




{kind=link}
A data pipeline is a series of steps that your data moves through. The output of one step in the process becomes the input of the next. Data (typically raw data) goes in one side, goes through a series of steps, and then pops out the other end ready for use or already analyzed.

The steps of a data pipeline can include cleaning, transforming, merging, modeling, and more, in any combination. It seems simple; however, anyone that's ever worked with data knows that data pipelines can get highly complex. This blog post will simplify the process and show how you can build a data pipeline in Dataiku to help prep a dataset for analysis.
Common Data Cleaning Problems
While not a comprehensive list of problems I've encountered with datasets I've received, here are the most common:
- Missing data
- Multiple fields in a single column
- Non-unique column headers
- Non-standardized data: column headers, names, dates
- Extra white space around text
Let's see how we can clean these up.
Pipeline Overview
Here's what we're going to build using Dataiku:

For this example, I've created a fake dataset containing 10,000 records made to mimic a partial database dump of patient information for a healthcare provider. You can get the code to generate a similar dataset, or grab the dataset itself, and the Dataiku project I created on GitHub.
Alright. Let's clean up this data!
Pipeline Build-Out
First, create a new dataset and view the data. During this step, we aren't going to do any manipulation of the column names, only import and preview the dataset.
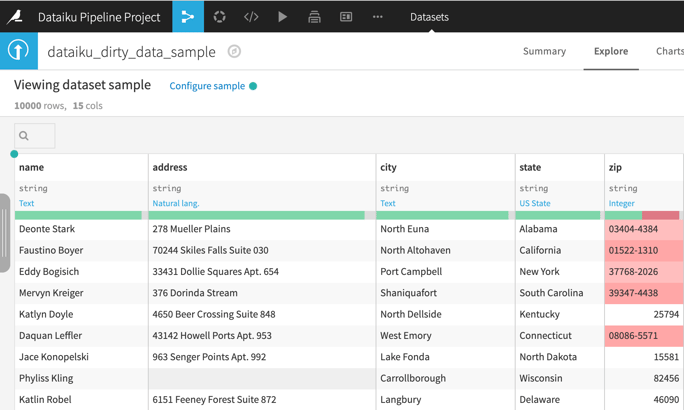
Next, create a new recipe to split the full name into first and last names and rename the columns. For the zip code field, change its meaning to Text, as we aren't going to do math on this field. The output of this step is a new dataset with the cleaned names.
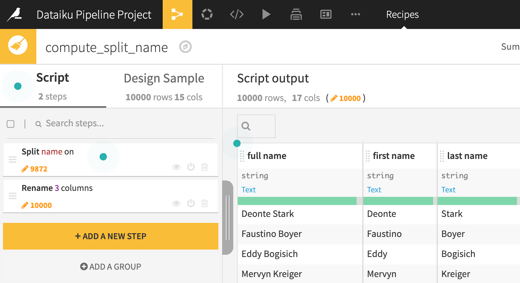
After that, clean up the home address fields. Do this by creating a new recipe for the cleaned names dataset and:
- Trim the address.
- Use regex to extract out the apartment or suite number.
- Rename all of the address columns.
- Replace the apartment or suite number in the original address field so that only the line one portion remains.
- Rename the rest of the fields.
Now turn your attention to the first phone column. This column has phone numbers in many formats. Extracting the parts of each format is beyond the scope of this post. For now, let's simply rename this column to home phone and remove what appears to be an erroneous extension. Do this by creating a preparation recipe that renames the column, and uses a regex to find and replace an extension.
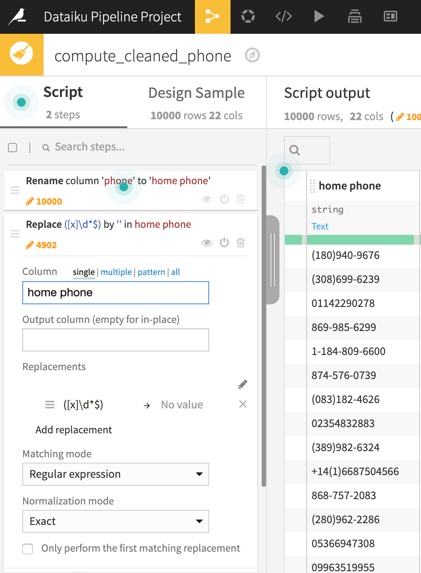
Great work so far! We're almost finished cleaning this dataset, so let's keep going.
With all of the home information cleaned, we can now finish by cleaning up the work information and the account creation date.
The fields for the work data are, perhaps not surprisingly, similar to the home information fields. This allows us to leverage the preparation scripts we've already created. Let's first clean up the work address.
View your current flow diagram and double-click on the script you created during the home address step. Under the actions menu in the top right, select Copy, and be sure to select the right input dataset and name the output:
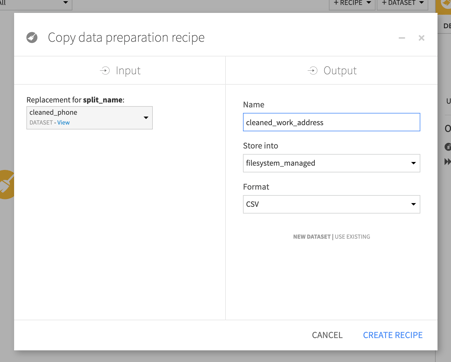
Now we have a complete copy of all the work we did for the home address. All that's left to do is to update all of the column names to apply our transformations to the work columns.
To clean up the work phone, do the same thing; however, this time, use the dataset you just created as the input, and create a new preparation script to operate on the cleaned work address dataset. In that recipe, we'll do the following:
- Extract the extension using regex and put it into its own column.
- Replace the found extension in the main phone number.
Only one more step to go! Let's clean up the account created on field.
Do that by going back to the flow view, selecting the cleaned work phone dataset and click on the Prepare icon on the right side menu. Name this final, cleaned dataset account_data.
Once you're on the Script page, scroll over so you can see the account created on field. Click on the column header, and from the drop down, click Parse date... in the Script section. This will cause Dataiku to automatically determine the date formats:
And we're done!
Summary
Phew! It took me longer to write this post than to perform the work. That's because Dataiku makes it easy to create data pipelines, especially for preparing data.
What we've created here is a very simple example of what can be accomplished. I suggest you take this a step further and cluster the data by attributes such as their city or state. If you had payment information, you could combine the two datasets, which could later be used to create a predictive model. There's also a lot of cool visualization stuff you could do as well.