




{kind=link}
Digital marketing optimization amounts to developing digital media mechanisms which improve conversion of website visitors into customers of your products or services.
Data from web sessions can be augmented with CRM matchings, geographic positioning (from mobile data, IP address, or other sources), historical data such as past purchase history, and whatnot. Every industry and company has its own private stash of data and channels which makes it difficult to describe a unique works-for-all approach.
However, there are common recipe ingredients in any solution:
-
a combination of multiple data sources; flat files, databases etc.
-
a large amount of data (the more the merrier) which easily pushes solutions into Hadoop-like platforms
-
machine learning (ML) algorithms; typically stochastic decision trees but also XGBoost
-
the need to predict potential new customers and which incentives will convert them
-
the classic factors: churn rate, propensity, and others
-
the need to deliver high-level visualizations for marketers and executives
Technically, this means a mixture of big data tools (Spark, MLLib, Hadoop, etc.), R and Python programming, ML algorithms, dataviz through HTML/JS… and all of this needs to come together in a reusable, repeatable, and collaborative workflow.
This can be a daunting challenge but the good news is that the Dataiku DSS platform makes it very easy. Note: I did not say you don’t need to understand the subject matter or don’t need to code or that it is all click-and-go. Simply put: Dataiku DSS, as a platform, supports the whole process very well, especially the backend integration and the workflow. In what follows, I do not give you a magical solution for any marketing optimization problem, but a sketch of the steps I typically take to tackle such problems.
High-Level Overview
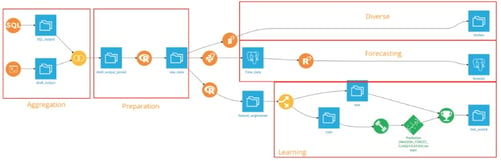
Within Dataiku DSS, we can define a workflow which, once defined, represents a repeatable, traceable, and collaborative pipeline:
-
the flow can be triggered when new data is dumped or on the basis of various other events
-
the parts can be developed independently by different people (i.e. collaboratively created)
-
the machine learning part can be deployed as a stand-alone REST service and integrated into other legacy processes
Note that in this flow there is a combination of technologies which all work together harmoniously:
-
Spark processing (MLLib, SparkR, PySpark, and all that)
-
standard Python and R processing; the integration of any (really, ANY) package/module can be plugged here and the connection to the flow context is via simple input/output of so-called managed datasets (basically CSV files which are project-bound)
-
SQL processing inside PostGreSQL/MSSSQL/MySQL/Mongo/etc. (you name it!)
-
Scala programming and ML
This should sound like paradise to any data scientist and it is!
Data Aggregation And Consolidation
Typically, the marketing data consists of CRM and database data. You can integrate in the flow shell scripting which can export CRM data to, say, a flat file via the vendor’s CLI. This is what you see in the lower part of the aggregation in the flow. The upper part is the extraction of data from a RDBMS. This is usually weblog data from site visitors: which pages did they visit at what time, what do they click on, what do they download, etc. The so-called touchpoints and attributes.
The aim is of course to have the ultimate full 360 degree view of what a visitor or existing customer does on your website. Through ML and time series analysis using this existing customer data, patterns are detected and modeled which are then used to recognize visitors with the highest probability of impending conversion (i.e. not yet a real customer).
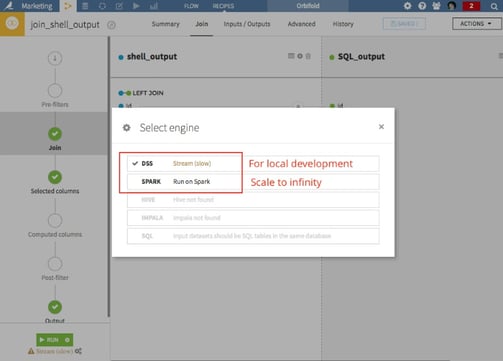
Do you need Dataiku DSS to do this? Strictly speaking, no of course not. The reason why you want to do this is to have the repeatable parts automated in one single flow. If another process needs to do this it means you need to link together processes or, worse still, manually trigger the process. With the shell, SQL, and Python recipes, you will likely be able to do 99.9% of anything out there, including REST calls, CLI, and API consumption of any kind. Joining datasets is based on common keys (primary key, mail address, etc.) and can be done in memory or in a Spark cluster. It means that you can effectively experiment with such flows on your desktop and scale to infinity once you are satisfied.
Data Preparation
Data cleaning and transformation is a chapter on its own. Dataiku DSS has a whole lot of time-saving features; for a good example see Building a Data Pipeline to Clean Dirty Data which highlights several cool techniques. In addition to the built-in processors, you can also fiddle with R/Python scripts. Everything depends on how much and how deep you want to go with your cleaning. Some of the cleaning can also be applied within the export step, the SQL processing, or through the CLI.
My experience here is that Dataiku DSS does a good job. Plenty of time-saving features like:
-
geo-conversions (to and from geopoints)
-
parsing of data types and dates in particular
-
splitting/merging columns and data extraction
I think the time saving also lies in the fact that you don’t need to look up the latest SparkFrame API, the million Pandas methods, or the confusing R logic. Many mundane tasks, such as parsing datetime are simple in Dataiku DSS. Cleaning is not the most exciting part of machine learning, so Dataiku DSS helps to keep your job fun and keep you focused on the creative part of data mining.
Modeling Customer Behavior Through Markov Chains
Website visitor behavior is not usually erratic but it does show a lot of noise. We can look at it like the way tourists travel by car to some destinations, say Madrid. The destination is the analog of a conversion (i.e. buying a service or product). If you look at all travelers who end up in Madrid, almost all behave differently: there are big highways and small roads. If you travel by car from Berlin to Madrid, you will take some highways, deviate for lunch, and possibly stop for the night. Everybody has a different rhythm and pace. If you look at millions and millions of people traveling from Berlin to Madrid, you therefore see patterns appearing. These patterns are described mathematically as Markov chains.
A Markov chain is like a graph with some probabilities on top. For example, after one day of traveling from Berlin, you have various probabilities of being around Paris. No certainty, but the highest probabilities are around Paris and not around Marseille. Similarly, when an arbitrary visitor visits Amazon searching for a book, there are plenty of probabilities from the homepage to the actual book. A Markov chain can capture these probabilities based on existing data. Once you have this model, you can predict how people use your site and which places they should visit (or not visit) to get converted.
Note that there are other ways to model website visitors: methods like persona segmentation and clickstream analysis are a few.
Within Dataiku DSS, you can define all of this in R, Python, or Scala. In the flow above, Spark processed the cleaned data using Malakov, a Scala Markov library. You can experiment with this outside the flow in your preferred environment and then plug the code into the flow. Dataiku DSS integrates Jupyter notebooks so you can experiment within a notebook without ever leaving Dataiku DSS. Jupyter notebooks are kept as part of the project and serve as another place where collaboration is possible.
Feature Engineering
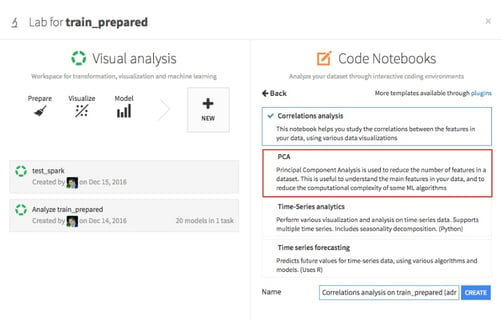
Feature engineering means combining, reducing, and/or augmenting features in any way which increases the accuracy of a predictive model (whether classifier or regression). When dealing with marketing data, it is not uncommon to have more than 100K features. This on its own is not a problem, but the sparsity of this often is. Typical metrics, like the Euclidean metric, do not function on sparse data. So things like noise reduction, PCA, and combinations thereof are used. Dataiku DSS contains a great utility which automatically performs PCA (see image) for you, including one-of-K (one hot encoding).
Feature engineering leads to hundreds rather than thousands of features. This is where the expertise of a data scientist shines (or not). Figuring out what works best is a combination of ML expertise, business understanding, and patience. Working hard helps.
Machine Learning And REST-Ifying Things
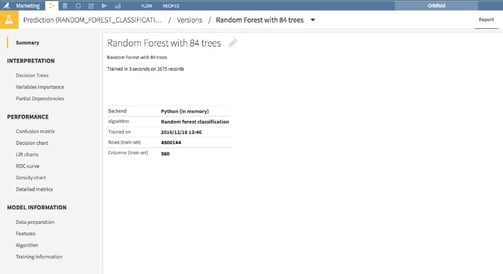
Here again, Dataiku DSS gives you superpowers to quickly figure out which ML algorithm best suits your context. Your infrastructure usually dictates what will happen: If you run atop Spark, you will use MLLib; if you choose Python the sklearn library is your choice, and so on. Dataiku DSS does it all. At the end of the experimenting and the crunching, you end up with a best-candidate model as a function of your predefined metric.
