




This is my friend, Louis Takumi. He is French-Japanese and one of the newest Dataikers who has joined the company this year. He is the very first data scientist who will work in our soon-to-open Tokyo office — but what makes him really stand out is his passion for ramen. When he signed the contract to officially come on board, he asked me, “Makoto, which ramen restaurant do you recommend in Tokyo?”


I replied, “I like Ramen Wakura in Shinjuku city, they have nice lightly-flavored tonkotsu (pork bone) soup.”
“Oh but I prefer ramen with heavy and rich soup,” said Louis, “like Naritake Ramen in Paris, you know.”
Naritake Ramen is famous for its broth full of flavors oscillating between soybeans, condiments, and the taste of pork. Of course I have tried it, but it was just not my type.

When visiting Japan, a lot of tourists are surprised by the variety of different ramen flavors. Even for the soup, there is tonkotsu, miso, soy sauce, sesame, dried sardines, curry, milk — the list goes on and on. What this means is that the preferred flavor differs a lot among individuals. If you are planning to visit Japan, you should never trust what your guide book says. On top of that, you don’t want to post photos of your ramen on Instagram, only to find tons of similar photos already posted by other tourists, right?
So, what is the best way to recommend the best ramen restaurant in Tokyo for Louis? Well, let’s use Natural Language Processing (NLP) — follow along in this blog post to see how we did it!
Where Do the Japanese Talk About Ramen?
In Japan, there is a website called Tabelog. It is something similar to Tripadvisor, and it has around 34.8 million reviews of about 900,000 restaurants all over Japan. It is a monstrous review site with 100 million monthly users. Based on these word-of-mouth reviews, I used Dataiku to create a recommendation model of ramen shops for non-Japanese people.
When you make a project in Dataiku, you can package it as a visual application. Below you can see my final application for Louis. This is how it works: He types the URL of Naritake Ramen on Tripadvisor and clicks the green button. The app returns the name of the best ramen restaurant in Tokyo.
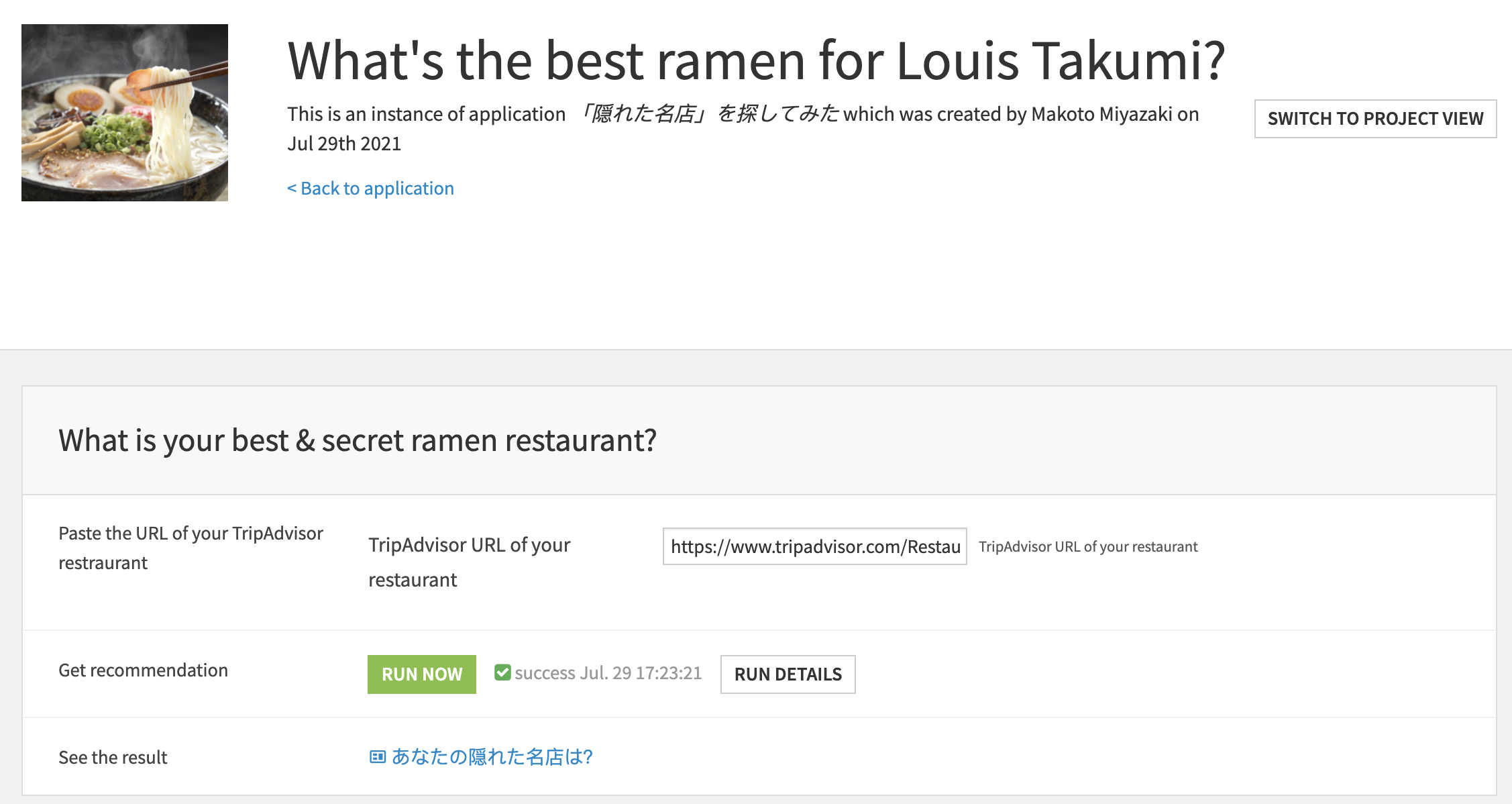
What restaurant did my app recommend to him? Well, read through this blog and you will see in the end!
The Menu
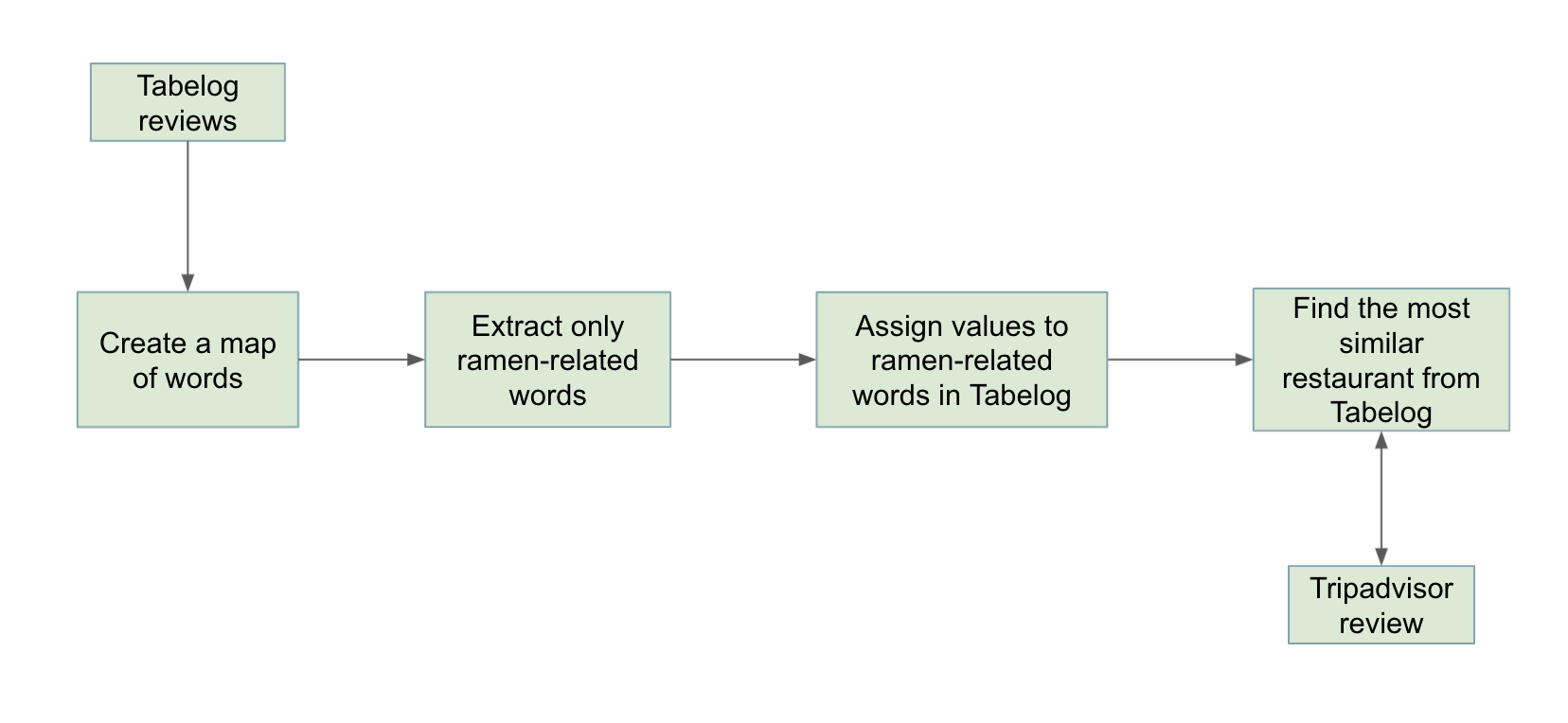
The overall pipeline on the back of my app goes like this: The app scrapes the reviews of the Tripadvisor page that the user enters. Then, it compares the Tripadvisor reviews with the 15,000 Tabelog reviews from 730 ramen restaurants in Tokyo. Lastly, a Tabelog ramen restaurant with the highest similarity is recommended to you.
