




{kind=link}
A key challenge on the journey to Everyday AI will be figuring out how to balance model performance and interpretability stemming from the difference between black-box and white-box models. As organizations scale their data science, machine learning (ML), and AI efforts, they are bound to reach this impasse, learning when to prioritize white-box models over black-box ones (because there is a time and a place for those) and how to infuse explainability along the way.
Here’s why black-box models can be a challenge for business (and a legitimate concern):
- They lack explainability (both internally at an organization as well as externally to customers and regulators seeking explanations for why a decision was made)
- They create a “comprehension debt” that must be repaid over time via difficulty to sustain performance, unexpected effects like people gaming the system, or potential unfairness
- They can lead to technical debt over time, as the model must be more frequently reassessed and retrained as data drifts because it may rely on spurious and non-causal correlations that quickly vanish (which, in turn, drives up operating expenses)
- There are problems for all types of models (not just black-box ones) but things like spurious correlations are easier to detect with a white-box model
Now, to be sure, we aren’t saying to wholly ignore black-box models. These models — including deep learning algorithms — support so many new opportunities for technological advancement and provide such significant accuracy gains that doing so simply isn’t an option for organizations in this competitive marketplace. However, they can enforce certain AI practices to ensure black-box models are being developed in a more responsible, governed way.
Here, we’ll describe the trade-offs between white-box and black-box models, break down what these concepts really mean, and highlight the rise of explainable AI as a powerful mitigating force that enables modelers, regulators, and laypeople to have more trust and confidence in their models.
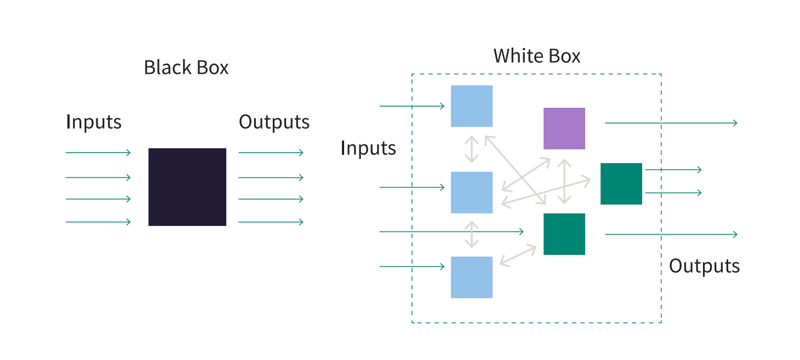
Take a Step Back: What Is a Black-Box Model Anyway?
We live in a world of black-box models and white-box models. On the one hand, white-box models have observable and understandable behaviors, features, and relationships between influencing variables and the output predictions (think: linear regressions and decision trees), but are often not as performant as black-box models (i.e., lower accuracy, but higher explainability). Essentially, the relationship between the data used to train the model and the model outcome is explainable.
Conversely, black-box models have unobservable input-output relationships and lack clarity around inner workings (think: a model that takes customer attributes as inputs and outputs a car insurance rate, without a discernible how). This is typical of deep learning and boosted/random forest models which model incredibly complex situations with high non-linearity and interactions between inputs.
Here, the relationship between the data and the model outcome is less explainable than a white-box model. There are no clear steps outlining why the model has made the decisions that it has (and the model description, parameters, and predictions don’t either), so it’s difficult to discern how it reached the outputs and predictions that it did.
In some situations, we may be comfortable with this tradeoff between model performance and explainability. For example, we might not care why an algorithm recommends a particular movie if it is a good match, but we do care why someone has been rejected for a credit card application.
Implementing an Explainable AI Strategy
Creating explainable, white-box models is a layered issue. It’s not just important for those behind the curtain developing the model (such as a data scientist), but for end users not involved in the model development (such as lines of business who need to understand the output and how it translates to other stakeholders in the company).
Don’t fret — there are ways to build models in a way that is collaborative and sustainable for the business. Enter: explainable AI. The rise of complex models over the last decide has led organizations to realize that there are consequences to AI that we don’t understand (that have real-world impacts), which, in turn, spurred many breakthroughs in the space, conferences dedicated to the topic, leaders in the field discussing it, and a need for tooling to understand and implement explainable AI at scale.
Explainable AI, sometimes abbreviated as XAI, is a set of capabilities and methods used to describe an AI model, its anticipated impact, and potential biases. Its objective is to address how black-box models reached their decisions and then make the model as interpretable as possible.
There are two main elements of explainability:
- Interpretability: Why did the model behave as it did?
- Transparency: How does the model work?
Ideally, every model — no matter the industry or use case — would be both explainable and transparent, so that, ultimately, teams trust the systems powered by these models, mitigating risk and enabling everyone (not just those involved) to understand how decisions were made. Examples where explainable and transparent models are useful include:
- Critical decisions (e.g., healthcare)
- Seldom made or non-routine decisions (e.g., M&A work)
- Stakeholder justification-required decisions (e.g., strategic business choices)
- High-touch human judgment decisions (e.g., portfolio manager-vetted investments)
- Situations where interactions matter more than outcomes (e.g., root cause analysis)
In the next section, we’ll provide tangible ways that organizations can accelerate their journey to explainable AI with Dataiku in order to give them more confidence in model development and deployment.
Do It With Dataiku
It’s critical for organizations to understand how their models make decisions because:
- It gives them the opportunity to further refine and improve their analyses.
- It makes it easier to explain to non-practitioners how the model uses the data to make decisions.
- Explainability can help practitioners avoid negative or unforeseen consequences of their models.
Dataiku helps organizations accomplish all three of these objectives by striking the optimal balance between interpretability and model performance. Dataiku’s all-in-one data science, ML, and AI platform is built for best practice methodology and governance throughout a model’s entire lifecycle.
It is important to note that the features outlined here are in fact model agnostic and work for both black-box and white-box models. They can enable organizations to effectively understand model outputs, increase trust, and eliminate bias.
Collaboration
Dataiku is an inclusive and collaborative platform that makes data and AI projects a team sport. By bringing the right people, processes, data, and technologies together in a transparent way, strategic decisions can be better made throughout the model lifecycle including tradeoffs between black-box and white-box models leading to greater understanding of, and trust in, model outputs. Specifically, Dataiku provides:
- A visual flow where everyone on the team can use common objects and visual language to describe the step-by-step approach to their data projects, documenting the entire process for future users
- An all-in-one platform where coders and non-coders can work on the same projects
- Discussion threads that allow teams to collaborate within the project framework, saving time and maintaining the history of the conversations and decisions as part of the project itself
- Wikis that preserve knowledge about the project for current and future users
Data Prep and Analysis
Dataiku offers:
- Data lineage, so you know where the data originated from
- Easy to use, transparent data transformation and cleaning to ensure data quality
- Data analysis to identify outliers and key insights about the data
- Business knowledge enrichment through plugins and business-meaning detection
- Version control of projects, providing traceability into all actions performed and the ability to revert changes
ML Models
Dataiku provides the freedom to approach the modeling process in Expert Mode or leverage AutoML to quickly and easily generate models using a variety of pre-canned white-box and black-box models, including logistic/ridge/lasso regression; decision trees; random forests; KGBoost; SGD; k-nearest neighbors; artificial neural networks; deep learning, and more, as well as the ability to import your own notebook-based custom algorithms. Here are some model-specific features designed to enhance explainability (and enable both data scientists and business stakeholders to understand the factors influencing model predictions):
- Partial dependence plots: This feature helps model creators understand complex models visually by surfacing relationships between a feature and the target. The plots are a post-hoc analysis that can be computed after a model is built.

