




With more use cases to untap, more data science projects in the queue, and more performance metrics to hit, data science teams (and their broader counterparts throughout the business) are under a lot of pressure to decrease the amount of time it takes for them to do things like data prep and maximize productivity. Here, we provide five easy ways that Dataiku users can do just that, in order to ultimately spend more time on the high-value parts of the project.
1. Perform mass actions:
The Dataiku Prepare recipe provides an efficient way to run mass actions on multiple columns through the column view, therefore saving time. The first step in creating a recipe in Dataiku is to specify:
- The input (the dataset you selected to create the recipe)
- The output (the dataset you want to create using the recipe)
- Location (where you want to store the new dataset)
Once you create the recipe, your project flow should look like this:
The prepare recipe shows the table view by default, so to switch to the column view simply click on “Column view” in the top right-hand corner next to “DISPLAY.” Switching to column view will allow you to sort or filter the view so you can decide the next step to prepare your data. You can use the “mass action” to apply a specific processor on multiple columns and Dataiku will show you the relevant suggestion based on the mass selection:
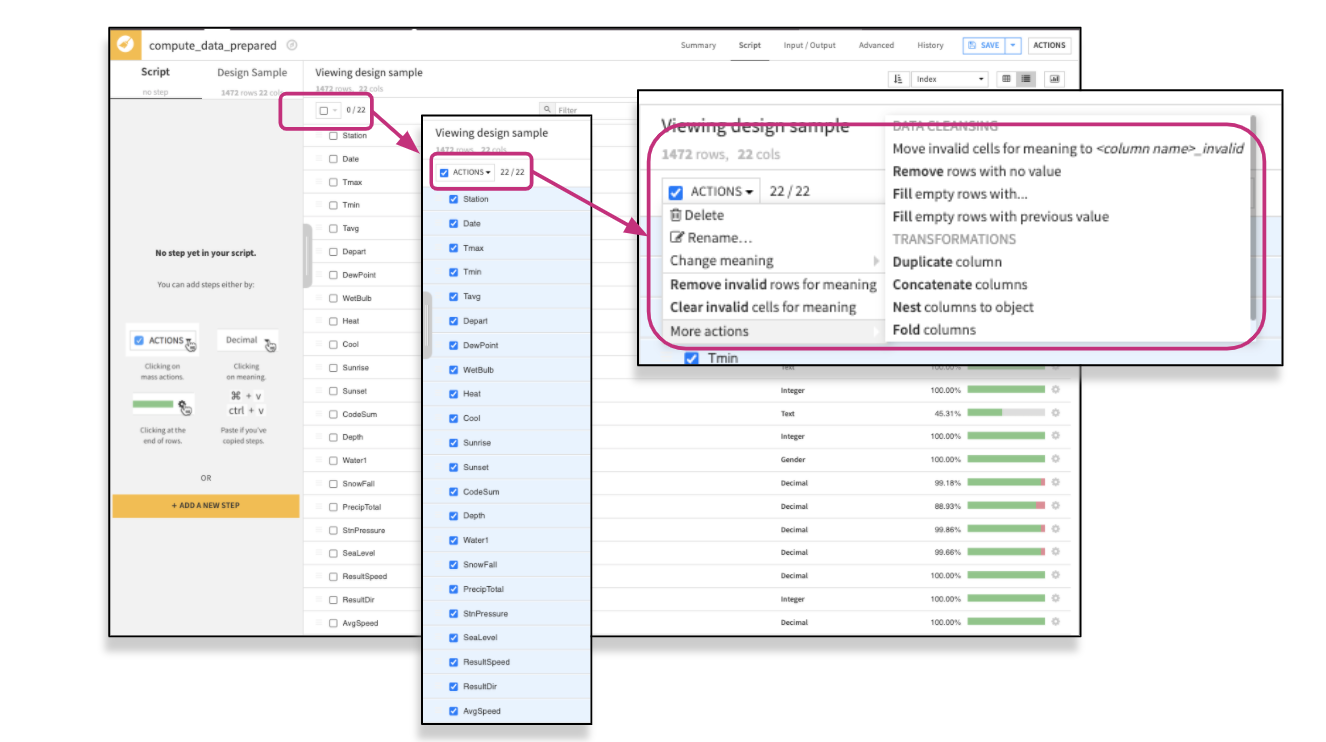
Then, once you’ve decided what actions you want to take on the data (i.e., round to integer) you select the processor and Dataiku automatically adds the step to the design script (which you can always go back and amend).
