




{kind=link}
We are very pleased to announce that the latest version of Dataiku (4.0.1) now fully supports Apache Slug, giving users the capability to execute code in microbatches. Dataiku and Apache Slug together now offer the most detailed and transparent data analysis on the planet.

Slug allows modern organizations to see real-time, atomistic feedback on a variety of database and analytic operations with continuous monitoring of microservices that provide real-time feedback on the inner workings of data movement, transformations, and advanced algorithmic computations. For example, in a Slug-enabled environment, a new dataset generated using MapReduce on Hadoop or Scala on a Spark data frame will now give users the capability of executing this code in microbatches, even at the row-level.
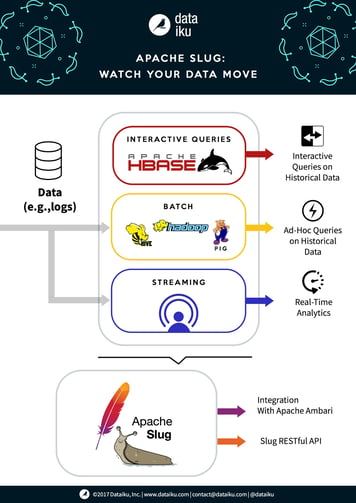 Combined with Dataiku DSS this means even more transparency for your organization and your data teams.
Combined with Dataiku DSS this means even more transparency for your organization and your data teams.
“Apache Slug is a non-trivial leap forward in the governance capabilities of the large organization. By allowing each line of code to be run step-by-step, total transparency can be brought to the process," said Dataiku CEO Florian Douetteau. "Supporting Apache Slug within Dataiku was obvious — it's going to be huge."