Often XGBoost or a decision tree variant will come out on top when dealing with marketing optimization.
(Note that in the visual ML training process there is an automatic splitting of the data for testing. Obviously, if you use plain Python code instead of the visual recipes (this is what they are called in Dataiku DSS) you can touch the metal here: programmatically use grid or stochastic search to optimize hyper-parameters and other attributes of your model.
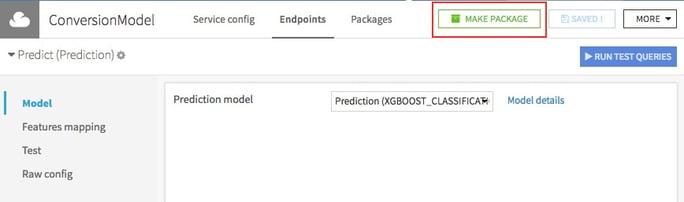
When you are satisfied with the model and the predictions, you can deploy the model so it can run as a standalone REST service. This means that you can predict how likely a non-customer is to convert in real-time. This can be augmented with propensity computations and more but the essence remains the same.
The deployment of this REST service is a topic on its own and is more a data engineering subject than a data scientist one. Let’s just say that Dataiku DSS has all of this covered too.
Bonus: Forecasting
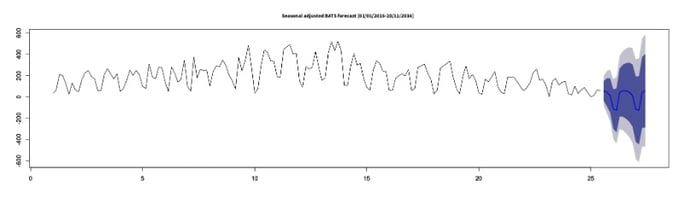
In the same way that Dataiku DSS allows for automatic PCA, it also allows output of a full-fledged forecasting model. Of course, forecasting (much like any ML) is an art on its own and don’t expect that this academic discipline will become obsolete any time soon (any GARCH and non-linear series?). The great things are that Dataiku DSS gives you a jump start and that time series analysis can be handled just as easily as any other data task.
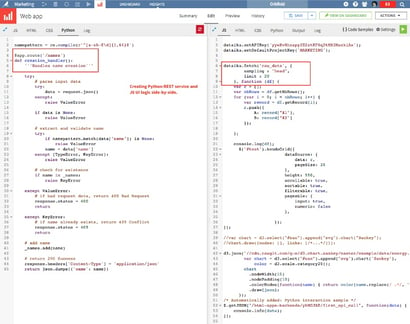
Data Visualization And Dashboarding
There are many very good JS libraries out there helping you to create stunning dataviz. My favorites are d3js and KendoUI. Sometimes I also create completely custom visualization on top of SVG or Canvas. In Dataiku DSS, you can do anything you like: mix-match JS libraries in whatever way since there is hardly anything pre-built here. Well, you can define charts and export them to the dashboard but the interactivity and cohesion cannot qualify as modern dashboarding. One thing that does feel great is the ease with which you can consume datasets and Python REST services. This is comparable to defining services in Flask, Bottle, or Django. The whole combination feels very powerful.
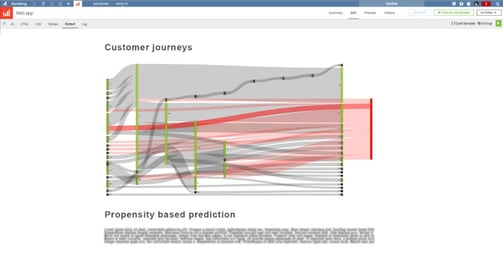
In our case of marketing optimization, I usually come up with a combination of Sankey diagrams, timelines, and custom widgets (see the adjacent image). This type of HTML/JS development is not where Dataiku DSS shines but it does feel great that this aspect is also neatly integrated in the whole project. In the end, this is what Dataiku DSS gives you: a grand kitchen and tools to cook great dishes and dinners. It’s not a tool to learn cooking or for fast food or for heating up pizzas; it is for serious professional haute cuisine!
Some Pointers
-
Dataiku has an overview of how to enrich weblogs which also explains how to extract colorful geo-representations of where visitors are from
-
there is a cool way to model marketing optimization in the same way one models stocks and shares through modern portfolio theory; some hints can be found here. We can easily integrate such an approach in the Dataiku DSS flow as well.
-
there is a dedicated marketing AI page on the Dataiku site where you can find diverse success stories in this business direction