





Whether we’re talking about data analysts running reports, data scientists developing models, or IT professionals trying to understand the data landscape, one of the biggest challenges that data practitioners face is the sheer volume of data that is available to them. In many organizations, data is stored in multiple systems and formats, making it difficult to find the right data for their analysis. On top of that, the data may be scattered across different departments, making it hard to know who to approach for access to the data.
Data professionals want to be confident that the data they are analyzing and using is accurate, reliable, and trustworthy. However, without proper metadata and data governance, it can be difficult to assess the quality of the data. Additionally, data analysts may have limited knowledge of the data's source, lineage, and structure, making it hard to understand its context and relevance to their analysis.
Finally, once data analysts or data scientists have identified the relevant data, they often face the challenge of importing and integrating the data into their analytics environment. This can be a time-consuming and error-prone process, particularly when dealing with large volumes of data or complex data structures.
All of these challenges can lead to delays and inefficiencies in the analytics process, and can eventually impact the organization's ability to make timely and informed decisions. In the following paragraphs, we will delve into the data discovery capabilities offered by Dataiku, looking into features that facilitate efficient data exploration. We will also focus on the significance of data quality metrics and checks within Dataiku's framework, shedding light on how these tools contribute to ensuring the accuracy and reliability of data. Finally, this post dives into the potential benefits of integrating Dataiku with external data governance solutions, emphasizing the platform's adaptability and its role in enhancing data management strategies.
Dataiku Catalog for Easy Discovery and Collaboration
The Dataiku catalog is a centralized repository that enables organizations to discover, understand, and collaborate on their data assets. A data catalog is essential in analytics as it helps data analysts, data scientists, data engineers, and others to find the right data for their analyses quickly and easily.
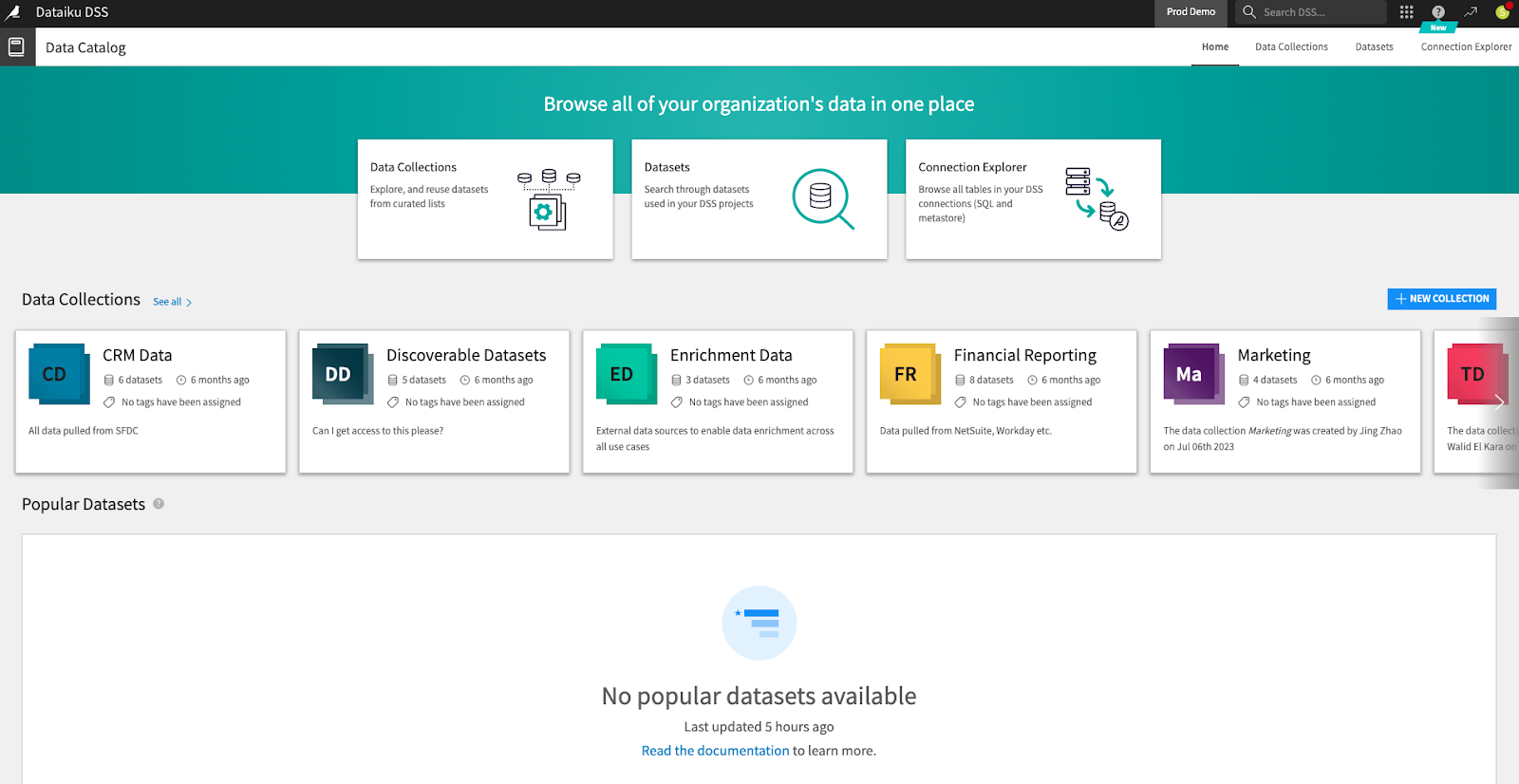
The Dataiku catalog provides several key features that helps manage data assets, including:
- Data discovery: The catalog enables searching and browsing all data assets within an organization, including databases, data warehouses, and file systems. Data scientists or data analysts can quickly find the data they need. Additionally, data engineers get insights into how data is used in data pipelines (called flows, in Dataiku) for every project.
