{kind=link}
Collaborative data science has been a hot topic for many years. At Dataiku, we’ve been talking about it since our founding in 2013 (in fact, it was the impetus behind the creation of the Dataiku platform at the time). And right off the bat, let’s make one thing clear: It’s not that collaborative data science isn’t important — it’s a critical piece of the puzzle. It’s just that today, it’s not the whole picture.
But let’s take a step back. What does collaborative data science mean?
|
Boosting data science productivity and agility |
BUT where does that leave the rest of the organization (outside of the data science team or center of excellence) when it comes to their ability to be productive and agile with data? Enabling core data science teams will enable progress, but empowering masses is where the real potential for organizational change lies. |
|
Coordination across the entire data science workflow |
BUT what about workflows that fall outside the traditional raw data to modeling to insights process of data science? Collaborative data science leaves out other critical analytics processes, such as self-service analytics, traditional business intelligence (BI), overall governance frameworks, and more, which often happen outside data science workflows. |
|
Smoother processes between largely technical profiles like data scientists, engineers, etc. |
BUT AI is a team sport, and building a winning strategy involves more than just tech-first profiles — it must include analysts, subject matter experts from the business, front-line support and staff, decision makers, and more. |
While data science collaboration is a good starting point, organizations need to be able to build off it to achieve results. They need to ensure that AI is so deeply ingrained and intertwined with the workings of the day-to-day that it becomes part of the business, and isn’t just used or developed by one central team. In an article for Deloitte, MIT professor Thomas Malone reinforced this notion of collective intelligence when he says, "Almost everything we humans have ever done has been done not by lone individuals but by groups of people working together, often across time and space.”
Here, we’ll unpack five reasons why aiming to incorporate collaboration just at the data science level isn’t enough to succeed with data and AI at scale and include helpful ways that Dataiku goes beyond by making the use of data and AI everyday behavior for everyone.
Reason #1: Systemizing Is Table Stakes for Advancing AI Maturity
Systemizing the use of data and AI is about infusing it everywhere and among everyone, so that processes and technology are so deeply ingrained that every part of the organization thrives based on them. Organizations can’t achieve this level of breadth and depth in data, analytics, and AI processes or capabilities if they stop at collaborative data science.
In order to advance and accelerate AI maturity, organizations need to make sure people work together to maximize output, share knowledge, and leverage reuse and capitalization to avoid time-consuming rework in AI projects. Getting people to connect can and should be done directly within the tools every team working with data is using (which, hint, should be all of them) so workflows across teams are systemized organically over time.
A key part of systemization is AI augmentation, which is the concept of people and AI technology working in unison to drive performance (i.e., decision making capabilities). For example, in order to go from 10 to 1000s of models in production, systemization needs to include AI augmentation to, ultimately, empower more people to use AI.
In recent years, Dataiku has observed that analytics is a multi-persona, mature business process with well-known ROI, which is enticing to organizations who don’t already have a stake in the game. Many companies, though, feel overwhelmed and left behind when it comes to incorporating data and AI into the organization at large (and doing so in a way that elevates the work of every person across every department, profile, and geography).
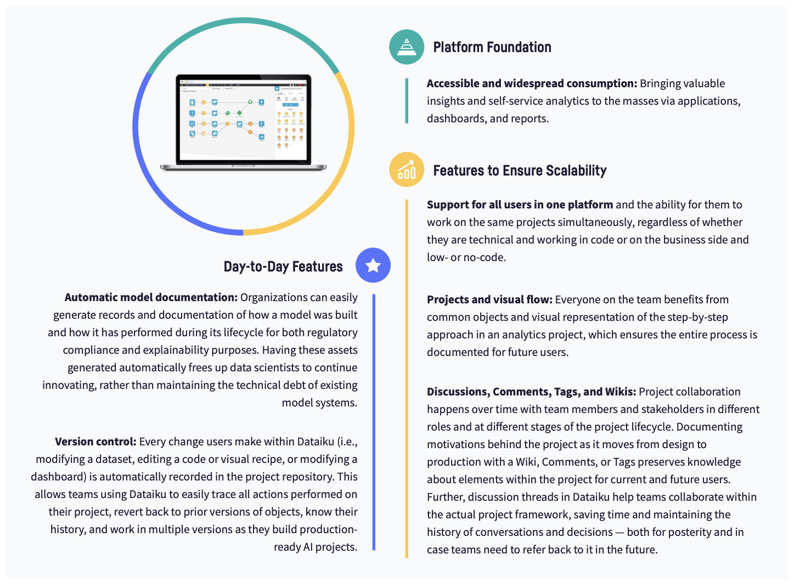
Dataiku helps to create a global implementation strategy where the best methods and tools are provided to teams, depending on their objectives and locations. Everything is integrated (i.e., security and roles, comments, project history, documentation) so organizations can use fewer tools, consolidating their analytics stack while simultaneously leveling up their collaboration capabilities with systemization.
Reason #2: Systemization Is More Than Just Integration With Collaboration Platforms
When looking at AI tools, it’s critical (and probably table stakes) for the potential platform to be able to integrate with all current technologies — think programming languages, Git for version control, machine learning (ML) model libraries that data scientists like to use, and data storage systems. It doesn’t stop there, though. The platform in question should be able to easily sync with other collaboration platforms like Slack and Microsoft Teams.