But the real pipeline is a bit more complicated. Let's take a closer look.
- The scraped Tabelog review texts are split into words.
- Using the word2vec model, words are embedded into a vector space in order to derive the relationships between each word.
- Words are clustered and only those that are related to ramen are kept; all the other words are dropped from the dataset.
- The Tripadvisor reviews are also processed in the same way after being translated into Japanese.
- The similarity values between the TripAdvisor reviews and those of the Tabelog reviews are calculated.
 Cleaning Reviews
Cleaning Reviews
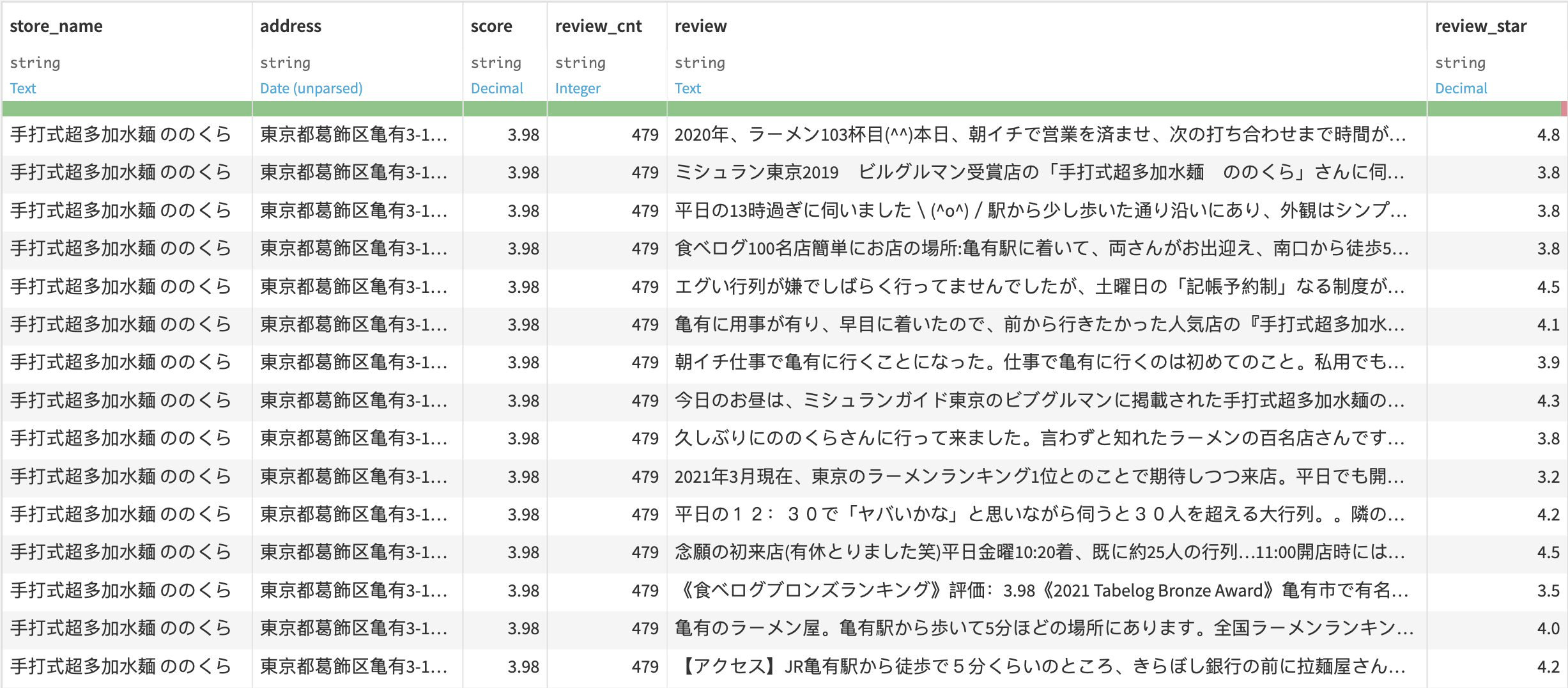
Above are the scraped raw review texts, but you cannot directly use them for analysis. NLP is all about removing extraneous words from the text, leaving only the necessary and meaningful words. It is no exaggeration to say that this preprocessing determines the quality of the recommendation engine.
In particular, Japanese reviews make extensive use of Kaomoji. Kaomoji is a popular Japanese emoticon style made up of brackets, carets, underscores, and many other symbols and are used to express emotion in texting and cyber communication. Unlike picturized emoticons, there are an infinite number of patterns, making them very difficult to remove.
Below is an example from one of the Tabelog reviews, with my lovely English translation.

If you are an engineer implementing NLP, you may want to hang your hat and hope to reincarnate in a world without Kaomojis. In order to clean an infinite number of Kaomoji patterns, I used regular expressions in a Python recipe and cleaned them up.
Wakachi-Gaki and Word2vec Modeling
The main difference between Japanese and English NLP is that there are no breaks between words in Japanese. Take a look at the sentence below.
I had a bowl of ramen today.
私は今日ラーメンを食べました。
They describe the same thing. Thanks to the spaces, English sentences are easy to separate into words. But what about the Japanese? Japanese is written using a mixture of three alphabets (hiragana, katakana, and kanji), so it is possible to guess where these words are split.

However, this division is not perfect. If we break this sentence down to its smallest elements, we get the following:

It is only when we get to this point that we are on the same starting point as English NLP. This process, which is unique to Japanese NLP, is called "wakachi-gaki (dividing into words)." There are a number of Python packages that can do the wakachi-gaki for you. I used one of the most commonly used one, MeCab. Warning: this requires a system-level installation.
After implementing wakachi-gaki with MeCab, I trained the word2vec model. I put the trained model in a folder on the Flow for later use.
