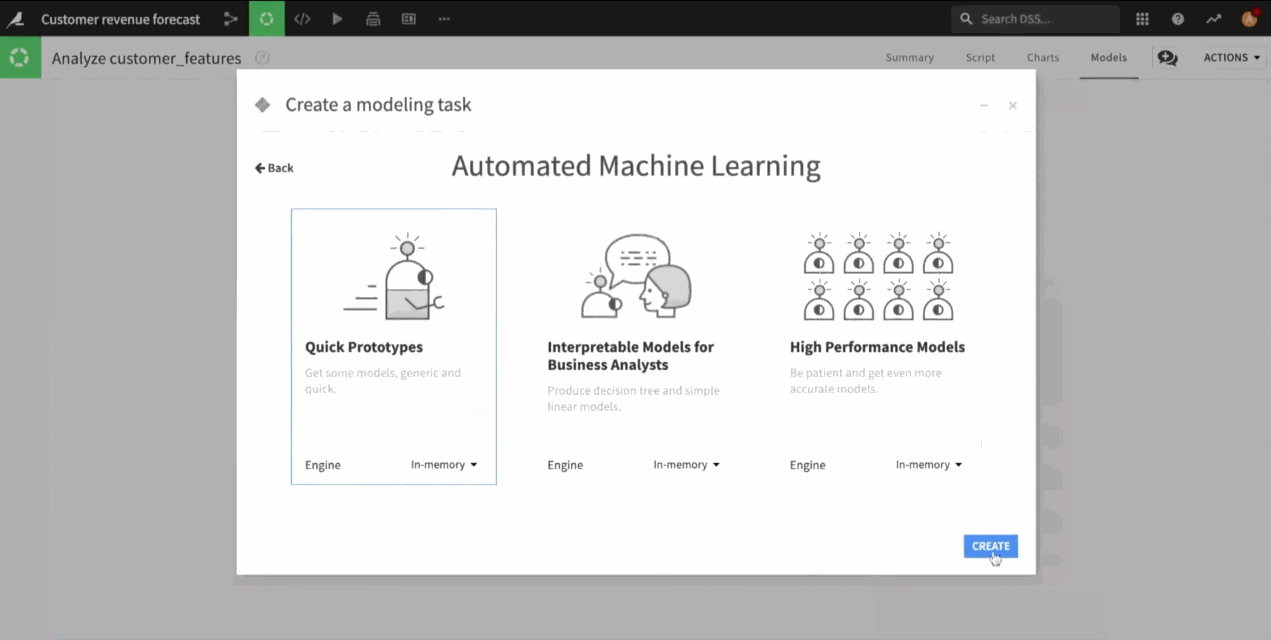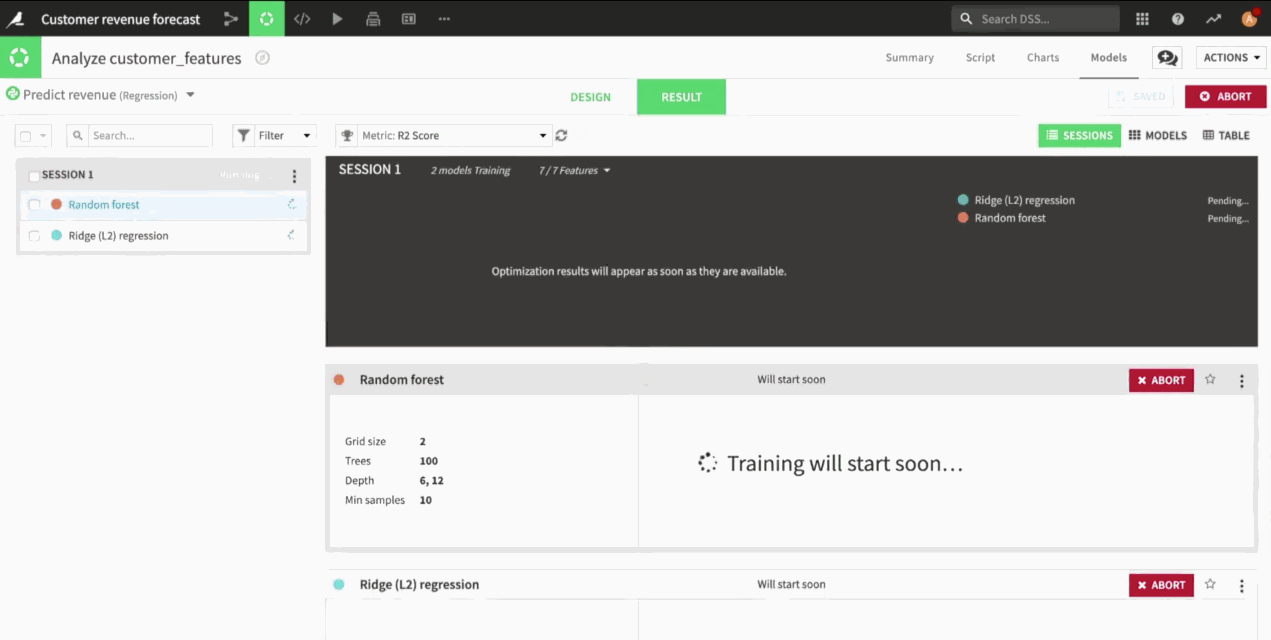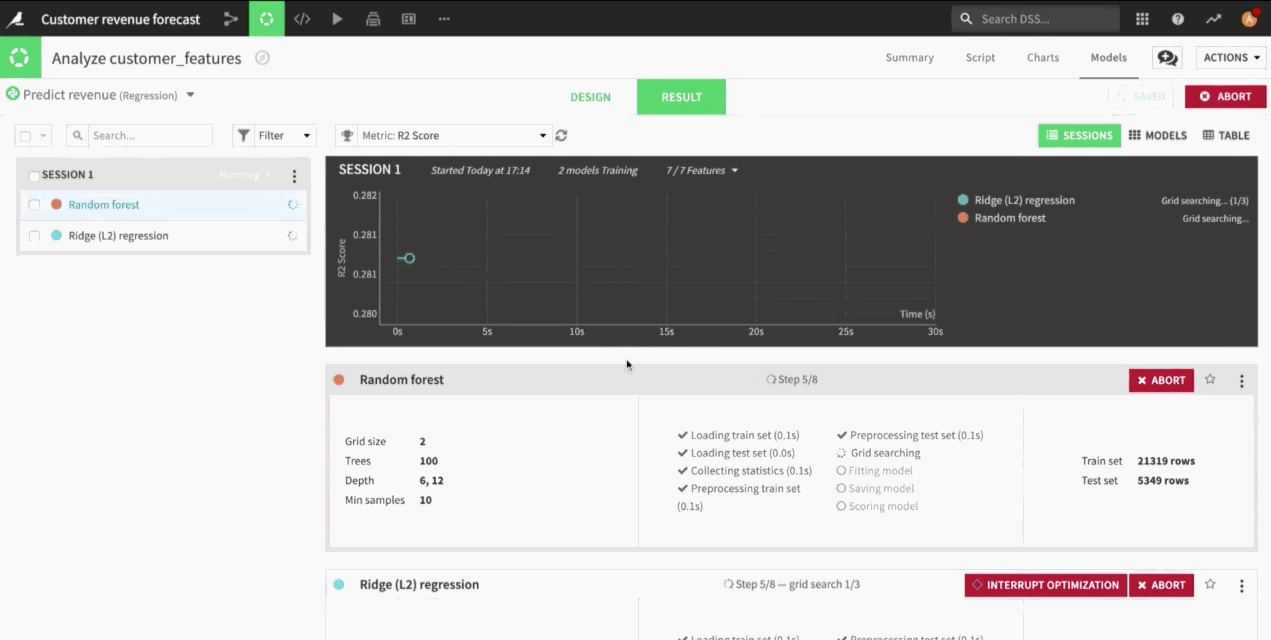
Yes, indeed there is. You can see that in the results, I ran three sessions during our experimentation. The first one was with the basic feature engineering. The second one was the enhanced feature engineering for the linear model. The third one was with the performance template. I can still have a look at all of the results that I have found previously.
How does Dataiku AutoML handle the addition of more data?
If you add more data, it will automatically be taken into account in the AutoML when you click on “train” again. Note that you can specify in the design that you are only working on a sample of the data. In the train/test set from this example, there was sampling. Either you sample maybe the first 10,000 lines or you can do random sampling so that if your dataset is very large, you can still do the training in memory. If you add new features, they can be automatically detected and recognized in the features handling.
How does Dataiku AutoML help prevent overfitting of data?
On one side, to find the best hyperparameters, you choose a first level of cross validation, so either K-fold or simple train/validation split that is made especially to avoid overfitting. If you select a train/validation split, it means that you will keep, in this case, 20% of the data for the validation that is used to find the hyperparameters.
Then, when you have chosen the best hyperparameters, there is a last evaluation on the test dataset, or sometimes it’s called a holdout dataset. Once again, you can use a ratio here, in this case 80%. This means that with the configurations I used, I will have 20% of the dataset for the test set used at the end and another 20% of 80% for the hyperparameter validation set, which is relatively standard. If your dataset is time ordered, you can also specify the column on which you have a time, so that the test and validation datasets are chosen after the train set.
How can models created using AutoML in Dataiku be deployed?
In the visual analysis, you are going to do experimentations, and once you are happy with the model you have found, you can deploy it. It becomes a saved model in the flow. This saved model in the flow can be used for deployment, for scoring, or to create a REST API. You can also retrain saved models if you have a new dataset coming in.
