




{kind=link}
Entity resolution, also known as record linkage, is a critical step in many data workflows. It involves identifying and matching records that refer to the same entity across different datasets. This task is challenging when names, formats, or structures differ, and requires a blend of automation and domain expertise.
Large language models (LLMs) are increasingly being explored to tackle entity resolution problems more intelligently. However, in this article, we focus on a more transparent and accessible approach, combining rule-based preprocessing, fuzzy joins, and human validation. This allows us to introduce key practical aspects of entity resolution (human validation, output structure, usage for data enrichment) and to highlight the limits of such approaches, revealing opportunities for more advanced techniques like LLMs to step in.
An example area of application is ESG (Environmental, Social, and Governance) analytics, where organizations rely on a combination of internal and third-party data to measure their value chain’s externalities to strategically remedy them and comply with regulatory obligations. The parameters of this exercise look different depending on the value chain type.
- Manufacturers and retail businesses' value chain analysis typically surfaces entity resolution challenges when enriching internal supplier data with external data on suppliers' physical, transitional, and reputational climate risk exposure.
- Banks’ ESG analytics teams must measure their activity’s financed emissions to support their investment strategy’s alignment with the banks’ environmental objectives. Entity resolution challenges must be transparently and explainably overcome when combining different levels of customer entity denominations with third-party ESG data.
In this article, we explore how Dataiku was used to create an entity resolution tool for matching company records from internal and external datasets. We describe the problem, outline the solution, demonstrate validation interfaces, and explain how the results support data enrichment.
The project we created can be accessed on the Dataiku Gallery, a public, read-only instance of Dataiku. Throughout the article, links to the project's key datasets and recipes (aka data transformation operations) are provided.
Tackling the Entity Resolution Problem
In our use case, we wanted to enrich internal data on 2,001 companies with sustainability data from an external provider containing 9,895 companies. The challenge? Company names between datasets were often inconsistent. For instance:
- CRM: "Julius Baer"
- External Provider: "Bank Julius Bär & Co. AG"
Such discrepancies made exact matches unfeasible. The solution required a combination of name preprocessing, fuzzy matching, and human validation to ensure high accuracy.
Below, you can see examples of records from both datasets for companies in Switzerland’s financial services industry.


The solution aims to provide a matching table with one column for the company identifier used by the CRM and another for the one used by the external provider.

Automated Matching
Step 1: Preprocessing Names
To improve match accuracy, we standardized company names (e.g., transforming "Mercedes-Benz Group AG" into "mercedes benz group").

We used the following steps:
- Lowercase Conversion: All text was converted to lowercase ASCII.
- Removing Special Characters: Punctuation and special characters were stripped.
- Omitting Business Structure Acronyms: Acronyms like “Inc.” or “AG” were removed using a list of acronyms stored in an editable dataset.
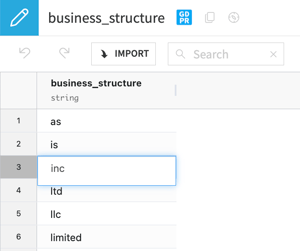
- Trimming Whitespace: Leading and trailing whitespace was removed.
This preprocessing ensured a consistent format for comparisons. Detailed steps can be found in the compute entities prepared recipe.
Step 2: Fuzzy Matching
We applied a fuzzy join to identify matches where the textual distance was below a defined threshold. Here's how it worked:
1. Left Join: Internal CRM names were compared to external provider names based on textual distance (computed by the “Damerau-Levenshtein” algorithm, as shown in the screenshot below). Pairs with less than 20% distance between names and the same Country/Industry were kept. This resulted in 2,146 rows, which shows that a few entities had multiple matches.

2. Select Closest Match: For entities with multiple matches, only the closest one was kept. This was achieved by Grouping by ID and computing the first matched entity by distance.
This resulted in a dataset with the same number of rows as the CRM data (2,001). The fuzzy join computed distance values as percentages, and we turned them into Confidence values by taking 1 minus the distance (values are between 0 and 100%, the latter corresponding to a perfect match), which we think is more intuitive for human reviewers to work with.

