




{kind=link}
Organizations accumulate vast amounts of key information, much of which is locked away in documents. These documents — whether they are reports, contracts, invoices, or emails — are typically designed for human consumption, making them difficult to process automatically. Fortunately, Document AI, the subfield of AI focused on documents, is making rapid and significant progress. In this post, we offer a glimpse into the possibilities offered by modern Document AI. More specifically, we:
- Clarify the scope of Document AI;
- Present its main approaches;
- Illustrate how key Document AI tasks can be concretely performed;
- Introduce a Dataiku sample project that implements most of the techniques discussed.
Please note that this post does not cover the creation of question-answering systems over multi-page documents since a previous article of Data From the Trenches already covers this topic.
What Is Document AI?
Document AI, or Document Understanding, refers to automatically analyzing scanned or natively digital documents in order to categorize them or extract information from them. Some of the key Document AI tasks are:
- Optical Character Recognition (OCR): The conversion of the text present in images into machine-encoded text;.
- Layout Analysis: The analysis of the structure of a document, notably the detection and classification of elements like paragraphs, headings, tables, and images.
- Document Classification: The categorization of documents into predefined classes (e.g., forms, invoices, emails) based on their content, such as invoices, forms, or emails.
- Visual Question Answering: A task where a model answers questions based on the visual content of a document.
- Key Information Extraction: The process of extracting specific structured data (like names, dates, or price) from unstructured documents.
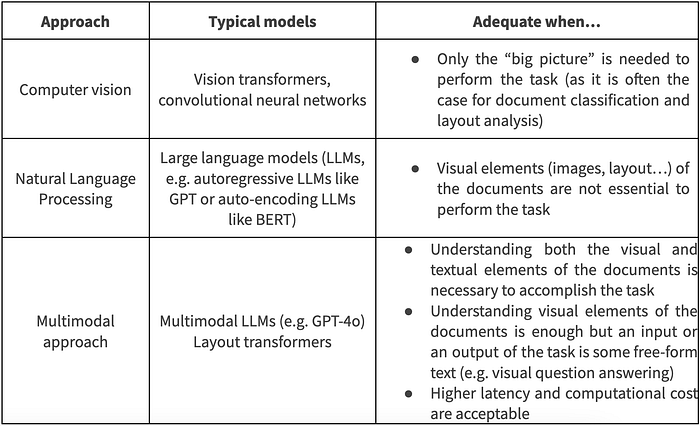
Handling documents is challenging for three main reasons: they generally combine text and images (e.g., diagrams, charts); their structure is often implicit and only suggested through their layouts; and they come in a variety of formats (e.g., layout, font family, font size). To overcome these obstacles, Document AI takes advantage of methods from both computer vision and natural language processing, alternatively seeing documents as just images, just texts, or combinations of both.
Layout Analysis
In this section and the following ones, we illustrate with some examples how Document AI tasks can be performed with open source packages, open weight models, or proprietary API-based LLMs. We first start with layout analysis, which is an important prerequisite to receiving meaningful OCR results from documents with non-trivial layouts.
Current approaches for layout analysis rely on computer vision models fine-tuned for object detection specifically in documents. Typical classes are “title”, “text”, “page header”, “section header”, etc. For example, the unstructured Python library makes several of these models available and easy to use, along with other features to parse and process various document formats.
OCR
When it comes to OCR, a straightforward approach is to use a specialized deep learning model such as the recently published open weight transformer model GOT or the LSTM models embedded in the well-known Tesseract open source library. These models are lightweight, fast, and effective.
However, their performance depends on the practical circumstances of the use case. Whether they perform well for certain languages and for both handwritten and printed text depends on their training dataset. Tesseract is quite ineffective on handwritten documents for instance. Furthermore, image pre-processing steps may be required, such as:
- Isolating the various text boxes in the document with layout analysis.
- Correcting the text orientation with the Hough transform;
- Removing visual noise (i.e., details that are irrelevant for the task at hand);
- Adjusting the scale, brightness, and contrast of the document.
The recent emergence of powerful multimodal LLMs (M-LLMs) offers an alternative to these specialized OCR models. With M-LLMs like GPT-4o or an open-weight model like InternVL, we can simply include the target image in the prompt and ask the model to extract its text content. The level of performance varies with the context of the use case as with specialized models but it is generally very strong.
However, M-LLMs sometimes exhibit two unwanted behaviors. First, they can add their own comments, such as “The text in the image is…”, to the text extracted from the document. Second, they may correct some words deemed to be misspelled in the original document or even “hallucinate” some content. Both of these problems may require adjusting the prompt or post-processing the LLM output.