2. Quickly remove rows where the cell is empty:
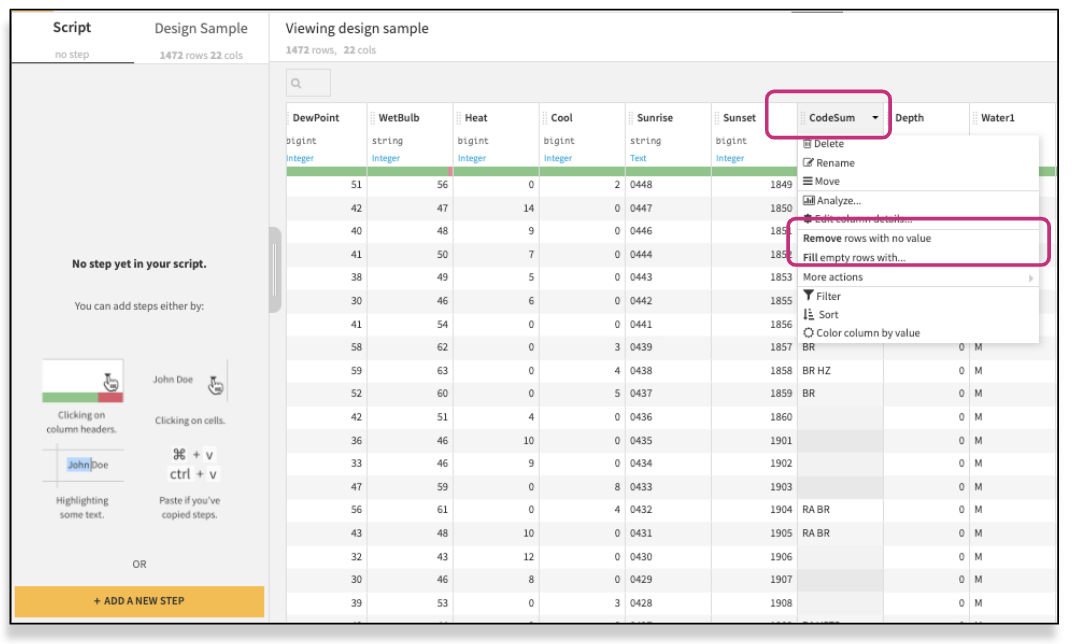
This processor removes (or keeps, whichever you decide) rows where the selected column is empty. The processor can act on a single column, an explicitly chosen list of columns, or all columns matching a given pattern. Like in trick one, this involves creating a Prepare recipe, which will provide suggestions based on the values detected in each column. Click on the arrow next to a column header and review the suggestion:
You can always check the processors available through the “Add a New Step” button:
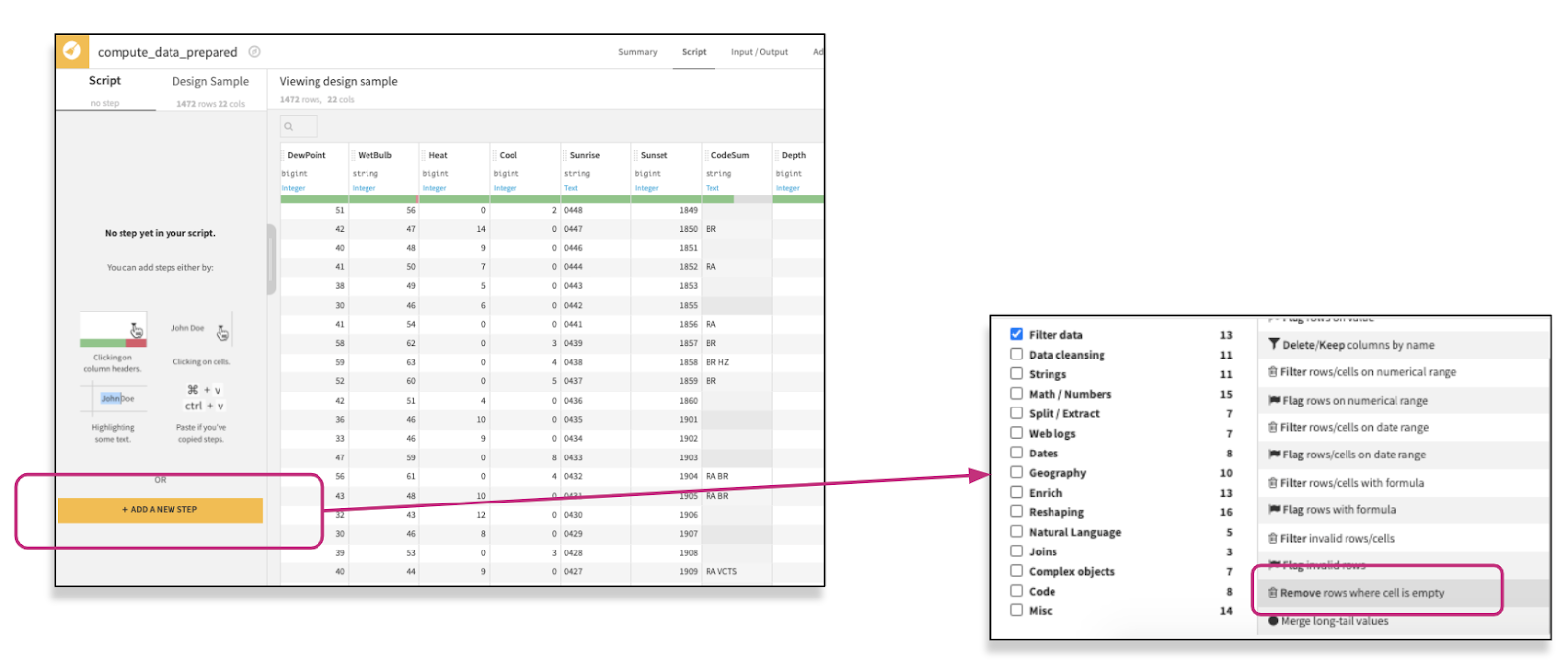
Following the suggestion will automatically fill the column name in the step of your script and will allow you to choose to either remove or keep the rows (knowing you can always add more columns to the processor). The Prepare recipe will show you how many columns were impacted by the action.
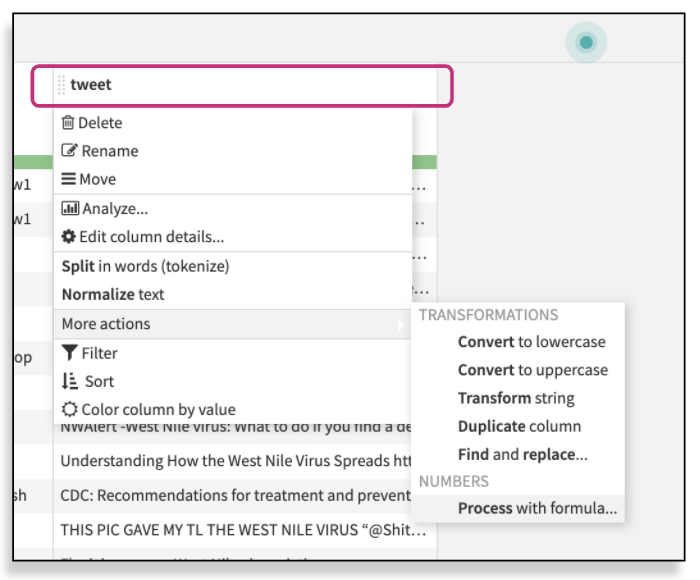
3. Extract with regular expression:
This processor filters rows containing specific values. Similar to removing rows where the cell is empty, this processor can check its matching condition on a single column, an explicit list of columns, or all columns that match a given pattern. Dataiku provides