




{kind=link}
I — probably like many before me — like to think of data science (and more generally of big data) as a process of a final outcome: deployment into production. The thing is, putting a model to production is often more complicated than it seems; setting up automation scenarios is a way for IT teams to make this last step both easier and trackable.
How I Picture the Data Science Process
 A (very) simplified diagram of a classic churn project
A (very) simplified diagram of a classic churn project
It all begins with a very basic and simple question: what are you trying to predict? Do you want to estimate the amount your new customers are going to spend on your website? Do you want to predict which of your users are about to churn? And how is this data going to help you get there? So, the first step is clearly defining your goal.
Once you know what you’re aiming at, it’s time to dig in and get your hands data dirty. You first want to collect all the data (logs, CRM data, transactional data, social data, etc.) that can help you — one way or another — manage your final prediction. Then, you need to prepare and to clean all that raw data to make it completely homogeneous and therefore easier to analyze. Seems quite easy, right? Well, this whole data munging step is typically the most time-consuming one. It often represents up to 80% of the time data scientists spend on a project.
 When data scientists are done cleaning their data
When data scientists are done cleaning their data
Then enters machine learning. This is the part when you get to build, to train, and to test several models to determine which one is the most efficient and likely to actually produce accurate predictions.
When you’ve tested, iterated, tested, iterated, and finally arrived to a model that is fit for production, voila you’re done! Except that that is never the case. Deploying a model is a lot more complicated than a “voila, let’s do it scenario.” Why? Let’s find out.
Why Is Putting Projects in Production So Tough?
The reasons for this are multiple. One of the core problems revolves around the technological inconsistency between what we could call the prototyping and the production environment. As the two infrastructures are different and as the people working on them have different trainings and skill sets, both environments evolve with different languages (for instance R for prototypes vs Java, C++ for production), which means putting a project in production sometimes requires the production team (usually IT) to recode the whole model into what is deemed the appropriate language.
 This is a warrior data scientist trying to deploy his model to production
This is a warrior data scientist trying to deploy his model to production
Another big issue data scientists have to face when putting their models into production is recomputing. And why is that? Because they’re operating on data, and data definitely isn’t something that’s frozen in time. Data is more of a flow that gets refreshed and enriched by interactions between humans and machines.
And it’s precisely because data is regularly updated, that what results from data needs to be frequently updated as well. That’s why if they want to have valuable and updated data-generated insights, data scientists need to regularly recompute their datasets, their models, and so on.
This is even more true when your project requires that you use your model in real-time. Let’s take a tangible example. Picture yourself as an application developer working for a bank. You’re responsible for developing a mobile app allowing customers to apply for a loan just by making them fill in a form with their requested loan amount and their name. The bank’s data team has provided you with a great model able to predict whether or not the customer is likely to refund the loan.
Once the customer has filled in the form, the app should ask servers about the customer’s data, use the model, and automatically return a screen telling the customer whether or not the bank has accepted their loan request. Great process right? But before deploying your model into production, you want to make absolutely sure your models and your data are regularly updated. Otherwise your app might for instance accept a loan that would not have been accepted by a classic bank advisor, which could get you into trouble.
The thing is, to really be up-to-date, insights need to be recomputed very frequently (sometimes up to several times a day) from many different sources and recomputing often involves lots of processing steps.
How Scheduling Is Probably Going to Save Your Life (Or at Least a Bunch of Working Hours)
There’s a way to automate this whole (and fairly unrewarding) recomputing process, and it’s called scheduling. So, what is scheduling really? And how does it work? Scheduling is basically a way to automatically and easily refresh your data.
What you first need to do to set up a schedule is describe your data pipeline as dependencies between datasets (from your very first ones with raw data to the final ones containing your predictions) and tasks (cleaning, joining, etc.).
 How the dependency structure of a project is represented in the flow tab of Dataiku DSS
How the dependency structure of a project is represented in the flow tab of Dataiku DSS
Then, you have to define what we call an automation scenario. An automation scenario is a sequence of several actions you want to perform on your different “data objects” (datasets, models, folders, etc.) to keep your insights updated. There are three different tasks you need to complete to set up a scenario.
First, the trigger: you have to define what is going to launch the recomputation. There are several ways to characterize a trigger: it can for instance be time-based but it can also follow a dataset or queries results changes.
