




{kind=link}
Text classification consists in categorizing a text passage into several predefined labels. It is one of the most useful natural language processing (NLP) techniques and typical use cases include email routing, sentiment analysis of customer reviews, spam filtering, toxicity detection, etc. In practice, the circumstances may vastly differ from one use case to another. In particular:
- Labeled data may be abundant, scarce, or simply inexistent;
- The vocabulary used in the texts and the targeted labels may be common or very specific to the context of a particular organization;
- The organization implementing the use case may have limited or extensive NLP expertise.
In this blog post, we’ll present seven powerful text classification techniques to fit all these situations. We’ll see how they perform on a product reviews dataset and illustrate how they can be implemented in Dataiku.
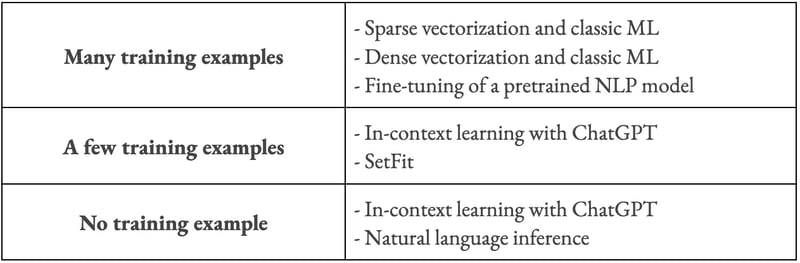 Text classification techniques discussed in this blog post
Text classification techniques discussed in this blog post
Standard Approaches
Sparse Vectorization and Classic Machine Learning (ML) Model
A simple approach for text classification is to convert text passages in vectors and then use standard ML algorithms such as logistic regression or tree-based models. The key question then becomes: How do you transform a text passage in a vector?
TF-IDF (or term frequency — inverse document frequency) is one way to achieve this vectorization. It returns a vector with one dimension for each word in a given vocabulary. Each component of this vector reflects the frequency of the corresponding word in the input text compared to the entire collection of texts.

Sparse vectorization with TF-IDF (left), dense vectorization with sentence embeddings (right)
Dense Vectorization and Classic ML Model
TF-IDF has several drawbacks. It does not consider the order of the words in the text and it ignores the semantic similarity between words. It also does not distinguish between the various meanings of a polysemous word (e.g., “sound” as in “a loud sound,” “they sound correct,” or “a sound proposal”).
A more effective approach, in particular if the training dataset is relatively small, is to use the vector representations (or sentence embeddings) obtained from a pre-trained deep learning model such as BERT.
Fine-Tuning of a Pre-Trained Deep Learning Model
The previous approach leverages a frozen deep learning model pre-trained on a very large collection of texts. Further performance gains may be achieved by fine-tuning this model on the specific task at hand.
Zero-Shot Approaches
Natural Language Inference
In the zero-shot setting, we are tasked to classify texts from previously unseen classes and no training example is available. Fortunately, we can still take advantage of large models trained on massive and diverse training datasets. For example, one zero-shot approach leverages natural language inference models.
In a natural language inference task, we are given a premise and a hypothesis and we need to determine whether the premise entails, contradicts, or is neutral with regard to the hypothesis. Let’s assume that we have a model trained on natural language inference. How can we use it for our text classification task? We can simply take the text passage to classify as the premise and define one hypothesis per class, such as “This review is about Cell Phones and Accessories,” “This review is about Digital Music,” etc.
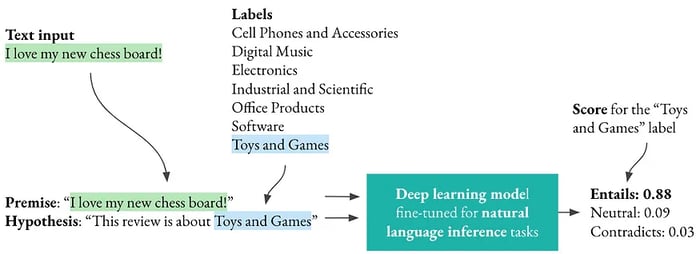
For all combinations of the premise and a hypothesis, we then just need to use a model already fine-tuned on a natural language inference task to assess to what extent the premise entails the hypothesis and select the class with the highest score.
In-Context Learning With ChatGPT
An alternative approach involves a large autoregressive language model like GPT-3, GPT-4, or ChatGPT. Autoregressive language models are models estimating the probability of the next token (a word or part of a word) given all the preceding tokens. This allows them to generate credible texts and, if they have been trained at a sufficiently large scale, they can effectively perform NLP tasks even without training examples.
For a text classification task, we can create a “prompt” like below, add the text to classify, and ask an autoregressive language model to generate the next words. Hopefully, the next words will be exactly the name of one of the targeted classes.
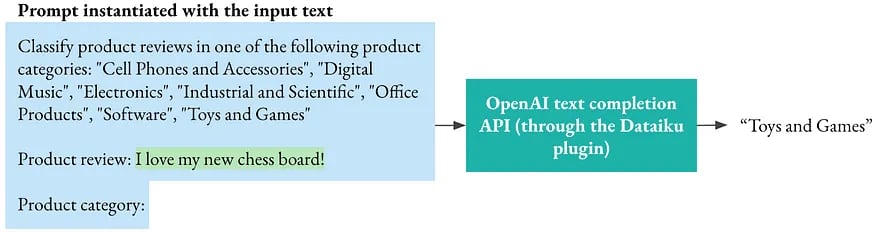
In practice, the language model may deviate from these instructions. For example, it may:
- Abstain from choosing one of the prescribed labels, e.g., “Unknown (not enough information to classify)”;
- Invent new labels, e.g., “Automotive Accessories”;
- Add unrequested details, e.g., “Industrial and Scientific (filament for 3D printing)” instead of just “Industrial and Scientific.”
The predicted labels need to be post-processed to avoid such invalid values.
Few-Shot Approaches
In-Context Learning With ChatGPT
In the few-shot setting, we assume that we only have a few training examples of each class. We can easily take advantage of them with autoregressive language models. For this we just need to include some of these examples directly in the prompt:

SetFit
SetFit is another approach proposed in 2022 for the few-shot setting. It is quite similar to the method described above which consisted in extracting dense representations with a pre-trained NLP model and training a shallow classifier on these representations. The only difference is that the pre-trained NLP model is fine-tuned with a contrastive loss.
How Do These Approaches Compare?
We tested these approaches on a small sample of the Amazon Reviews dataset with 1,400 reviews evenly distributed in seven product categories (“Cell Phones and Accessories,” “Digital Music,” “Electronics,” “Industrial and Scientific,” “Office Products,” “Software,” and “Toys and Games”). For instance, a review categorized as “Cell Phones and Accessories” is:
Can’t say enough good things. Fits snugly and provides great all round protection. Good grip but slides easily into pocket. Really adds to the quality feel of the Moto G 2014. I had the red and it looks sharp. Highly recommended.
We obtained the following results:
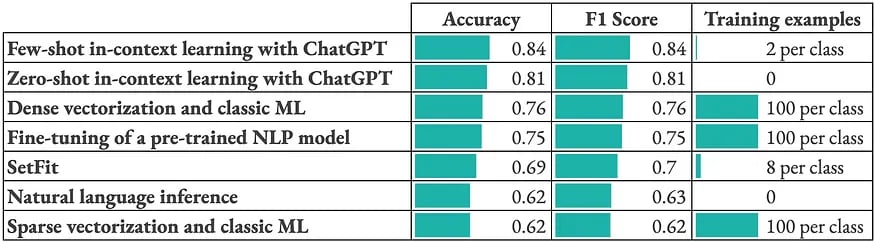
We did not make particular efforts to optimize the hyper-parameters and it is just one small dataset. We should then not derive strong general conclusions from these results. We can still note that:
- ChatGPT and more generally few-shot and zero-shot approaches perform remarkably well given the limited number of training examples. They certainly benefited from the fact that this text classification task does not require domain-specific knowledge.
- Sentence embeddings obtained from a frozen text encoder approximately yields the same predictive performance as a fine-tuned model. This is probably due to the limited hyper-parameter optimization.
- Beyond predictive performance, other criteria and constraints should be taken into account to assess these approaches. For example, leveraging ChatGPT requires an internet connection and the use of a third-party API whereas more expertise and computational resources are needed to fine-tune a self-hosted model.
Implementing Text Classification in Dataiku
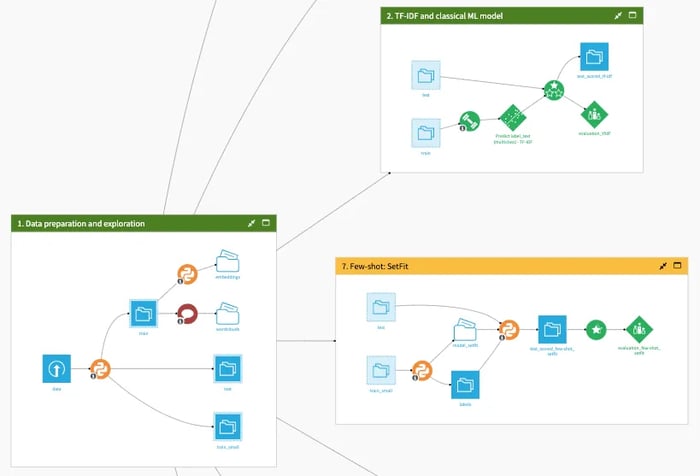
A Dataiku project on the Dataiku gallery shows how to easily implement these text classification techniques. Four of them can be used entirely through the visual user interface, without code. Beyond training and evaluating the various approaches, the project also illustrates:
- How to explore the dataset by identifying the most common words per class or visualizing training examples;
- How to implement the fine-tuning approach with MLFlow;
- How to compare the results of the various models;
- How to interactively score texts, identify the most influential words, and visualize misclassified examples.
This project can be downloaded and reused with your own data.
Conclusion
Whenever we face a text classification task, we can rely on a rich toolbox of powerful text classification techniques. We can choose the most appropriate method depending on the circumstances of the use case, such as the quantity of training examples, the domain, the resources available, and the targeted predictive performance.
Dataiku enables data professionals and business stakeholders to quickly implement these various approaches and also to cover all steps of a text classification project, from data exploration to a user interface incorporating our model’s predictions.
Thank you to Caroline Boudier and Nathan Bry for their contributions to the Dataiku demo project.