Notice that we chose to identify matched entities by their IDs and not their names, for our matching table to be robust to potential adjustments in company names in the external dataset.
Step 3: Categorizing Matches
We categorized entities of our internal dataset into:
- Perfect Matches: Confident matches requiring no further action (836 rows). The number of such matches depends on the name preprocessing algorithm.
- Automatically Validated Matches: Matches with a distance smaller than 10% (13 rows). Note that the following row counts also depend on this threshold.
- Uncertain Matches: Moderate-confidence matches requiring human review (63 rows). This count also depends on the threshold used in the Fuzzy Join.
- Missing Matches: Entities with no matches found (1,089 rows).
These categories were split into separate datasets for further analysis and validation.
The flow pipeline below illustrates the whole process described above:
 Results
Results
Automated matching successfully identified connections like:
- "Walgreens" ↔ "Walgreen Co."
- "Fairfax Financial Hldgs" ↔ "Fairfax Financial Holdings Ltd."
However, challenges remain:
- Missing Matches:
- "Paypal" should have been matched to "PayPal Holdings Inc." This could be addressed by implementing rules to deal with terms such as "holding(s)".
- "ING" should have been matched to "ING Bank N.V." This could be fixed by adding "nv" to business structures.
- Acronyms would be harder to solve, for example: "Silicon Valley Bank Financial Group" is "SVB Financial Group" in the external dataset, and "OCBC Singapore" is "Oversea-Chinese Banking Corp Ltd".
- Errors in Uncertain Matches:
- "Progressive Insurance" ↔ "Protective Insurance Corp."
- “Tokyo Electric Power” ↔ “Tohoku Electric Power Co., Inc”
Such cases highlight the importance of domain expertise and human review in the process. Advanced techniques, such as large language models, could further reduce errors, but human validation will remain essential.
Validation and Matching Interfaces
Streamlining Human Review
Using Dataiku’s Visual Edit plugin, we deployed two no-code web interfaces to involve domain experts, based on the Uncertain Matches and Missing Matches datasets. One is used to validate the machine's work, and the other is used to do the work that the machine couldn’t do, i.e., to find missing matches. (The links point to webapps hosted on the Dataiku Gallery; please note that the Gallery is read-only and therefore the interfaces don’t allow editing data.)