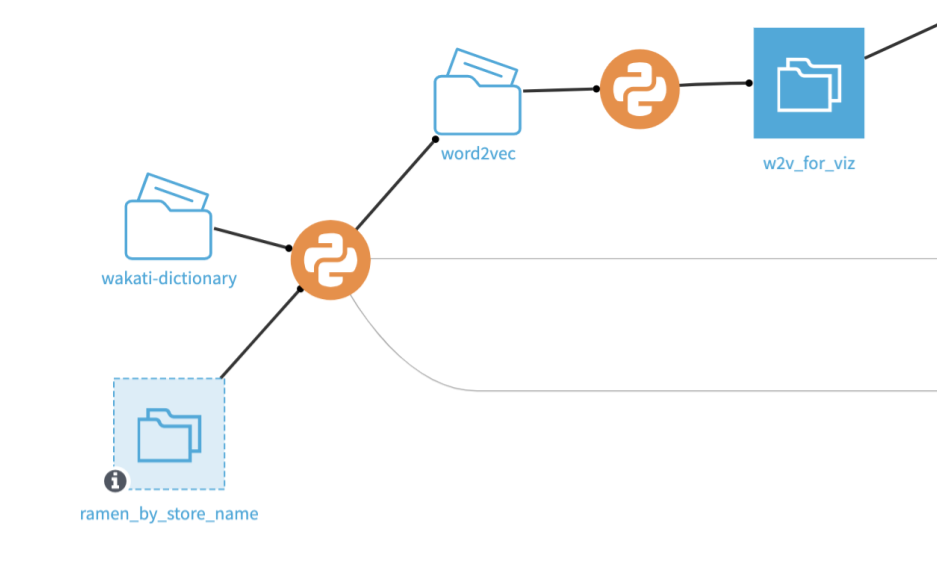
Training the word2vec model makes it possible to map each word into a vector space. Words in the review are not mere words, but can now be treated as objects with mathematical values. You can even measure the distance between each word. Words with a small distance are similar to each other and vise-versa.
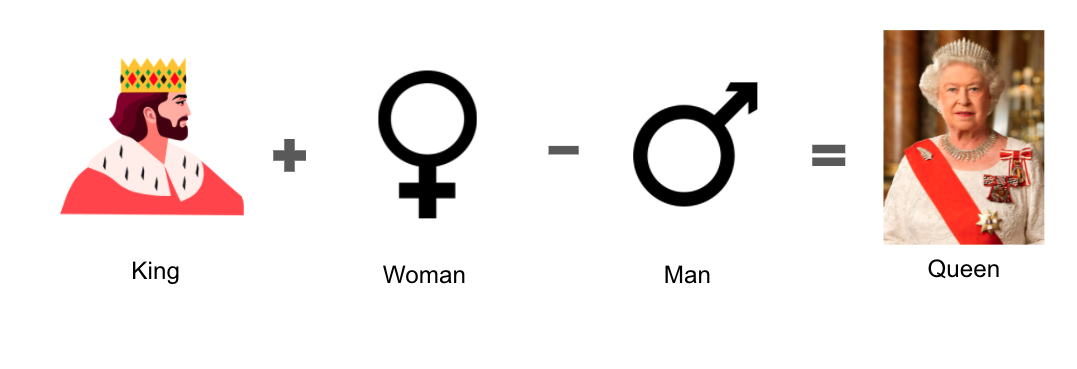
Furthermore, words can be added and subtracted. It is a well-known example that, when a word2vec model is trained on general text data such as Wikipedia, you can express a word “queen” with a formula like below:
Jumping Into the Universe of Ramen Words
However, if the model is trained on text data that consists of ramen reviews, something funny happens. For example, let's compute an addition below and see what the top results are:
“ramen” + “Sapporo” = ?

As a result, the words “Miso Ramen” came to the top. Indeed, Sapporo, a city in northern Japan, is famous for its miso ramen.
What about this? Ramen is a popular Japanese food, but it originally came from China. So what happens when you subtract ramen from Chinese food?
Chinese - ramen = ?
