




The market for manga is huge — about 2 billion manga are sold every year. By definition, manga originates from Japan; however, it’s also one of the fastest-growing areas of comic books and narrative fiction in other parts of the world. Wouldn’t an automated manga translator come in handy for this flourishing network of fans?!
Unfortunately for non-Japanese reading manga lovers like me, they take time to be translated from Japanese and made available elsewhere in the world. I have more than once wished there was an easier way of getting the rough meaning of a manga than typing every sentence by hand and feeding it to an online translator. In fact, when I started the project, I wondered why there was no open source framework that already existed for this purpose.
That’s why, for my internship in the R&D Ecosystem team at Dataiku, I chose to work on making an automated manga translator with Dataiku DSS. This blog post unpacks the challenges I encountered with this project, the work I was able to do in just two months, plus key learnings and takeaways that can be interesting for others working on similar projects.
Ultimately, the tool I developed would be most useful as a helper for human translators. They would just have to verify and correct the translations on a dataset that contains both the Japanese text and its translation proposal.
Manga Character Recognition
One of the earliest choices I had to make with this project was which Optical Character Recognition (OCR) engine I would use. I settled on Tesseract because:
- It is arguably the best-performing open source OCR engine solution.
- It is quite stable and maintained by Google.
- It is available a plugin for Dataiku DSS.
I first tested it with default settings on a raw manga, and I quickly understood why I hadn’t found a working translator on GitHub. As you can see below, half of the bubbles were not even detected!
.png?width=247&name=pasted%20image%200%20(2).png)
Manga Source: Tomo-chan wa Onnanoko! by Fumita Yanagida
I was not prepared to recreate a whole OCR model in a two-month internship, so I realized that my work was going to be about making life easy for Tesseract. The usual suspect for OCR failures is the image quality, so that’s where I started looking. I built myself a little interface in order to monitor the changes and play with filters:
.png?width=600&name=pasted%20image%200%20(3).png)
However, even using multiple image enhancement functions from Pillow and OpenCV, some blocks of text could still not be detected. That's when I found out about a nifty option in Tesseract called “Detect paragraphs,” which changed everything. With this option, all the text could now be detected! Then, another challenge appeared: instead of feeding an entire manga page to Tesseract, I would now need to feed it with text blocks.
Onto the Next Challenge: Text Segmentation
My first idea was to detect the bubbles with their characteristic shape, but I had forgotten how creative mangaka can get when it comes to surrounding dialogues:
.png?width=1600&name=pasted%20image%200%20(4).png) After some research I found this open source project, which tackled this specific issue with OpenCV. Instead of looking for bubbles, it looks for the “grid” pattern of text blocks, which are always typed in the same font. At last, the results were quite good with only a few failures, as you can see below:
After some research I found this open source project, which tackled this specific issue with OpenCV. Instead of looking for bubbles, it looks for the “grid” pattern of text blocks, which are always typed in the same font. At last, the results were quite good with only a few failures, as you can see below:
.png?width=242&name=pasted%20image%200%20(5).png) With text blocks detected, I just had to put the cropped images of each block through the Tesseract OCR plugin, et voilà — I got the text and its location. Here’s what the results look like in Dataiku DSS:
With text blocks detected, I just had to put the cropped images of each block through the Tesseract OCR plugin, et voilà — I got the text and its location. Here’s what the results look like in Dataiku DSS:
.png?width=384&name=pasted%20image%200%20(6).png)
From Blocks to Bubbles
Next, the issue was to find the real bubble that went with the text blocks. The reason is twofold:
- There can be multiple text blocks within the same bubble — separating them would not make sense for the translator, as they share the same context.
- Japanese text blocks are very narrow because they are written vertically — this is a problem when trying to replace them with their English translations, which are much wider. Using the full size of the bubble when pasting the English text is much more aesthetically pleasing.
In order to find those bubbles, I decided to take advantage of the fact that bubbles are white zones. Using the Python library scikit-image, I could increase the width of each stroke to make large zones of color more distinct and then find connected components within the image.
