




{kind=link}
Automated machine learning (AutoML) is a concept that has resonated with many data scientists. Essentially, it means taking as many of the tedious, repetitive tasks associated with data projects (such as analyzing data, tuning parameters, selecting models etc.) and making them, well, automated. The promise of AutoML is that it will free up a lot of time that could be better used on more creative and valuable work.

AutoML runs into some real-life obstacles because no two data science projects are the same. An over-automated setup takes the data scientist out of the pilot’s seat by denying the very same creativity that makes them so valuable.
With our new release, Dataiku 4.1, we propose a set of tools that automate repetitive tasks within Dataiku while allowing for as much customization as possible. It’s this versatility that lets data scientists drive their own AutoML.
Data Exploration and Analysis
If you’ve already used Dataiku, you’re familiar with the Flow, which is how Dataiku organizes all data projects. The flow lays out datasets, transformations, and models in a way that is not only easy to understand but also easy to replicate. You can copy and paste your preparation steps — using both code and/or the visual interface — and apply these across as many different analyses as you’d like.
Even when you just look at a dataset, Dataiku displays some automatically generated insights, such as the type of data and a histogram of a sample of data in a field. If you haven’t seen this in action, click here to bring up a Dataiku dataset in your browser (no download or sign-in necessary).
You can also schedule tasks to be run regularly, and scenarios let you monitor projects remotely.
Automated Model Competition
Once you have your data prepared, machine learning can be a laborious process of training and testing one model after another, often without knowing how long each model will take to train and test. With Dataiku 4.1, though, line up as many models as you would like in the starting blocks and watch them go. Save time and resources by choosing winners and losers before training is complete. All major open-source libraries are at your disposal — combine them into ensembles, set parameters, and define your own metrics.
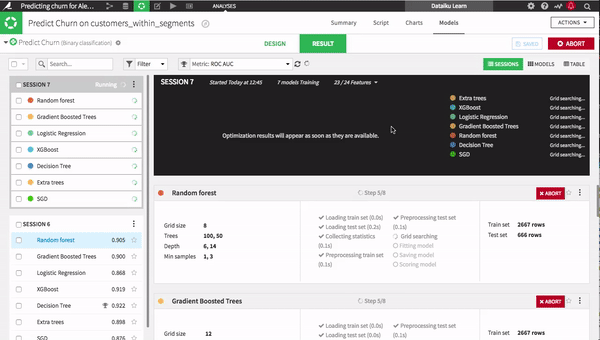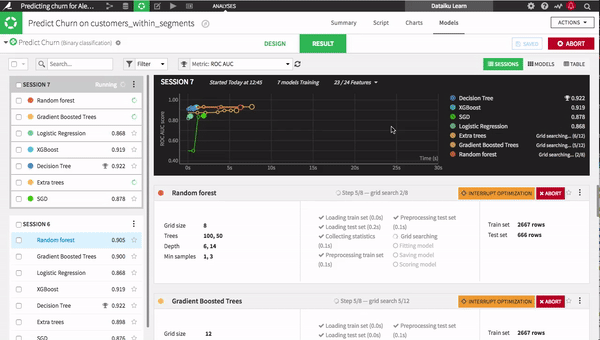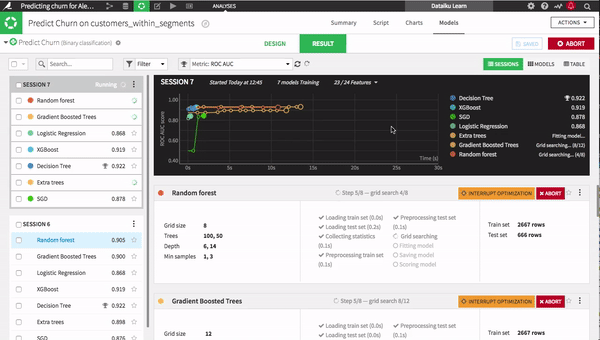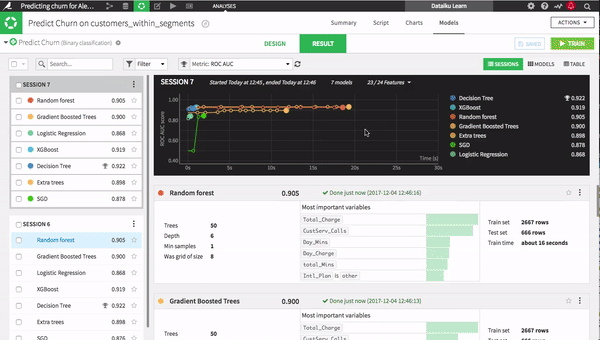
One major advantage of this feature is that you can set the maximum training duration to make sure you deliver the best models while meeting important deadlines.
Versatile Deployment to Production
The real value of a data project comes when it is deployed to production. Dataiku 4.1 introduces a new API node (which we’ll get into more detail in another blog post) that scores Dataiku-created, Python, and R models, and runs Python and R functions as well as parameterized SQL queries. Entire projects can be deployed into production via bundling, so you can set up checks and metrics to retrain and redeploy your models automatically. These models in production can also be managed with scenarios and scheduled with automated tasks so that you can control how these models run and when to adjust or replace them.