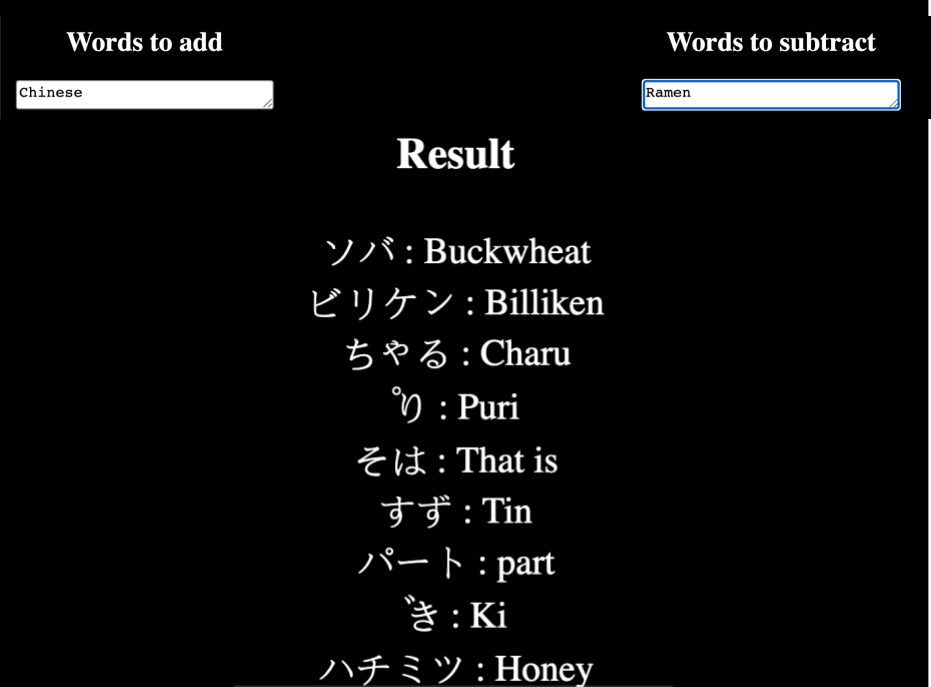
Buckwheat noodle, or Soba in Japanese, is a traditional Japanese noodle dish that has been around the country since before ramen was introduced from China. So what about this?
ramen shop + midnight - ramen = ?

It is interesting that words such as “last train,” “bar,” and “refrain from going out” appear at the top of the list. It seems like, after slurping their last drip of the soup at a ramen stand, people spend the rest of the night in a variety of ways.
Finally, what happens if vegetarian people try to eat ramen in Japan, notoriously known for its unfriendliness to vegetarians?
vegetarian + ramen = ?

Do Clustering to Focus on Ramen-Related Words
If you look carefully at reviews on Tripadvisor, Tabelog, or anything similar, you'll find that reviews are not always about food and restaurants. There are people who write about conversations with loved ones, those who quote the famous French poet Stéphane Mallarmé's "Salut" in their reviews of drinks, ones who write about how to impress the person you love with a meal, or tell the story of how they tried to pick up a waiter and failed spectacularly. If you simply want to find the ramen that fits your preference, you have to omit these irrelevant details from your data.
Clustering the words will help you identify groups of words that are irrelevant to your needs. Dataiku’s AutoML can do K-Means clustering with different numbers of clusters that you set. The best result I obtained was with four clusters.