.png?width=1600&name=pasted%20image%200%20(7).png) Manga Source: Yotsuba to ! by Kiyohiko Azuma
Manga Source: Yotsuba to ! by Kiyohiko Azuma
As you can see in the middle image, I filtered all the connected components, keeping only those that closely surrounded a text block. This method works also for spotting the text that isn’t detected by the previous step but that is easy to distinguish from the rest of the image. Finally, I inverted the color again to spot black text and applied some filtering and clustering to compute bounding boxes for my bubbles.
Final Arc: Translation
After having identified both text blocks and bubbles (which have been “tesseracted”), it’s time for translation — another difficulty. The code itself isn’t problematic since it’s either about loading a model or calling an API. But words are often alluded to in Japanese (especially pronouns), and in mangas, a lot of the context (like the gender of the narrator) is visual. In addition, manga Japanese with its particular grammar and slang is very different from the Japanese on which most models are trained. All of this made some translations... invariably weird.
.png?width=1422&name=pasted%20image%200%20(8).png)
In the end, I implemented both an open-source solution (HuggingFace Helsinki model) and a paid one (DeepL), but I think the only way to get really good results would be to train a custom translation model for manga. That would be really difficult, but it has already been done on specific series.
Conclusion: Key Learnings and Takeaways
I haven’t been coding for long, and this project was my first time working with black-box algorithms such as Tesseract and translation models. This proved to be a real struggle since I had to try and accommodate them without really understanding how they worked.
The second problem I had to overcome was how to organize and debug each step of my development. Dataiku DSS helped a lot by allowing me to visualize my entire pipeline as a flow:
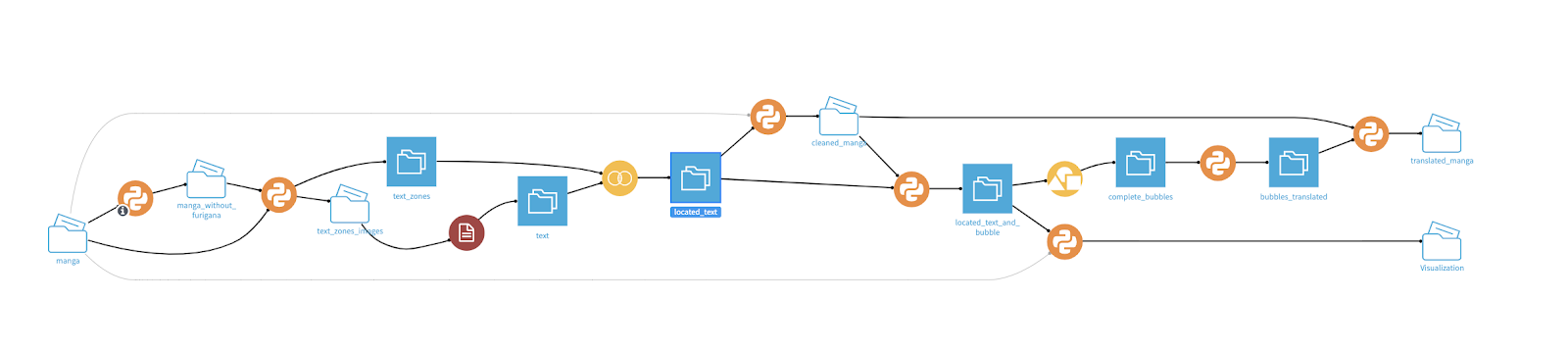
{kind=link}
If I were to take on another project with such a prominent image manipulation aspect, I would build myself utilities much earlier than I did. Being able to work in notebooks within Dataiku DSS was a real blessing. In addition, the packaging of Tesseract into a plugin allowed me to try different options easily using a simple GUI, which saved me a huge amount of time.
This project was an amazing opportunity because it was both fun and difficult. I was really motivated by the idea of building a tool I wanted for myself and happy that it led me to work with image processing. I would probably not have tried learning about it by myself (and I would have missed out on the lessons it taught me!).
With a pipeline this intricate, I had to improve my code organization skills and take advantage of all the help Dataiku DSS gave me. In addition, I had to go through the whole process of learning to use libraries whose usage is not necessarily well documented, which is a great learning-by-doing opportunity.