suggestions based on the values on each column in the dataset. Select the arrow next to the header and see what Dataiku suggests for you:
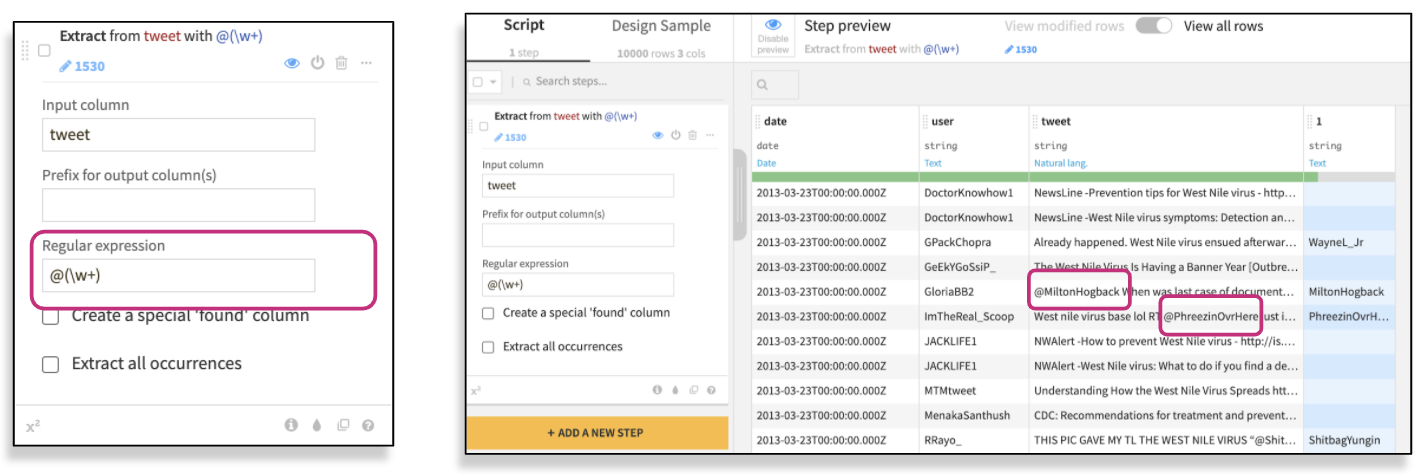
Add the parameters to extract the pattern from your dataset:
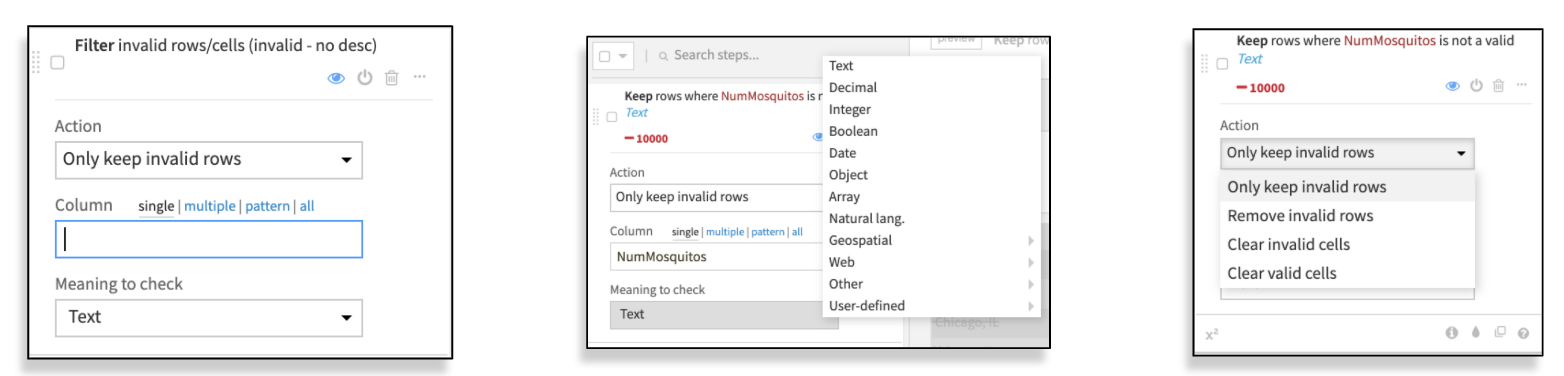
4. Filter invalid rows/cells:
In the Prepare recipe, find the processor “Filter invalid rows/cells” and add the name of the columns. Then, define the validity parameter according to the meaning. Finally, choose to keep, remove invalid rows, or clear valid or invalid cells:
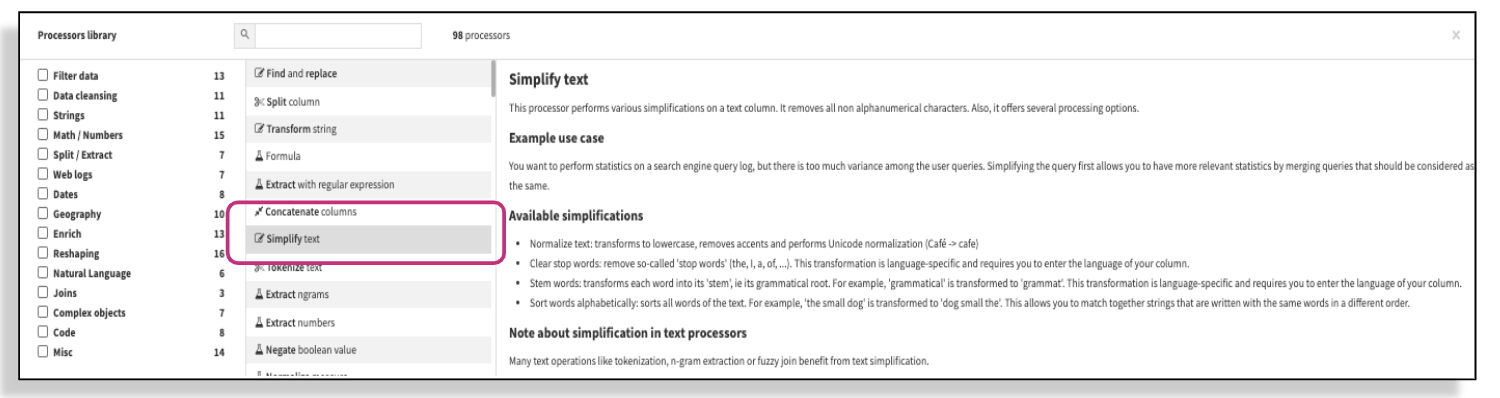
5. Transform strings/simplify text:
Text processing can come in handy for a variety of NLP tasks such as classification (i.e., is this email spam or not?) or prediction (what is the next word the user is going to type?). First, add a new step in a Prepare recipe and pick “simplify text.” As seen in the screenshot below, Dataiku provides a thorough explanation for each processor, including how it works, an example use case, and a link to Dataiku reference document for more information.
Then, specify the column you want to apply the processor to. You can choose to apply the changes on the same column or create another column and keep the original one with no changes.