- Disparate impact and subpopulation analysis: We know that models built with biased data will produce bias predictions. Disparate impact analysis in Dataiku measures whether a sensitive group receives a positive outcome at a rate close to that of the advantaged group. Further, Dataiku’s subpopulation analysis allows users to see results by group in order to weed out unintended model biases. Both analyses help to find groups of people who may be unfairly or differently treated by the model, which will help teams deliver more responsible and equitable outcomes.

- Model fairness: Before teams can prescribe a solution to model bias, they must dig deeper into how biased a model is, which can be done by measuring some fairness metrics. Dataiku’s model fairness plugin was designed to help accomplish this task. Depending on the individual use case, different metrics of fairness may need to be applied. The goal of the plugin is to show users — in a transparent way — several fairness metrics and the differences between them. From there, users can choose the one that best evaluates the fairness of the situation at hand.
- What-if analysis: Dataiku what-if analysis enables data scientists and analysts to check different input simulations and publish it for business users to view. As a result, they can build trust among business stakeholders as they see the results they generate in common scenarios and test new scenarios.

- Individual prediction explanations and reason codes: Individual prediction explanations enable users to explore the data and results at a row level. During scoring, prediction explanations can be returned as part of the response, fulfilling the need to have reason codes in regulated industries and providing additional information for analysis. Row-level interpretability helps data teams understand the decision logic behind a model’s specific predictions.
- Model document generator: This feature enables organizations to prove that they follow industry best practices to build their models. The generator (which has customizable templates) enables teams to create documentation associated with any trained model, automatically creating a .docx file that provides information about what the model does, how it was built, how it was tuned, and its performance.
This reduces the time needed to manually update a document after every minor change to keep it current. It also allows stakeholders outside of the data science team to clearly see the big picture — how the data was prepared, the features, the details of deployment, and so on — simultaneously creating a foolproof audit trail.
- Audit centralization and dispatch: Audit trails are important and having a central view is a requirement. Dataiku allows teams to centralize audit logs across. This includes API node query logs to complete the feedback loop (and a sound MLOps strategy).
Model Monitoring
Explainability is especially critical in model monitoring, because it begs the question of if the models are truly delivering value to the enterprise and aims to unpack if the benefits of the model outweigh the costs of developing and deploying it.
Monitoring ML models in production is an important, but often tedious task for everyone involved in the data lifecycle. Conventional model retraining strategies are often based on monitoring model metrics, but in many use cases, using a metric like AUC might not do the trick. This is especially true in cases where long periods of time pass before receiving feedback on the accuracy of the model’s predictions. Dataiku’s model drift monitoring shortens the feedback loop and allows users to examine if new data waiting to be scored has drifted from the training data.
Further, Dataiku’s model data compliance plugin can be used to detect data drift from the model training data, but also just to check that data within pipelines (with or without an ML component) isn’t shifting too far from a predetermined tolerance threshold.
Putting It All Together
Making the shift from black-box AI to transparent, explainable AI might seem attainable in theory, but is harder to actually implement. For enterprise-scale data science projects, data scientists and other model developers need to be able to explain not only how their models behave, but also the key variables or driving factors behind the predictions. Explainability, therefore, is not only necessary in order for the data team to monitor their own KPIs and reuse pieces of that model in a future project, but is necessary for explaining insights and actions for business users who weren’t involved in the development process.
Building white-box models is easier with Dataiku, enabling organizations to take accountability for their AI systems (and, in turn, their predictions and decisions). Further, it helps ensure compliance with both regulations in their industry and for audits, and, most importantly, can reduce harm and negative impacts from biased algorithms and black-box models.