- Data profiling and quality assessment: Dataiku provides extensive data profiling and quality assessment capabilities that enable data analysts or data scientists, for example, to assess the quality of their data before using it in their reports or models. Dataiku generates data quality metrics, such as completeness, accuracy, and consistency.
- Collaboration and socialization: The catalog provides collaboration and socialization capabilities that enable data practitioners to share knowledge and insights about the data assets. Users can comment on data assets, and share insights with their colleagues.
By providing a centralized view of all data assets, the catalog enables all data professionals to find the data they need quickly and easily, reducing the time and effort required to locate, analyze and prepare data. The catalog enables self-service analytics by providing an interface where users can find the data they need without requiring assistance from IT teams, for example.
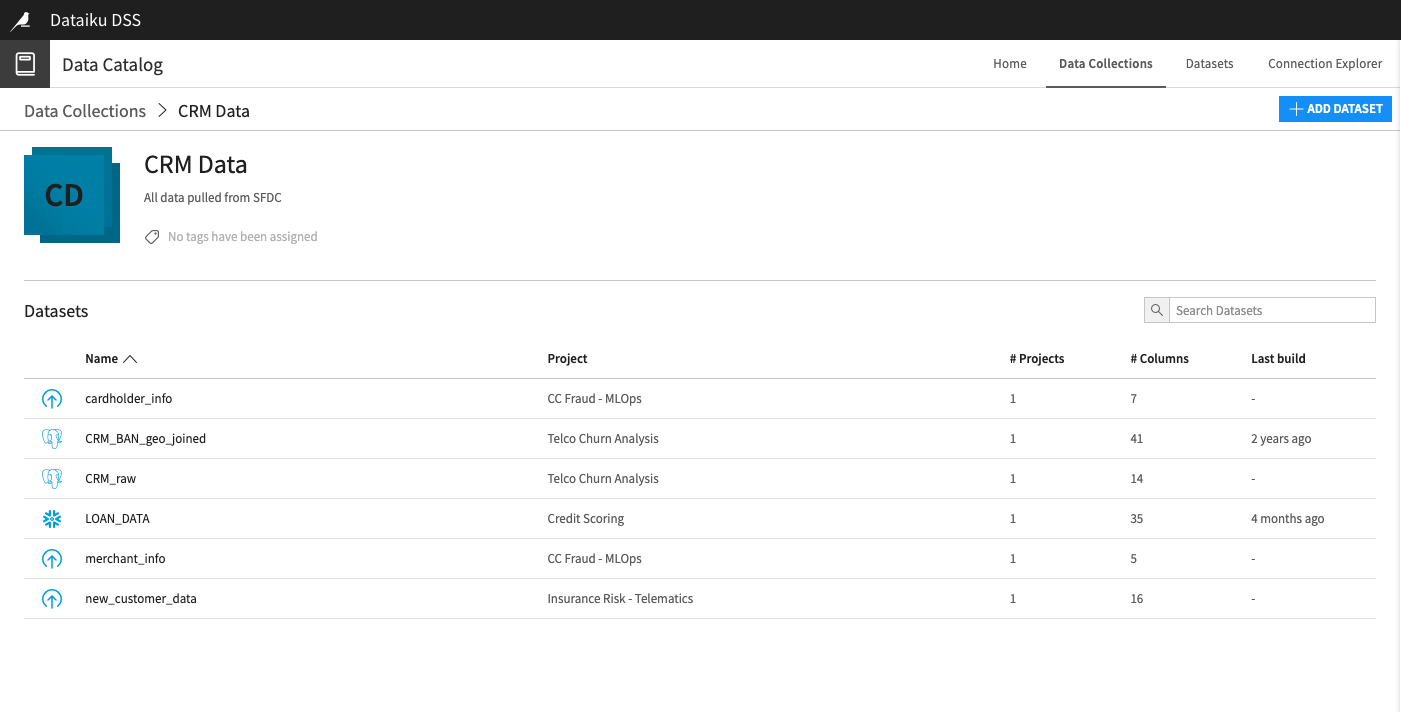
Data Collections in the Dataiku catalog provide data practitioners with access to curated clusters of datasets to explore and extract valuable information for integration into their analytics projects. By selecting any dataset within a collection, you can delve into its details, status, and schema. This interface further empowers you to perform various actions such as exploration, publication, exportation, observation, favoriting, and content preview, offering a suite of tools for efficient data utilization and management within the Dataiku platform.
