




{kind=link}
With the U.S. election around the corner, I thought it would be both informative and fun to explore a few topics in natural language processing (NLP).
In this post, I will go over the workings of a simple text generator and apply it to a bunch of Donald Trump's and Hillary Clinton’s campaign speeches that I found on www.whatthefolly.com.
The method I am presenting in this post — Markov text generator — is hands down the most basic text generator in natural language generation (NLG, a subfield of NLP).
As a result, I thought I would do things differently and augment this simple method with a “back-off” feature. As we will see below, a back-off scheme helps prevent the Markov generator from spitting out text that is too similar to the text on which it was trained. Back-off is not the only way (nor the best way) one can mitigate overfitting, but it’s nonetheless very intuitive.
Who Is Markov and What Did He Do Anyway?
 Andrey Markov was a Russian mathematician who made notable contributions to Stochastic Processes theory, primarily with what became known as Markov chains and processes.
Andrey Markov was a Russian mathematician who made notable contributions to Stochastic Processes theory, primarily with what became known as Markov chains and processes.
A Markov chain can be thought of as a sequence of states with the property that at each state, the probability of transitioning to another (possibly the same) state depends only on the current state. This property is usually called the memory-less property or simply the Markov property. For example, with only two possible states (rainy or sunny), the property says that the probability of rain tomorrow only depends on whether today was sunny versus rainy. It doesn’t depend on what the weather was like two or more days ago.
Continuing with our weather example, we make up the following transition matrix that specifies the probabilities with which one can transition from one state to the other.

0.8 and 0.4 are the probabilities that tomorrow is sunny given that today is either sunny or rainy, respectively. 0.2 and 0.6 are the probabilities that tomorrow is rainy given that today is either sunny or rainy, respectively.
Now starting with a vector indicating that today is sunny [1,0], we can find the probability of sun and rain to be: [1,0] P = [0.8, 0.2]
We could argue that the memory-less property is not reasonable to model weather transitions, especially because it doesn’t take seasons into consideration. To gain in realism, we could somewhat relax this memory-less assumption by assuming that the probability of transitioning to some state depends not only on the current state but also on the previous state. This means that in our example, we’d wind up with a 4-by-4 transition matrix.
We could also decide to have the transition probabilities depend on an even longer history of states. This would cause the transition matrix to grow quite rapidly in size. In applications, where one is usually trying to estimate those probabilities for hundreds or thousands of distinct states, having a long history of states may cause inference problems. We simply do not have enough data to estimate reliable probabilities of the transition matrix. In our text generator below, this translates to data overfitting.
Markov Text Generators
Markov chains sound interesting but how do they help us build a text generator? Consider the previous example but now think of states as the unique words in a corpus (that is, a collection of texts from a same author): the most basic Markov text generator is just a model that (wrongly) assumes that the probability of a word showing up in a text or a conversation only depends on the current word being written or said.
We can then estimate the probability of transitioning from one word to another by simply listing all different words in a text and keeping track of which words come right after them. This allows us to determine the frequency with which one word follows another. From there, it is easy to deduce probabilities.
To help fix ideas, consider this simple text example:
"On weekdays, I drink coffee in the morning. If coffee tastes bad, I dump it in the sink and drink tea instead."
Let’s look at all the current words (left column) and the corresponding pool of words following them (commas and periods are considered to be words as well):
| Current Word | Next Word |
| (‘morning') | ----> ['.'] |
| ('the') | ----> ['morning', 'sink'] |
| ('sink') | ----> ['and'] |
| ('and') | ----> ['drink'] |
| ('On') | ----> ['weekdays'] |
| ('in') | ----> ['the', 'the'] |
| ('coffee') | ----> ['in', 'tastes'] |
| ('I') | ----> ['drink', 'dump'] |
| ('tea') | ----> ['instead'] |
| ('If') | ----> ['coffee'] |
| ('it') | ----> ['in'] |
| ('drink') | ----> ['coffee', 'tea'] |
| ('dump') | ----> ['it'] |
| ('bad') | ----> [','] |
| (‘tastes') | ----> ['bad'] |
| ('weekdays') | ----> [','] |
| ('.') | ----> ['If'] |
| (',') | ----> ['I', 'I'] |
| ('instead') | ----> ['.'] |
This means that if the current word is “the”, we estimate that we can transition to "morning" or ‘sink’ both with probability one half. If the current word is “,” , we transition to “I" with probability one. The same goes for current word “On" and its next word “weekdays”.
Once we have all the probabilities, we can then see how our text generator actually generates text. We start by feeding it a word from the corpus. If we feed it the word “If”, it will choose the word “coffee” with probability one. Then, it moves forward and selects one word that comes after “coffee” . Observe that it can either choose “in” or “tastes”, each with probability equal to one half. The process goes on until we tell it to stop. The fed word and every word chosen by the model along the way is written down to form text.