Can you dynamically deploy a model with Dataiku AutoML?
Yes. For example, if you get new data every day and you train at the end of each day, you deploy the winning model for that. You can do scenarios which allow you to run flows or parts of flows based on certain triggers. Once a day, you can inject data and retrain your model once it has been deployed on the flow as a set model.
Then, there is an evaluate recipe that can compute not only the prediction, but metrics like the R-square or accuracy. That will allow you to effectively compare two versions of the model and to decide whether to redeploy or not. There are scenario steps available to redeploy the new model on an API node, allowing you to retrain and redeploy after making sure the models are improved.
In the Dataiku AutoML tool, is it possible to raise an alert if the accuracy of the deployed models declined over time?
Yes, the flow will allow you to do that. In the scenarios, you have various ways to send alerts to the Microsoft team, to Slack, to email, etc. in case there is an issue.
What do the feature generation and feature reduction tabs do in Dataiku AutoML?
Feature generation will allow you to do a pairwise linear combination, pairwise polynomial combination, or explicit pairwise interaction. You can choose whether to enable them or not, along with the two variables for which you want to see an interaction. With feature reduction, you can typically choose to do a PCA or LASSO regression or correlation with target in order to do some feature reduction before running the algorithm.
In Dataiku AutoML, is the machine learning able to create different features?
Yes, in feature generation. For example, with pairwise linear combination, it’s going to generate A+B and A-B features.
Conclusion
You can reference the datasets used in the demo by checking the “Attachments” section of the AutoML end-to-end demo webinar. By automating machine learning, organizations can inject efficiency into various stages of the data pipeline. AutoML’s impact on staff makeup and the types of work different profiles are doing is no longer a fleeting trend but rather a growing function that will continue to shape and impact the entire data-to-insights process and how data teams are structured.