Dataiku also provides a variety of checks and metrics that allow data analysts and engineers to monitor the quality and performance of their data pipelines. Data profiling metrics offer insights into various aspects of data, including missing values, data duplicates, data outliers, and statistical measures and Dataiku dynamically suggests fixes when invalid records are detected. Specific data quality checks can then be set up to monitor completeness, correctness, and consistency of their datasets.
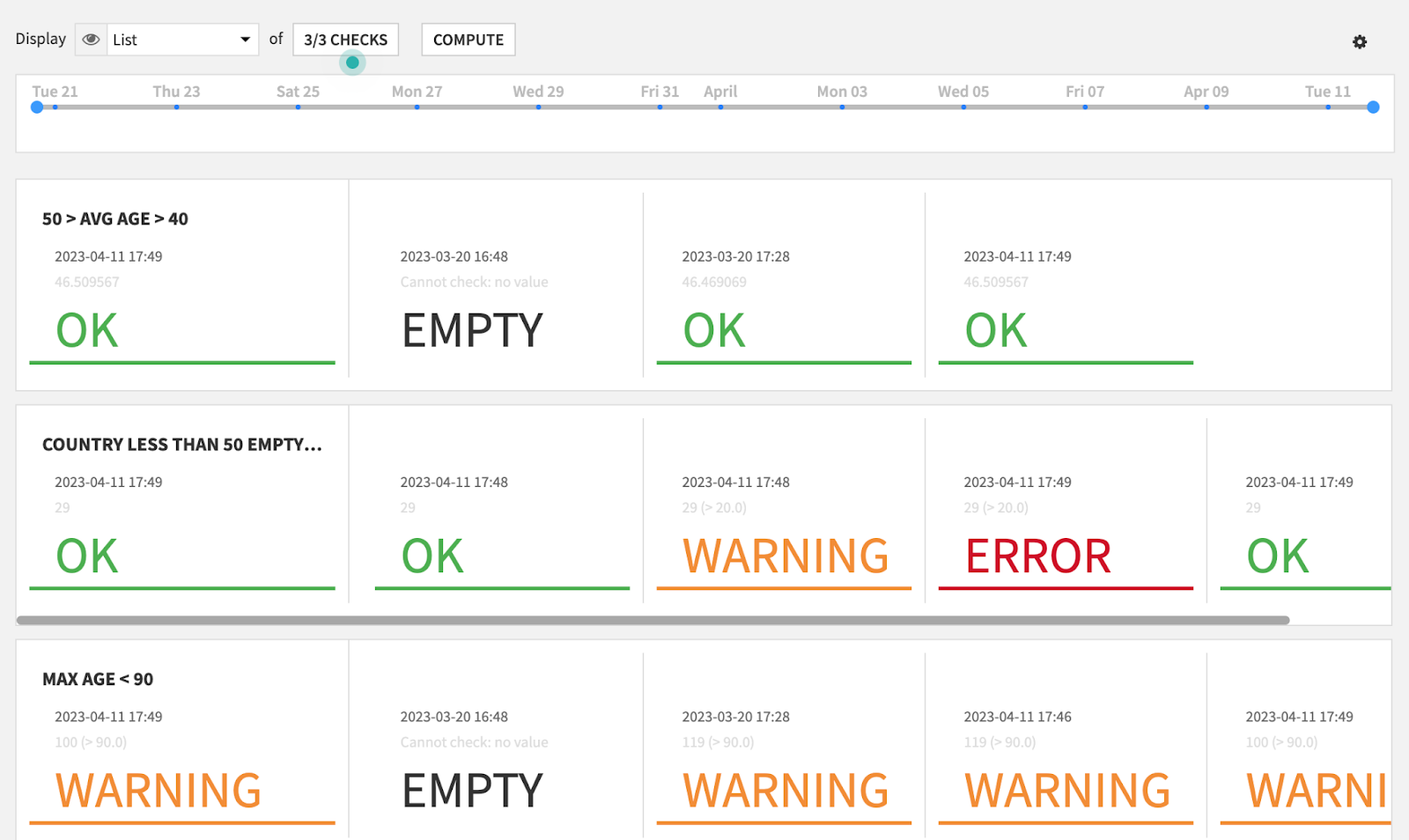
Users can also monitor the performance of data preparation processes with metrics such as processing time, row counts, and error rates.