Among the possible sentences that could be generated, we have the following weird ones:
“If coffee tastes bad, I dump it in the morning."
“If coffee in the sink and drink tea instead."
We see that the sentences generated are neither grammatically correct nor sensical. This is the major problem associated with Markov chain generators — their memory-less property means that the only context on which their word choice is based consists of a limited number of previous words. Of course, as explained above, we could enrich the context by considering longer context sequences. For instance, using the above example, we list all subsequent two-word sequences along with their next words.
| Current Words | Next Word |
| ('weekdays', ',') | ----> ['I'] |
| ('sink', 'and') | ----> ['drink'] |
| ('drink', 'coffee') | ----> ['in'] |
| ('drink', 'tea') | ----> ['instead'] |
| ('.', 'If') | ----> ['coffee'] |
| ('If', 'coffee') | ----> ['tastes'] |
| ('tastes', 'bad') | ----> [','] |
| (',', 'I') | ----> ['drink', 'dump'] |
| ('tea', 'instead') | ----> ['.'] |
| ('bad', ',') | ----> ['I'] |
| ('dump', 'it') | ----> ['in'] |
| ('coffee', 'tastes') | ----> ['bad'] |
| ('I', 'drink') | ----> ['coffee'] |
| ('the', 'morning') | ----> ['.'] |
| ('the', 'sink') | ----> ['and'] |
| ('it', 'in') | ----> ['the'] |
| ('On', 'weekdays') | ----> [','] |
| ('morning', '.') | ----> ['If'] |
| ('coffee', 'in') | ----> ['the'] |
| ('and', 'drink') | ----> ['tea'] |
| ('in', 'the') | ----> ['morning', 'sink'] |
| ('I', 'dump') | ----> ['it']
|
Here, if we feed the generator (‘in’, ‘the’), it will either choose ‘morning’ or ‘sink’ with probability one half. If it chooses ‘sink’, the generator then picks the next word that comes right after the sequence (‘the’, ‘sink’) and so on.
Using a two-word model prevent non-sensical sentences like “If coffee in the sink and drink tea instead.” from being generated. The reason is that there is no “in” following the sequence (“If”, “coffee”).
In fact, as we make context sequences longer and longer, we are more prone to overfitting the data. Put differently, our generator produces long streaks of words that are just ripped off from the text that was initially used to compute the probabilities.
Adding Some Back-Off to Our Markov Text Generator
We saw that using longer context sequences can help the model generate more sensical and human-looking texts. However, we noted that we would expose ourselves to overfitting. Ideally, we would want to use the longest possible sequences so long as the pool of words following them is large enough.
This is exactly what “back-off” does. Essentially, back-off consists in telling the generator to start with a sequence of i words and check if the size of the pool of possible next words to that sequence is larger than some specified value. If the size requirement isn’t met, the model falls back to a shorter sequence consisting of the last i-1 words from the previous sequence, and the process is repeated. When the size requirement is met, the model chooses a next word at random and then moves on to a new sequence consisting of the last i-1 words from the original sequence followed by the newly selected word. If a given sequence is shrunk down to its last word, the requirement is ignored and a next word is chosen.
Returning to our example, suppose we require the generator to consider sequences that are followed by at least two words. Let’s feed our generator the sequence (',', 'I')
. (',', 'I') ----> ['drink', 'dump']
The two-word requirement is met and so the generator chooses one of the following words at random. Suppose it chooses drink. The generator then slides to ('I','drink')
('I','drink') ----> ['coffee']
From there the generator can only transition to the word ‘coffee’—the two-word requirement isn’t met. As a result, the generator shrinks the context sequence to ('drink')
('drink') ----> [‘coffee’, 'tea']
Here the two-word requirement is met. Suppose the word coffee is chosen. The generator then slides to the context sequence (‘drink’, ’coffee’) and the process goes on.
Put differently, this back-off procedures allows us to base word choice on a long sentence only if that long sentence is frequent enough in the corpus. That way, this model will tend to generate long sentences that candidates say more frequently--we are capturing speech manners.
Applying Our Markov Text Generator to Trump and Clinton Speeches
Here is what I got when applying my text generator to approximately 60 Trump speeches and and 90 Clinton speeches. I used sequences that are up to 10 words long and requiring that at least three words follow each sequence.
In what follows, I chose some of the gems I came across. Warning, not all of the examples make sense.
Trump Quotes:
“I 'm a common sense conservative. Well him. I think. You know, now I hear it ? I mean, you 're in the real numbers that these countries that are taking our jobs, they take our money. They take everything."
“She 's being protected by the Democrats. She 's on tape, I just think - you know, they have boxes. They've gone solar and supported by massive - yeah, you have these big massive percentages. Thank you. Thank you.”
“We've been number one, he should have won but that 's all I want people to come into our country who supports Scotland 's like the Veterans Administration is the same thing.”

Clinton Quotes:
“I have been and I applaud Sen. Sanders has said he has no credible plan to make college affordable, how we 're going to make college affordable, how we can save money. I worked with him about issues that really hasn't paid in 2017 more about Russian aggression and you will join me for helping us make sure women who finish college tuition are on the brink. But I am very grateful to all of our volunteers who have been slaughtering innocent people.”
“I've voted against the common sense and common action against Iran and Russia - 10 hours in the house.”
“They became great opportunities from France, Germany, Belgium, he 's going to go think ? I 'll be the clean energy superpower quite so hard. It 's why I've laid out a national goal.”

Using Dataiku DSS to Prepare That Text Data
Dataiku DSS is pretty convenient to prepare the data. We can tokenize sentences (that is split sentences into a list of words) and form word sequences in just a few clicks.
We can then go straight to the meat of the Markov text generator without wasting time on data prep.
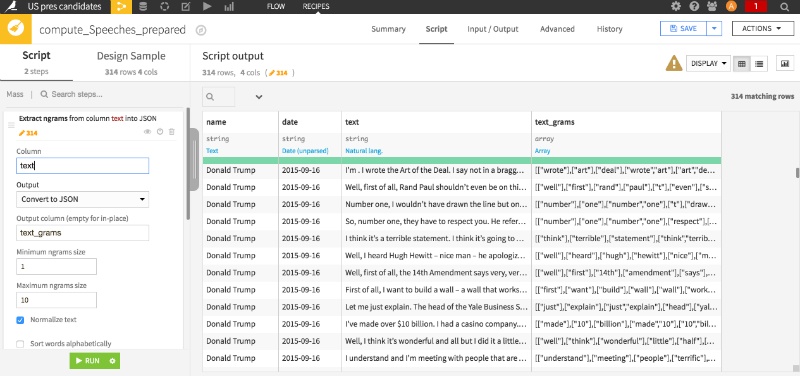
How to use Dataiku DSS to tokenize text and create grams
In this post, I've nonetheless pasted the full Python code in case you’re too shy to try out Dataiku DSS.
import random
import nltk
class markov(object):
def __init__(self, corpus, n_grams, min_length):
"""
corpus = list of string text ["speech1", "speech2", ..., "speechn"]
n_grams = max sequence length
min_length = minimum number of next words required for back-off scheme
"""
self.grams = {}
self.n_grams = n_grams
self.corpus = corpus
self.min_length = min_length
self.sequences()
def tokenizer(self, speech, gram):
"""tokenize speeches in corpus, i.e. split speeches into words"""
tokenized_speech = nltk.word_tokenize(speech)
if len(tokenized_speech) < gram:
pass
else:
for i in range(len(tokenized_speech) - gram):
yield (tokenized_speech[i:i + (gram + 1)])
def sequences(self):
"""
create all sequences of length up to n_grams
along with the pool of next words.
"""
for gram in range(1, self.n_grams + 1):
dictionary = {}
for speech in self.corpus:
for sequence in self.tokenizer(speech, gram):
key_id = tuple(sequence[0:-1])
if key_id in dictionary:
dictionary[key_id].append(sequence[gram])
else:
dictionary[key_id] = [sequence[gram]]
self.grams[gram] = dictionary
def next_word(self, key_id):
"""returns the next word for an input sequence
but backs off to shorter sequence if length
requirement is not met.
"""
for i in range(len(key_id)):
try:
if len(self.grams[len(key_id)][key_id]) >= self.min_length:
return random.choice(self.grams[len(key_id)][key_id])
except KeyError:
pass
# if the length requirement isn't met, we shrink the key_id
if len(key_id) > 1:
key_id = key_id[1:]
# when we're down to only a one-word sequence,
#ignore the requirement
try:
return random.choice(self.grams[len(key_id)][key_id])
except KeyError:
# key does not exist: should only happen when user enters
# a sequence whose last word was not in the corpus
# choose next word at random
return random.choice(' '.join(self.corpus).split())
def next_key(self, key_id, res):
return tuple(key_id[1:]) + tuple([res])
def generate_markov_text(self, start, size=25):
""""start is a sentence of at least n_grams words"""
key_id = tuple(nltk.word_tokenize(start))[ - self.n_grams:]
gen_words = []
i = 0
while i <= size:
result = self.next_word(key_id)
key_id = self.next_key(key_id, result)
gen_words.append(result)
i += 1
print start + ' ' + ' '.join(gen_words).replace(' .', '.').replace(' ,', ',')
doc = ['This is your first text', 'and here is your second text.']
# For better results, use large corpora
mark = markov(doc, 2, 2)
mark.generate_markov_text('type a sentence that has at least n_grams words', size=25)