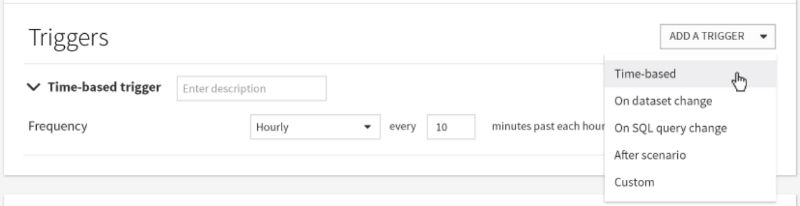 The trigger setup in Dataiku DSS
The trigger setup in Dataiku DSS
Once your trigger has been defined, you have to list the different actions that need to be done in order to update your insights. You basically have to create a sequence of steps such as checking or rebuilding a given dataset, computing metrics, refreshing insights, and so on.

The implementation of the steps sequence in Dataiku DSS
Finally, you want to add reporters to get notified when a scenario is done running (or is beginning). You can define the notification channel that suits you best (Hipchat, Slack, emails, etc.), the running conditions of the reporter (when do you want to get a message: if a model has changed of more than 10%, if there’s been an error during the recomputing process, etc.) and the type of message you’re willing to receive (text message, status, etc.).
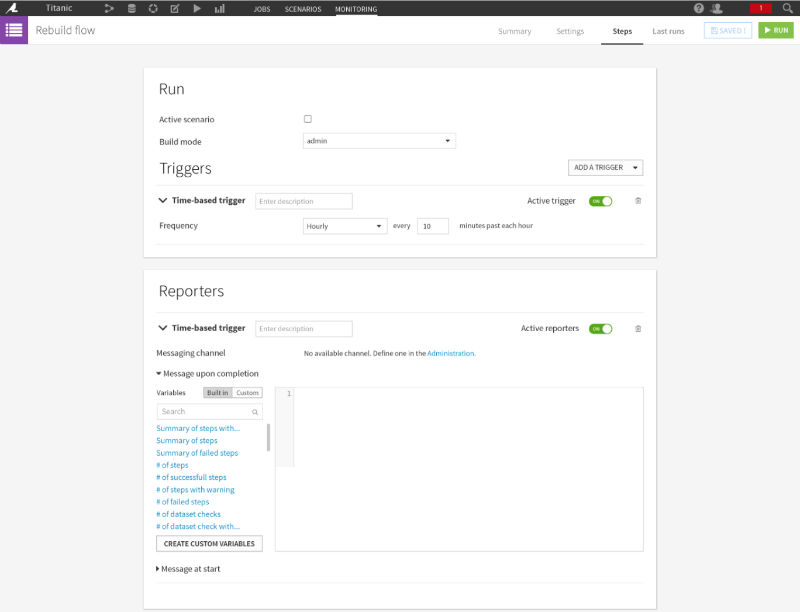 The reporter setup in Dataiku DSS
The reporter setup in Dataiku DSS
And there you have it: your very first automation scenario! Combined with the dependency structure of the project, the automation scenarios allow a comprehensive description of your data pipeline autonomous recomputation.
The great thing in Dataiku DSS is that you can both run several scenarios from different projects at the same time and monitor the whole thing on a single screen called “scenarios monitoring”.
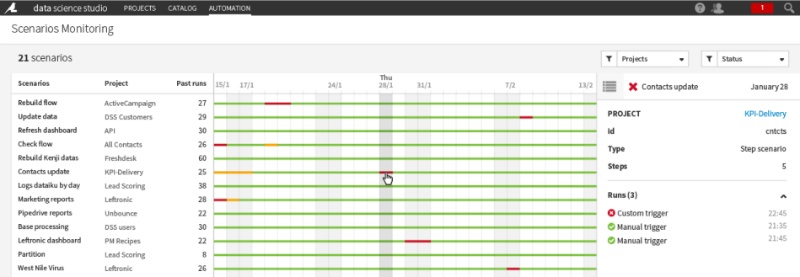
The Scenarios Monitoring screen on Dataiku DSS
So you got it, scheduling is basically an empowerment of our data science process as it makes its last step — the production deployment — way easier… and trackable. That’s part of why we use the term “end to end” when we describe what Dataiku DSS enables data teams to do in terms of data products: it allows them to go from start (data preparation, etc.) to finish (data visualization, production, etc.) on a single platform all the while letting them leverage the tools, languages, and models they know best.