




{kind=link}
If you're like me and you work near data but don't have much technical background, you must have heard about Hadoop. Let's try and figure out what it is together.
Ever since I started working, words like Hadoop and Spark have been popping up every day, and I kept wondering what it could mean. With my limited technical background it was sometimes hard to keep up with discussions at the office. Luckily, in the past month, I’ve had the opportunity to speak to all of our brilliant data scientists and developers, as well as a couple of data experts. I’ve learned so much about data science and big data infrastructure and I figured there might be people out there who were as clueless as me when I first heard the words Hadoop, Hive, or Spark.
So here is my investigation into what the heck Hadoop and Spark is. It is a long and winding path, and there are several obstacles to overcome along the way, so I couldn't write about it all at once and made it into a quadrilogy:
- Episode 1: A little history about distributed data and Hadoop, why, and how it was done before Spark
- Episode 2: Enter Spark: what it is, what it changes
- Episode 3: The epic battle between Spark and Hadoop
- Episode 4: Hadoop meets Spark in Dataiku, the reconciliation
So let us begin our journey into big data.
It All Begins with a Definition
The first step to understanding what Hadoop or Spark is was of course Googling it, and checking Wikipedia:
Suffice it to say, that was not helpful. Luckily we have lots of people at Dataiku who took some time to clear things up for me.
The first part of the definition is that Hadoop is an open source cluster computing framework. That means that it’s used to process data that is distributed across clusters. So step 1 in understanding this Hadoop business is understanding clusters.
![]()
Yes, Hadoop has one of the cutest logos in Big Data.
Why Do You Distribute Data Storage?
The general idea is that when you start collecting, storing, and analyzing really large quantities of data, storing it on one machine makes it really inefficient if your data doesn’t fit in your machine’s RAM (Random Access Memory - a part of your computer’s storage that’s accessible fast but volatile).
You also don’t want to have all of your data stored in just one place because if that one computer goes down, you lose everything. And one of the rules when working with computers is that they always crash. Moreover, the more data you have stored in one server, the longer it takes to read through it to find the relevant information.
The Origins of Hadoop
These issues first started preoccupying Google, whose business model is based on storing huge amounts of data and having access to all of it at one time. Makes sense. Their system was adapted into the Hadoop Distributed File System (HDFS for experts).
The basis of the system is to store the data on a cluster of servers. Instead of having to invest in a really large server, the system functions on the hard drives of lots of computers that you can compare to your PC. This system is infinitely scalable.
The data is stored redundantly (meaning the same information is written on several different servers, usually three), so that the system isn’t weakened by one server going down. The data is processed with the processing system Hadoop MapReduce which operates over the cluster resource manager Hadoop YARN. MapReduce can take distributed data, transform it (Map), and aggregate it (Reduce) into other useful data.
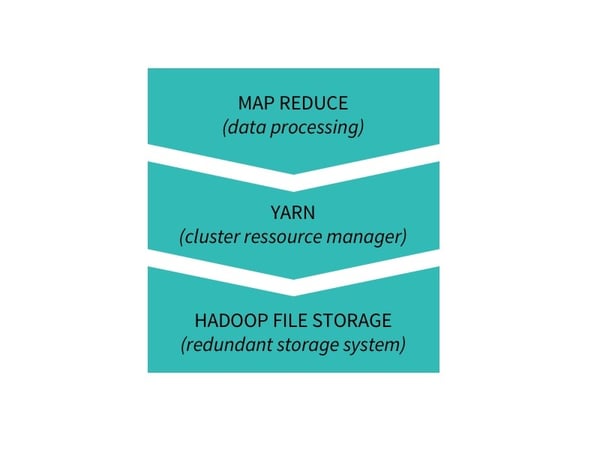
A basic Hadoop stack
The cluster of servers is made up of a client server, a driver node, and worker nodes (they’re also often called master nodes and slave nodes, but that’s not super politically correct). A node is a server by the way, which is basically a computer. I am grossly simplifying, but the driver node distributes jobs and tracks them across the worker nodes, which execute the jobs. The client server is where HDFS, MapReduce, and YARN are installed. Data is loaded into the client server when it is written by HDFS or processed by MapReduce, and then it is written on the worker nodes (and YARN manages the resource allocation or the jobflow). Basically, YARN is da boss.
Whenever you write a new record or when you make a query, the driver clusters know exactly where to write or where to find the info in the worker clusters thanks to the metadata ("data about data") stored by HDFS.
There are then a whole lot of layers on top of MapReduce as well, like Hive that allows you to write SQL queries and Pig to code in Pig Latin. This is important because MapReduce is in Java and pretty hard to program without those additions.
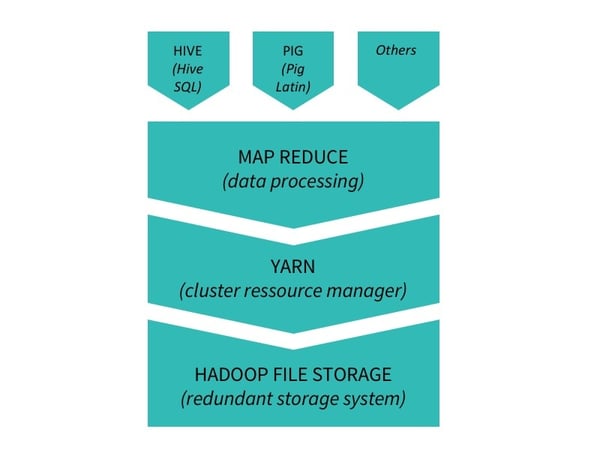
A little bit more advanced Hadoop Stack
Hadoop Rules
The Hadoop ecosystem allows you to store large amounts of data and access it faster. It’s cheaper to set up than a ginormous server and also much faster for processing the data. Indeed, when you multiply the number of machines, you’re exponentially multiplying the processing speed as well as the number of jobs you can run at the same time. The redundancy principle built in HDFS means the system is protected against server failures.
And that's it for episode 1! Read along for part 2 of my investigation into Spark vs Hadoop: when Spark-the-underdog rises against Hadoop-the-great in an epic battle for big data domination. But are they really enemies?