Features and Functionality
- No-Code Setup. The settings of the validation webapp shown in the screenshot above can be found here.
- Special Validation Behavior: Checkboxes in the validation column save more than just the information that a row is valid: they also save the actual values that were validated (here, the values in Matched Entity).
- Data Grouping and Filtering: The data is grouped by country and industry for easy navigation. It can also be filtered using the input widgets below the column names.
- The list of all available options can be provided as a Dataiku dataset of any size (here, 9,895 options for Matched Entity are found in the dataset of External Provider Companies).
- A label column can show a human-readable label for each option; here, this is used to show the names of companies instead of their IDs.
- Lookup columns provide additional information about each option; here, they show the company's country and industry.
- Search functionality is available: start typing, and only options whose label starts with the search term will be shown.
With the Audit Trail:
- All actions made in web interfaces powered by Visual Edit are automatically logged in an editlog dataset (see example).
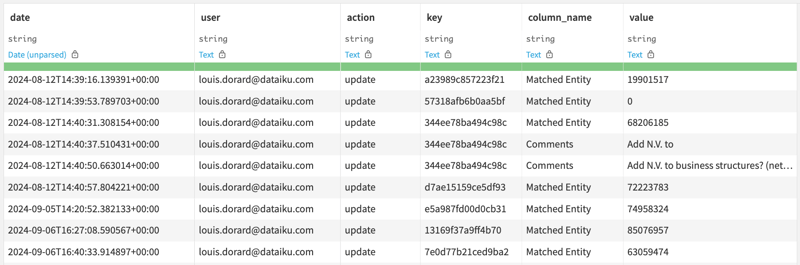
- The editlog provides accountability for errors and helps trace whether they arose from an incorrect configuration of the automated matching pipeline or from a manual override.
- This is particularly important in the context of ESG reporting; if a matching error connects a company to the wrong entity's data (e.g., linking "Acme Inc." in the U.S. to "Acme Ltd." in the U.K.), it may result in inaccurate emissions reports or flawed ESG scores.
- When deploying to production, this editlog can be made tamper-proof by configuring it to be an append-only database table, whose date values are set by the database as the date/time of the append.
Integrating Into the Pipeline
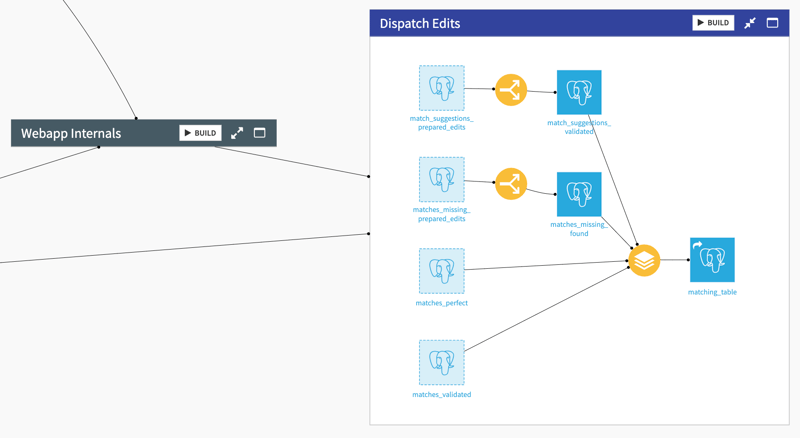
In the final “Dispatch Edits” flow zone, validations and edits made in the web interfaces are fed into the data pipeline to create the final matching table:
- Each of the 2 editlog datasets is transformed into an edits dataset which contains the rows and columns that were edited in the interface. This uses the "replay edits" recipe which Visual Edit automatically provides.
- Rows that were automatically or manually validated, or for which a match was found manually, make their way into the matching table. As initially specified, the matching table links CRM company IDs with external provider IDs.
Data Enrichment and ESG Analytics
We recommend implementing ESG analytics in separate projects, using the matching table as a bridge to connect internal data with an enrichment dataset on sustainability provided by an external provider.
In Dataiku, this enrichment can be done with a three-way left join recipe, where the ID column matches identifiers used in the internal dataset, and ID_ext matches identifiers used in the enrichment dataset. We prefer to avoid updating source data (e.g. updating company names in the internal dataset so that they match those of the external provider), and we consider the matching table as a new source of data. This way, we have the flexibility to un-resolve if a matching error was made, while keeping a history of the error and its fix via the editlog.
The enriched dataset can be used to build sustainability analytics and dashboards. We recommend centralizing dashboards and datasets from both projects in a single Dataiku Workspace for easy access by all stakeholders:

Strategic Takeaways for Data Leaders
This simple project demonstrated how Dataiku accelerates data workflows such as entity resolution by combining automation with domain expertise:
- Automate Entity Matching: Preprocessing and fuzzy joins drastically reduce manual work.
- Enable Human Expertise: No-code interfaces make it easy to involve domain experts to validate and enhance matching results.
- Enrich and Report: Outputs from entity resolution power data enrichment, analytics, and reporting.
This is achieved thanks to a no-code, transparent environment:
- The data pipelines are easy to understand thanks to visual representations.
- Intermediate results are validated and corrected via intuitive interfaces.
- Audit logs provide full traceability of who validated what, and how and when reports were generated.
While our example focused on using entity resolution to enrich company data with external sustainability information for ESG reporting and compliance, its applications extend far beyond this scenario. For instance:
- Enrich companies, products, or persons with any external data, or with internal data coming from different systems.
- Deduplicate records within the same system.
You can download the example project here and import it as a new project on your Dataiku instance (if you don’t have one, free trials are available on Dataiku Cloud). You’ll find more information on how to adapt it to your own data and on how to use it in practice in the project’s Wiki.