The Case for Integrating With Specialized Data Governance Platforms
Even though Dataiku offers powerful features to support data discovery, there’s a case to be made for the integration with specialized vendors in the data management space, like Collibra or Alation.
For data to be used strategically across the organization, it must be compliant with internal and external policies, clean, and accessible through formal procedures and accountability. The goals of data governance are to establish the methods, processes, and responsibilities that enable organizations to ensure data quality, compliance, usability, and accessibility.
All the points mentioned previously are crucial for the democratization of data science and machine learning (ML) because organization-wide trust in data is essential. Just as the average consumer would not use products from retailers they do not trust, business stakeholders and data experts will be hesitant in using data (or insights derived from this data) for decision-making if they do not trust it.
The most successful businesses are the ones who can effectively manage data as a trusted asset and are able to marry the best data science capabilities with the best data quality.
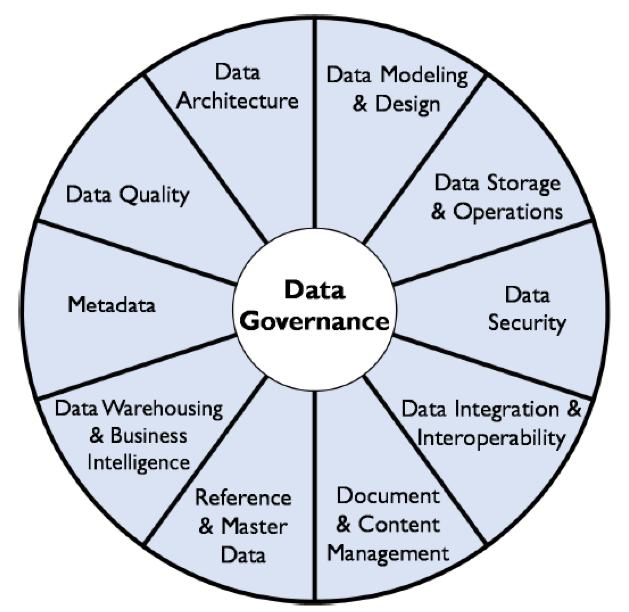
The 3 Main Pillars of Data Governance
The main pillars of data governance are people, processes, and technology. Each pillar can be implemented and connected through a specialized platform and contributes to a framework of how organizations can get a better handle on their data.
People: The people pillar of data governance refers to the individuals responsible for managing and using data within an organization. This includes data stewards, data owners, and data custodians who are responsible for ensuring that data is properly managed, secured, and used. It also includes senior leadership who provide guidance and oversight for data governance initiatives.
Processes: The processes pillar of data governance refers to the procedures, policies, and workflows that govern how data is managed within an organization. This includes policies for data quality, data security, data privacy, data integration, and overall data lifecycle management. It also includes procedures for data governance activities such as data classification (for data privacy or contextualization, for example), data lineage, data stewardship, and data auditing.
Technology: The technology pillar of data governance refers to the tools and systems used to manage and store data within an organization.
A properly implemented governance framework can bring numerous benefits to organizations. Especially those who are trying to scale their data science activities.
It helps organizations develop a common language around data. This common language is typically implemented through a business glossary which includes definitions for key terms and concepts related to the organization's business operations, as well as data-related terms such as data elements, datasets, and data models. It creates terminology and data context that is easily used and understood by anyone across the organization.
This context, combined with properly implemented data quality processes promotes greater trust and overall usage of data. Another key objective of data governance is to promote the reuse of data through standardization. Standardization involves defining and adhering to consistent data definitions, formats, and structures across an organization. This helps to ensure that data is consistent, accurate, and of high quality, and can be effectively shared and reused across different departments and teams.
A strong data governance program also ensures that organizations remain compliant with regulations (like CCPA, GDPR, HIPAA, etc.) around how to properly manage the privacy and confidentiality of personal data.
Conclusion
The ultimate goal is to provide a single pane of glass where business or technical stakeholders can find the data they need, and trust that it is usable for their data science projects. This improved trust, combined with Dataiku’s end-to-end connectivity, data preparation, ML, and MLOps capabilities provides massive benefits to organizations trying to bring value through data.
By democratizing data access, breaking down silos, and providing a secure and governed way to manage data, Dataiku helps organizations to make better data-driven decisions, optimize their operations, and gain a competitive advantage.