While this ensures team members and project stakeholders have access to the latest information and updates on design and production projects, it is still too narrow. Systemization warrants organizational alignment between data science teams and decision makers even before model development starts (i.e., Is the business problem realistic/feasible for the business experts and data scientists to solve together? Is there a clear path to value? What are the risks involved? How will the business implement changes to process or results measurement following the data project?).
By aligning on these questions before development begins, the data experts can build an approach that is robust and repeatable, gain executive buy-in (and, eventually, advocacy), and work with the business to ensure their model results are adopted and can start making a tangible impact. No amount of technology can take the place of tight business and tech coordination, ensuring that analytics groups have a seat at the table when the business is discussing their most pressing issues and working together to find solutions.
Reason #3: Systemization Is Not Something That Can Happen Ad Hoc
As alluded to earlier, systemization isn’t something that can just be infused during specific parts of the data science lifecycle or with certain teams. It can’t be done in silos or at random — it requires thoughtful alignment between data science and operations teams and the business from the get-go.
Systemization is an art that benefits businesses both large and small — it’s a way for everyone in a company to work together on data projects despite having different skills and expertise. Through systemization, each individual is able to capitalize on their strongest skills while benefiting from others’ complementary strengths and abilities. This guides each employee on a continuous path of professional development and, therefore, benefits every individual in the company.
If business stakeholders and technical teams are on the same page from the beginning with a plan and process, it will be much easier to guarantee that the project results are industrialized — not just once, but at scale and over time repeatedly. It’s much better to level-set on expectations from both parties before diving in, instead of having to backtrack and waste time once the project timeline has been started.

Reason #4: Collaboration Is Ever Evolving; Times Have Changed & Will Continue to
While there are several “fixed” elements of collaboration (i.e., stakeholder alignment, multi-persona involvement, documentation and versioning, knowledge sharing, reuse and reproducibility), what collaboration means now may not necessarily be the same thing it will mean in five years. Just as data science evolves and advances, so does collaboration.
A prime example of this evolution was during the global health crisis in 2020. Collaboration took on a renewed relevance and sense of urgency driven by:
- Remote work: More people are working from home and will continue to in the future. For teams that hadn’t worked remotely before, this created new challenges on how to make things efficient, aligned, and how to find a way to collaborate seriously (i.e., “quick meetings” to level-set became more difficult and the challenge shifted to keeping people productive, long term, in a remote work setting).
- Team reconfiguration: Many organizations had to get rid of consultants and contractors who were getting things done which quickly led to the realization that more documentation, processes, and formal collaboration were needed across teams.
Further, while data science collaboration by itself was at one time the end-all, be-all of data science initiatives, teams now have to go further to achieve full systemization.
Reason #5: Collaboration Isn’t a Nice-to-Have for AI Success, It’s a Need-to-Have
It’s pretty obvious that silos among teams — the antithesis of collaboration — implies productivity loss. Here are some examples of how dysfunctional collaboration (or lack of collaboration in general) manifests in practice:
- Too much time is spent on building communication material to make up for the lack of actual communication within and across teams. As a consequence, less time is spent on operations and business-impacting material.
- Too much time is spent in meetings, which naturally equates to less time for work and crossing things off the list.
- Team members need to duplicate work due to a lack of team-wide coordination and/or an inefficient use of time. Collaboration introduces the right people to each other, so, without it, the right people aren’t in the loop or involved early enough, which can make projects become inefficient.
- Significant amounts of time are spent looking for the right data or analytics asset (i.e., “Do you remember who did the last yearly analysis?”).
- With unclear roles and objectives, team members feel that they need clearer expectations and outlines of their responsibilities, otherwise it leads to demotivation and inadequate work (i.e., “Data cleansing was supposed to be your task.).
- There are gaps when projects are moved to production because there is no documentation or stakeholders from the business side.
- Inadequate execution against corporate governance or compliance practices stems from a lack of involvement by risk or other teams early on. This can lead to significant amounts of productivity lost due to the necessary rework after the fact or, worse, failure of the project entirely if the project’s premise turns out to be outside of operational or regulatory risk tolerance or constraints.
Cross-functional collaboration can be used to mitigate or wholly eliminate all of these issues and, therefore, is a prerequisite for AI success. As data science, ML, and AI adoption continue to rise and competition continues to intensify, companies will continue to take on higher-value projects and will need that common thread of collaboration to be clear throughout each and every one of them if they expect to actually scale their data efforts across the business.
Dataiku Is the Only Platform That Systemizes the Use of Data and AI
Dataiku is the platform for Everyday AI, enabling data experts and domain experts to work together to build data into their daily operations, from advanced analytics to Generative AI. Together, they design, develop and deploy new AI capabilities, at all scales and in all industries.
Dataiku is unique because it enables systemization through horizontal workstreams (people working together with others who have roughly the same skills, toolsets, training, and day-to-day responsibilities) as well as vertical workstreams (people working across different teams) with ease through a complete suite of features that enables communication and allow both technical and non-technical staff to work with data their way.
Dataiku makes data and AI projects a team sport, bringing intelligence to all, through: