




{kind=link}
As data becomes more available but also grows in size and is continuously more dense and unstructured — specifically in a context where more than just network logs are required to perform accurate anomaly detection and threat intelligence — the cybersecurity industry is aiming to introduce more automation into the process to provide security experts with actionable information for identifying patterns, threats, attackers, and more.
Automation implies being able to design, deploy, and monitor a data flow. It also means leveraging machine learning as often as possible and orchestrating it in what is now becoming the so-called MLOps standard.
Storage is getting cheaper and allows stakeholders to ingest and enrich their analyses with a myriad of valuable data sources (i.e., fraud, business units, social networks, and so on), making it attractive for Chief Information Security Officers (CISOs) to customize or build their own rules management solutions the way Chief Data Officers (CDOs) have done with data.
What You'll Read in This Blog Post:
- Limitations With Legacy Solutions
- Best Practices: A Data-Centric Design
- Use Case: A Very Simple Threat Detection Example With Dataiku and Elasticsearch
- Objective
- Our Input Data
- Creating a Set of Static Rules
- Applying Your Rules to Your Data
- Generating Your IOC Dataset
- Exposing Our Compromised IPs to Our SOC Analysts
- Benefits of a Data-Centric Solution for Threat Detection
- Next Steps: Scaling Further With Machine Learning and DataOps for Rules Management
Limitations With Legacy Solutions
Let’s start with the data. It can live anywhere — across different data warehouses, maybe it’s already in use and being processed by another business unit, or it simply exists on the internet, requiring you to develop your own in-house connectors and data pipelines.
Next, the data consumers and producers come into play. They may not have plain access to sensitive logs and still need valuable insights to enrich with their data model. They also may not be trained on the legacy solution being used or are more inclined to deploy large, open source frameworks such as Hadoop and Spark.
Eventually, the non-tech audience (in this case, security experts) will need to provide feedback to false positives. They are the valuable experts who will help organizations bootstrap their solutions quickly and are the source of truth to whether a system is robust and accurate or not.
Ideally, this very diverse population would work together on the same project, collaborating in the same platform, focusing on their unique areas of expertise. While this is not impossible, it does come with its own set of best practices.
Best Practices: A Data-Centric Design
A data-centric architecture makes it possible for a diverse range of stakeholders to collaborate on the same project, as illustrated in the visual below.
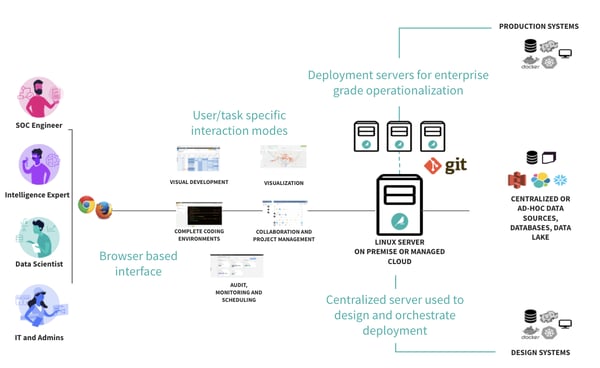
Dataiku DSS facilitates such deployment, as it provides built-in orchestration and data connection features that we will be using for our proof of concept.
In particular, the use of an orchestrator such as Dataiku DSS allows users to seamlessly source any kind of data (blog storage, SQL data warehouses, NoSQL databases, streaming, and so on), build machine learning pipelines, version with Git, and separate design from production.
We will now see how this approach can be beneficial with the example of a simple threat detection use case.
Use Case: A Very Simple Threat Detection Example With Dataiku and Elasticsearch
Objective
We have access to web proxy logs stored in Elasticsearch. The main goal is to detect a malware-infected machine via these web communications. To do this effectively, we will rely on the common web patterns that originate from those infected machines and apply detection rules to our data. We will eventually expose our results to analysts for deeper investigation.
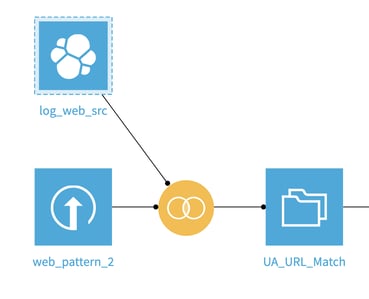
Our very simple flow in Dataiku DSS will look like this:
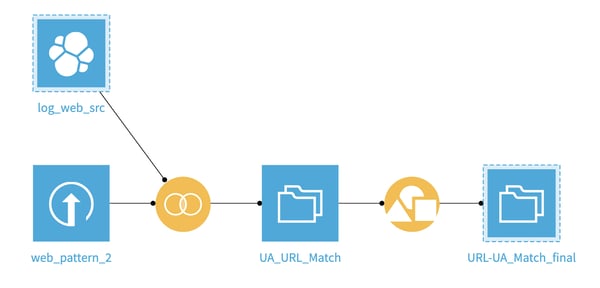
Our Input Data
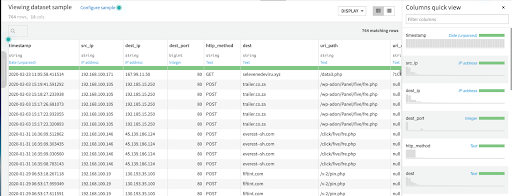
We source the data from Elasticsearch creating a dataset in Dataiku DSS. This data matches the logs of our web proxy. Logs contain harmless traffic but also connections to Command and Control Servers (C&Cs) from machines infected by different malware.

For the purpose of this example, we cleansed the data before to look more CIM-compliant, but it contains the following fields:
- Timestamp
- Src_ip
- Dest_ip
- Dest_port
- http_method
- Dest : server’s fqdn
- Uri_path
- Uri_query
- Url : concat of dest + Uri_path + Uri_query
- http_user_agent
- http_content_type : mime type
- http_referrer :
- status : http status code
- reason : http reason
Creating a Set of Static Rules
It is as simple as writing the rules in a .csv and uploading the file or, even better, creating an editable dataset in Dataiku DSS and writing them there. The dataset file will contain the different malware patterns that we want to cross-reference with the proxy logs.
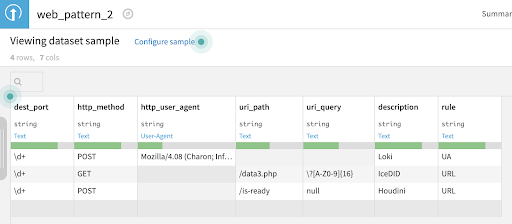
For example, the first line detects the Loki malware based on the User-Agent, the destination port, and the http method. The description and rule columns will enrich the dataset and make the detection more explicit.
Applying Your Rules to Your Data
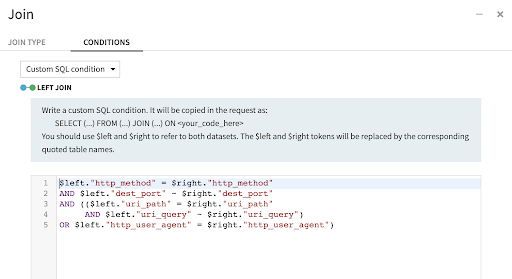
Matching rules to your data is as easy as joining the two datasets. Here, we will tell Dataiku DSS to join them based on a custom SQL condition and we will then filter the result of the query to keep only the lines that exhibit an actual match.
Everything happens in this single “join” recipe — the filter is added after the join is executed, as seen below:
Generating Your IOC Dataset
Now that our rules match our data, we will simply aggregate the data and count! We will create a “group by” recipe that will count the number of matches for each tuple (src_ip, url, dest_ip, status) and add the description and rule values from the pattern .csv file.
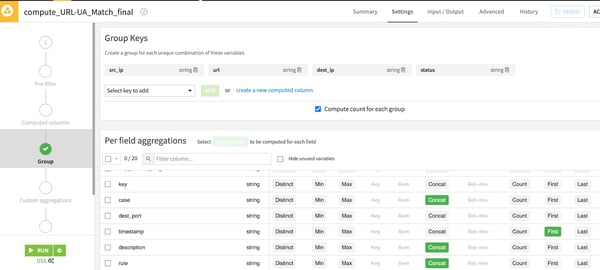
Then, we will add the “concat distinct” option to remove duplicates.

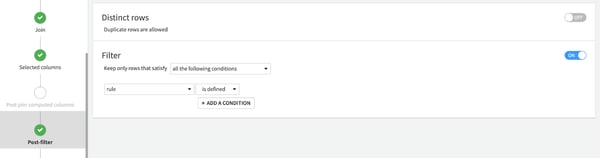
After that, we apply a filter to ensure the entries match more than 10 times (this is done in the post-filter section of the recipe). Note, more sophisticated techniques including ML scoring can be used here as well.
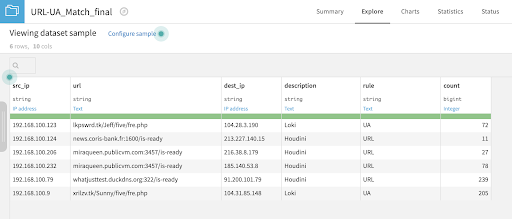
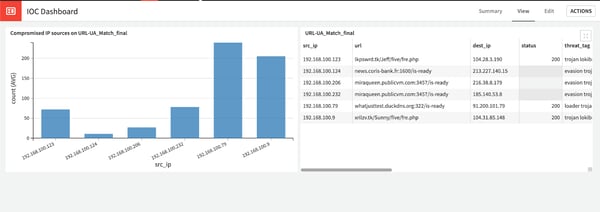
Our IOC dataset now looks like this:
Exposing Our Compromised IPs to Our Security Operations Center (SOC) Analysts
Next, we would like to display the data nicely to a security operations analyst — let’s create a dashboard for her in a few clicks, showing the compromised IP sources.
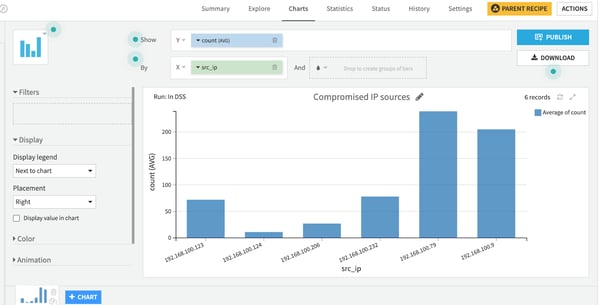
Then, we’ll publish it and voilà, the dashboard is ready!
Benefits of a Data-Centric Solution for Threat Detection
This simple use case illustrates great benefits to implementing threat detection on top of data-centric architectures, including:
- Some team members can focus on building pipelines while others can work on applying machine learning.
- Using “regular” SQL for rules matching makes it much more portable to other storage and backend options.
- There is no need to put all the data in a single storage location.
- Adding a rule is as simple as writing it directly in your dataset, you get the threat and the type without having to rely on multiple vertical solutions.
Next Steps: Scaling Further With Machine Learning and DataOps for Rules Management
We have seen how simple log ingestion can be processed to deliver quick insights valuable for a POC.
In a follow up to this post, we will see how we can go beyond static rules to enhance our solution with machine learning scoring and how we can iterate over our design to push it to production incrementally. In the meantime, feel free to send any comments, feedback, or suggestions to nicolas.pommier@dataiku.com.