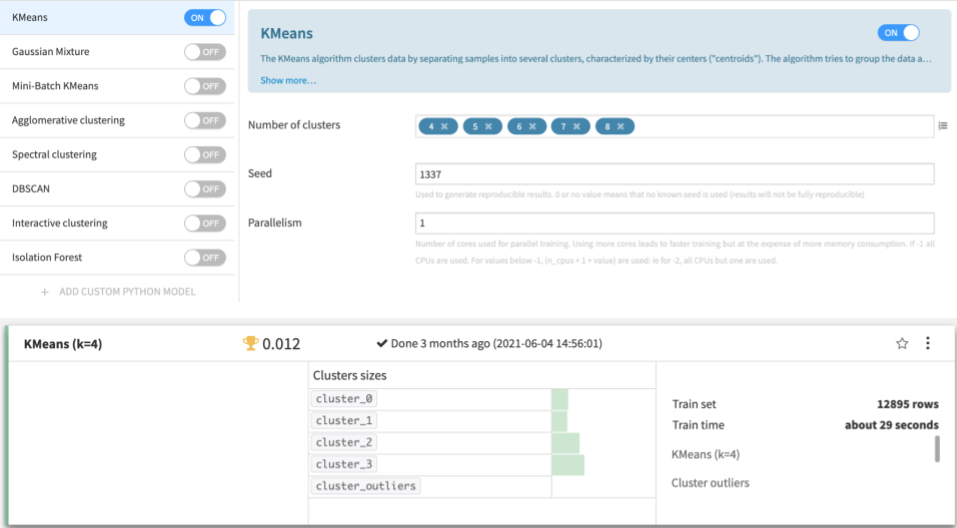
Clusters themselves do not have names. It is your task to look at the words in each of the four clusters and give them names. Like below, I named the clusters “interior,” “website & reviews,” “taste & ingredients,” and “location & appearance.”

Now I can finally focus on words belonging to the two clusters: “interior” and “taste & ingredients.” All other words will be excluded from the review. In this way, my application will find the restaurant that fits your favorite taste as well as the atmosphere of the restaurant. The clustering model created from the Tabelog is also applied to Tripadvisor reviews, again leaving out only the words for “interior” and “taste & ingredients.”
Measuring Similarity
I then used TF-IDF to score the words and narrow down the list to 40 words with top TF-IDF scores. Then, using the trained word2vec model once