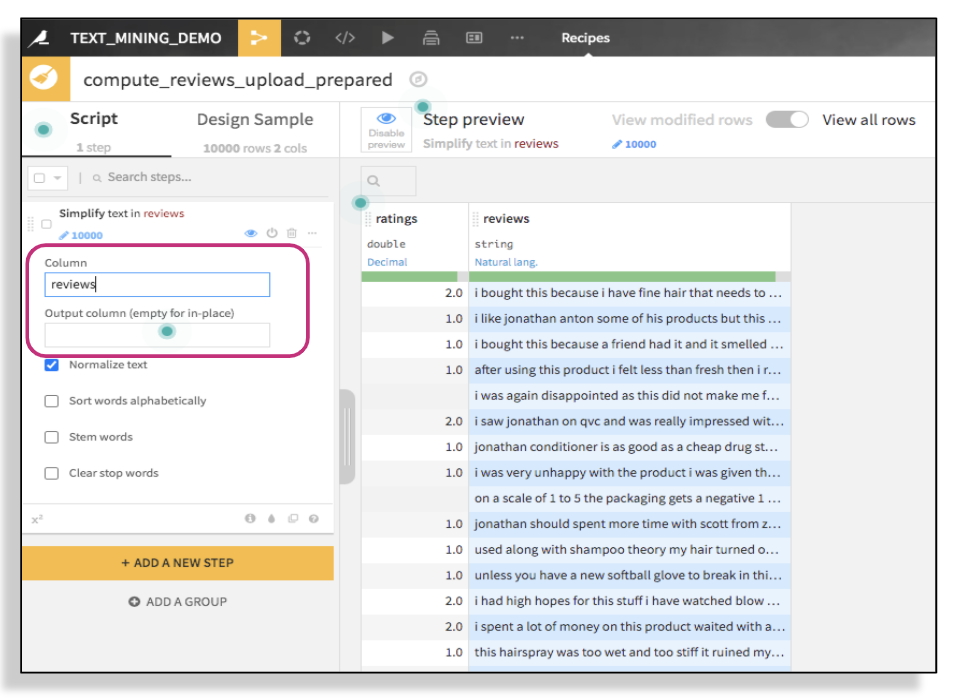
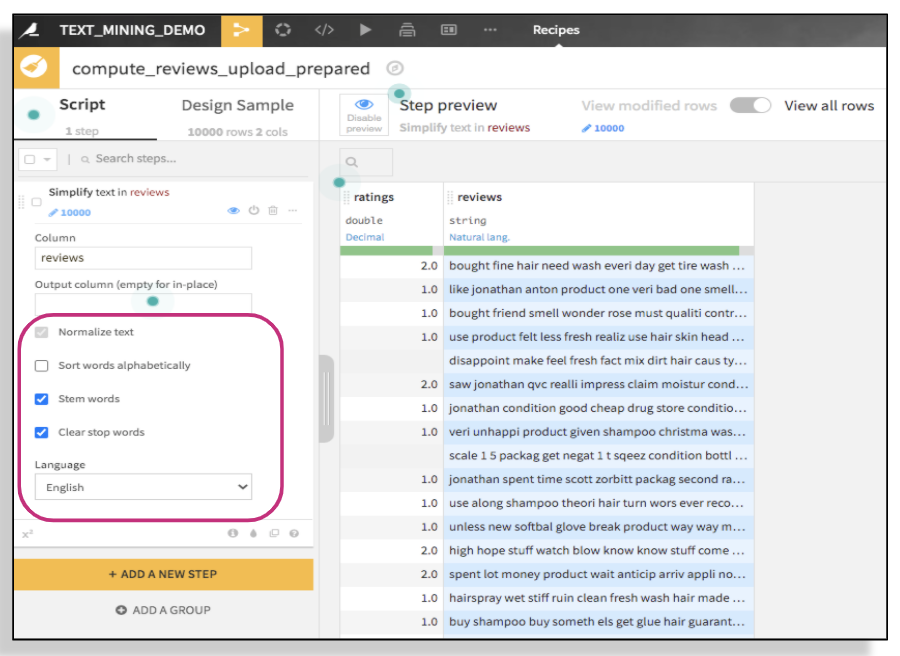
Next, select all the steps you want to apply — you’ll notice the values changing in the column based on your selections. Finally, run the recipe.
{kind=link}
A prime use case for this trick is if you want to perform statistics on a search engine query log, but there is too much variance among the user queries. Simplifying the queries first allows you to have more relevant statistics by merging queries that should be considered the same. Examples of available simplifications include:
- Normalize text: transforms to lowercase, removes accents and performs Unicode normalization (Café > cafe)
- Clear stop words: remove so-called ‘stop words’ (the, I, a, of, …). This transformation is language-specific and requires you to enter the language of your column.
- Stem words: transforms each word into its ‘stem,’ i.e., its grammatical root. For example, ‘grammatical’ is transformed to ‘grammat.’ This transformation is language-specific and requires you to enter the language of your column.
- Sort words alphabetically: Sorts all words of the text. For example, ‘the small dog’ is transformed to ‘dog small the.’ This allows you to match together strings that are written with the same words in a different order.
That’s it! We hope these data prep capabilities in Dataiku will help you save time by quickly transforming large datasets into consumable, quality information that can then be utilized further down the data science pipeline to, ultimately, drive value to the company.