Document Classification
M-LLMs, e.g., Qwen2-VL or GPT-4o, are also strong options to classify documents in a predetermined list of categories (e.g., article, email, letter, form). In this case, the prompt would include the instruction to classify the document, the list of classes, the document page to classify, and potentially few-shot examples (i.e., some document pages and their ground-truth labels). Since we expect only one of the specified classes, a good practice is to use structured text generation techniques, such as function calling or structured outputs, to mitigate or cancel the risk of an invalid answer.
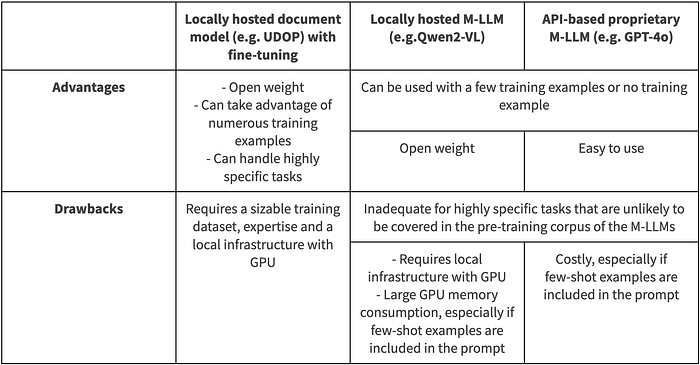
If a sizable training dataset is available, it is also possible to fine-tune a model. UDOP (Universal Document Processing), an open-weight model, is a strong candidate for Document AI tasks. UDOP uses an OCR engine (Tesseract by default) and processes text, layout, and images as inputs. It is a versatile model, capable of performing various tasks such as document classification, layout analysis, visual question answering, key information extraction, and document generation. It is usually better to use parameter-efficient fine-tuning (PEFT) techniques such as LoRA, especially if the training dataset is relatively small.
Visual Question Answering
Here, we restrict ourselves to questions whose answers come from a single page provided along with the question. Question-answering systems which cover whole documents generally require a multimodal Retrieval-Augmented Generation (RAG) approach which is already addressed in a previous blog post.
M-LLMs like Qwen2-VL or GPT-4o are the method of choice for visual question-answering tasks, given the general nature of the potential questions, the need to generate some text content and the need to take into account both visual and textual elements of the page. They may be fine-tuned if the domain at hand is very specific but recent M-LLMs generally yield good answers, even in a zero-shot setting.
Evaluating the quality of question-answering systems is especially challenging because equally valid answers can be phrased in very different ways and the best approach is generally to use an LLM-as-a-judge technique, i.e., to ask an LLM to assess the generated answers and compare them to ground-truth answers when available.
Key Information Extraction
In a key information extraction task, we are given a document page, e.g., the scan of a receipt, and we try to extract specific and predetermined pieces of information, e.g., the name and address of the company, the date of the receipt, the amount of the receipt, etc. M-LLMs (e.g., Qwen2-VL or GPT-4o again) are also strong candidates for this task, thanks to their text generation capabilities which are useful when the answer is quite open-ended like in this task. Fine-tuning can help but is often not necessary.
In this context, M-LLMs are typically prompted to generate a JSON object whose properties correspond exactly to the target fields. Even more so than for document classification, structured text generation techniques like function calling or structured outputs are essential to comply with the expected format.
Document AI in Dataiku
Dataiku users can start exploring the various techniques mentioned above thanks to a public and reusable sample project of the Dataiku project gallery. In particular, this project shows how to:
- Perform layout analysis and OCR with Unstructured, InternVL and GPT-4o;
- Fine-tune UDOP or leverage GPT-4o or Qwen2-VL for document classification;
- Answer questions based on documents with GPT-4o or Qwen2-VL and evaluate the corresponding answers;
- Extract specific fields from documents with GPT-4o or Qwen2-VL;
- Expose these capabilities in a simple web application.
Conclusion
Recent progress in Document AI enables the automation of an increasingly wide range of tasks. Use cases that would have been particularly challenging a few years ago become achievable. In this context, M-LLMs distinguish themselves with their versatility, user-friendliness, zero-shot or few-shot capabilities, and high performance and will likely play an increasingly important role in this domain. Still, some alternatives remain valid, especially for real-time use cases or in low-resource environments when the computational costs of M-LLMs are excessive.