more, I converted the remaining words into a vector representation and measured the cosine similarity between the Tripadvisor and Tabelog reviews. The final dataset will look like the below with the similarity score:
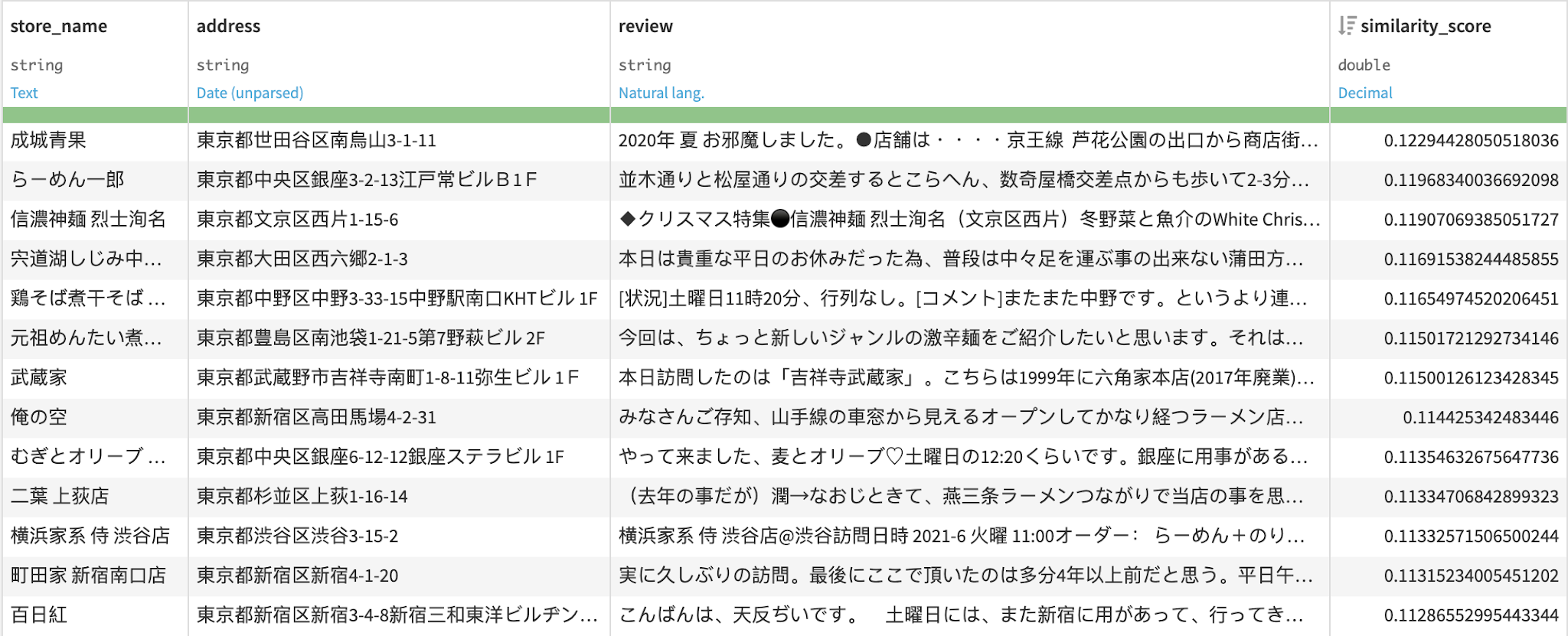
What Is the Best Ramen in Tokyo for Louis?
Now that my app finished running, Louis can finally find out what the best ramen restaurant is for him!
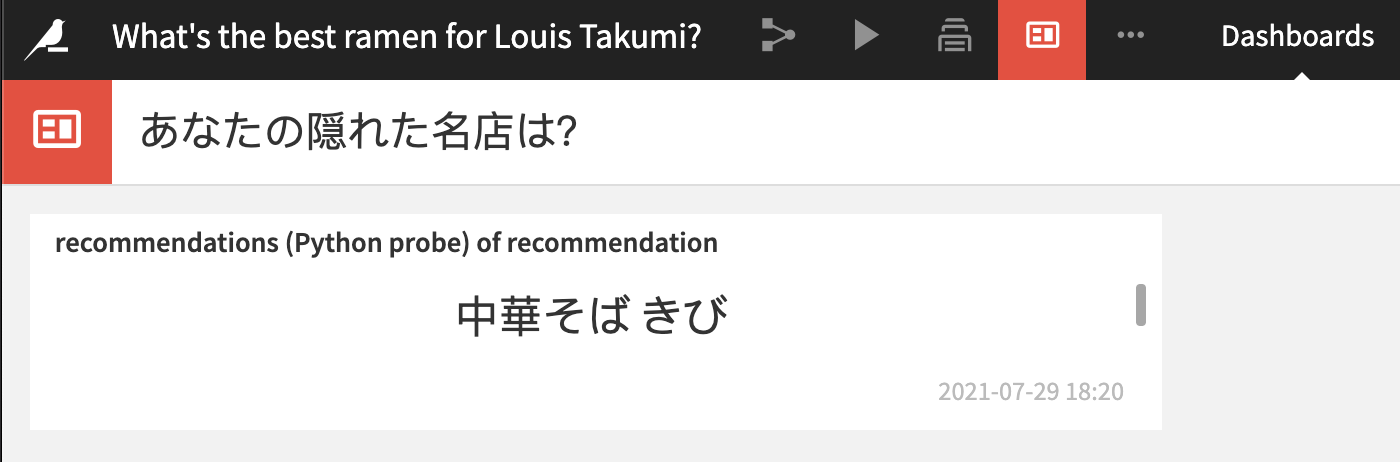
My app recommended a place called “Kibi,” a small restaurant that is situated in the west part of central Tokyo.
So let’s ask Louis, who actually went to try the ramen at this place to check the quality of my app! Louis, how was the ramen at Kibi? He said, “Makoto, the ramen was pretty good.”

"But...the soup was not as thick as the one at Naritake."

{kind=link}
Oh gosh, looks like I need to remove more Kaomojis from the dataset…
(#`皿´)クヤシイイイイ!!